diff --git a/.editorconfig b/.editorconfig
new file mode 100644
index 0000000..18a6d25
--- /dev/null
+++ b/.editorconfig
@@ -0,0 +1,64 @@
+# EditorConfig is awesome: https://EditorConfig.org
+
+# top-most EditorConfig file
+root = true
+
+# Default settings for all files
+[*]
+charset = utf-8
+end_of_line = lf
+insert_final_newline = true
+trim_trailing_whitespace = true
+indent_style = space
+indent_size = 2
+
+# Markdown files
+[*.{md,markdown}]
+trim_trailing_whitespace = false # Trailing whitespace is significant in Markdown
+
+# Python files
+[*.py]
+indent_size = 4
+max_line_length = 88 # Black formatter default
+
+# C# files
+[*.cs]
+indent_size = 4
+csharp_new_line_before_open_brace = all
+csharp_space_between_method_declaration_parameter_list_parentheses = false
+csharp_space_between_method_call_parameter_list_parentheses = false
+csharp_space_after_keywords_in_control_flow_statements = true
+csharp_space_between_parentheses = false
+
+# JavaScript/TypeScript files
+[*.{js,ts,jsx,tsx}]
+quote_type = single
+
+# JSON files
+[*.json]
+insert_final_newline = false
+
+# YAML files
+[*.{yml,yaml}]
+indent_size = 2
+
+# Shell scripts
+[*.sh]
+indent_size = 2
+
+# HTML, CSS, SCSS files
+[*.{html,css,scss}]
+indent_size = 2
+
+# Java files
+[*.java]
+indent_size = 4
+
+# Go files
+[*.go]
+indent_style = tab
+indent_size = 4
+
+# Makefiles
+[Makefile]
+indent_style = tab
diff --git a/.github/ISSUE_TEMPLATE/bug_report.md b/.github/ISSUE_TEMPLATE/bug_report.md
new file mode 100644
index 0000000..3b6828a
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/bug_report.md
@@ -0,0 +1,30 @@
+---
+name: Bug report
+about: Create a report to help us improve
+title: '[BUG] '
+labels: 'bug'
+assignees: ''
+
+---
+
+**Describe the bug**
+A clear and concise description of what the bug is.
+
+**To Reproduce**
+Steps to reproduce the behavior:
+1. Go to '...'
+2. Click on '....'
+3. Scroll down to '....'
+4. See error
+
+**Expected behavior**
+A clear and concise description of what you expected to happen.
+
+**Screenshots**
+If applicable, add screenshots to help explain your problem.
+
+**Additional context**
+Add any other context about the problem here.
+
+**Possible solution**
+If you have suggestions on how to fix the issue, please describe them here.
\ No newline at end of file
diff --git a/.github/ISSUE_TEMPLATE/bug_report_vi.md b/.github/ISSUE_TEMPLATE/bug_report_vi.md
new file mode 100644
index 0000000..1b16943
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/bug_report_vi.md
@@ -0,0 +1,30 @@
+---
+name: Báo cáo lỗi
+about: Tạo một báo cáo lỗi để giúp chúng tôi cải thiện
+title: '[BUG] '
+labels: 'bug'
+assignees: ''
+
+---
+
+**Mô tả lỗi**
+Mô tả ngắn gọn và rõ ràng về lỗi đang gặp phải.
+
+**Cách để tái tạo lỗi**
+Các bước để tái hiện hành vi lỗi:
+1. Truy cập vào '...'
+2. Nhấn vào '...'
+3. Cuộn xuống tới '...'
+4. Thấy lỗi
+
+**Hành vi mong đợi**
+Mô tả rõ ràng và ngắn gọn về điều bạn mong đợi sẽ xảy ra.
+
+**Ảnh chụp màn hình**
+Nếu có, hãy thêm ảnh chụp màn hình để minh họa lỗi.
+
+**Ngữ cảnh bổ sung**
+Thêm bất kỳ thông tin bổ sung nào về sự cố ở đây (thiết bị, trình duyệt, môi trường...).
+
+**Giải pháp khả thi**
+Nếu bạn có gợi ý về cách khắc phục lỗi, vui lòng mô tả tại đây.
diff --git a/.github/ISSUE_TEMPLATE/feature_request.md b/.github/ISSUE_TEMPLATE/feature_request.md
new file mode 100644
index 0000000..59b656f
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/feature_request.md
@@ -0,0 +1,23 @@
+---
+name: Feature request
+about: Suggest an idea for this project
+title: '[FEATURE] '
+labels: 'enhancement'
+assignees: ''
+
+---
+
+**Is your feature request related to a problem? Please describe.**
+A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
+
+**Describe the solution you'd like**
+A clear and concise description of what you want to happen.
+
+**Describe alternatives you've considered**
+A clear and concise description of any alternative solutions or features you've considered.
+
+**Additional context**
+Add any other context or screenshots about the feature request here.
+
+**Target topics/areas**
+Which topics or sections of the repository would be affected by this feature?
\ No newline at end of file
diff --git a/.github/ISSUE_TEMPLATE/feature_request_vi.md b/.github/ISSUE_TEMPLATE/feature_request_vi.md
new file mode 100644
index 0000000..003b8c0
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/feature_request_vi.md
@@ -0,0 +1,23 @@
+---
+name: Yêu cầu tính năng
+about: Đề xuất một ý tưởng hoặc tính năng cho dự án
+title: '[FEATURE] '
+labels: 'enhancement'
+assignees: ''
+
+---
+
+**Yêu cầu tính năng này có liên quan đến vấn đề nào không? Hãy mô tả.**
+Mô tả rõ ràng và ngắn gọn về vấn đề. Ví dụ: Tôi thường cảm thấy khó chịu khi [...]
+
+**Mô tả giải pháp bạn muốn có**
+Mô tả rõ ràng và ngắn gọn về điều bạn muốn xảy ra.
+
+**Mô tả các giải pháp thay thế bạn đã xem xét**
+Mô tả rõ ràng và ngắn gọn về bất kỳ giải pháp thay thế hoặc tính năng khác mà bạn đã cân nhắc.
+
+**Ngữ cảnh bổ sung**
+Thêm bất kỳ thông tin, bối cảnh hoặc ảnh chụp màn hình nào liên quan đến yêu cầu tính năng ở đây.
+
+**Các chủ đề/khu vực bị ảnh hưởng**
+Những chủ đề hoặc phần nào trong repository sẽ bị ảnh hưởng bởi tính năng này?
diff --git a/.github/workflows/ci.yml b/.github/workflows/ci.yml
new file mode 100644
index 0000000..75e1465
--- /dev/null
+++ b/.github/workflows/ci.yml
@@ -0,0 +1,29 @@
+name: Markdown CI
+
+on:
+ push:
+ branches: [ main ]
+ pull_request:
+ branches: [ main ]
+
+jobs:
+ check-links:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+
+ - name: Setup Node.js
+ uses: actions/setup-node@v3
+ with:
+ node-version: '16'
+
+ - name: Install dependencies
+ run: npm install -g markdown-link-check
+
+ - name: Check links
+ run: ./tools/check_links.sh
+
+ - name: Generate TOC
+ run: |
+ python3 ./tools/generate_summary.py
+ git diff --exit-code SUMMARY.md || (echo "SUMMARY.md is out of date. Please run ./tools/generate_summary.py and commit the changes" && exit 1)
\ No newline at end of file
diff --git a/.gitignore b/.gitignore
index 69d6106..df28da4 100644
--- a/.gitignore
+++ b/.gitignore
@@ -3,11 +3,34 @@ node_modules/
# Python
__pycache__/
-*.pyc
-*.pyo
-*.pyd
-.env
-.venv/
+*.py[cod]
+*$py.class
+*.so
+.Python
+env/
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+*.egg-info/
+.installed.cfg
+*.egg
+
+# C#
+bin/
+obj/
+*.user
+*.suo
+*.userprefs
+*.sln.docstates
+.vs/
# VSCode settings
.vscode/
@@ -42,6 +65,8 @@ coverage.xml
# dotenv environment files
.env.local
.env.*
+.env
+!.env.example
# Ignore generated files and backups
*.orig
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 623f533..13e1ccd 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -1,6 +1,6 @@
# Contributing to Tech Notes Hub
-First of all, thank you for taking the time to contribute! 🎉
+First of all, thank you for taking the time to contribute! 🎉
Your contributions help make this project more valuable for the developer community.
## 🚀 Ways to Contribute
@@ -74,6 +74,7 @@ Write clear, meaningful, and understandable commit messages. Suggested structure
- `feature: add notes on HTTP Status Codes`
- `fix: correct typos in design-patterns.md`
- `update: improve binary search examples`
+- `refactor: reorganize folder structure`
- `remove: delete duplicate notes in aws folder`
- `docs: add instructions for creating pull requests`
@@ -81,7 +82,7 @@ Write clear, meaningful, and understandable commit messages. Suggested structure
- You can only write in **English**
- **Avoid vague commits** like: `update 1`, `fix bug`, `test`
-- If related to an issue, add the number at the end:
+- If related to an issue, add the number at the end:
👉 `fix: typo in aws-note #12`
### 5. Commit & Push
@@ -111,9 +112,9 @@ Before submitting, ensure:
## 📁 File & Folder Naming Conventions
-* Use lowercase and hyphens for file and folder names: `graph-traversal.md`
-* For translations, add language suffix: `graph-traversal_vi.md`
-* Notes should be grouped by topic folders (e.g., `algorithms/`, `aws/`, `design-patterns/`)
+* Use lowercase and hyphens for file and folder names: `graph_traversal.md` (except for code files like C# using PascalCase such as `GraphTraversal.cs`, or Java using CamelCase like `GraphTraversal.java`)
+* For translations, add language suffix: `graph_traversal_vi.md`
+* Notes should be grouped by docs folders (e.g., `docs/algorithms/`, `docs/aws/`, `docs/design-patterns/`)
## 🤝 Code of Conduct
diff --git a/CONTRIBUTING_vi.md b/CONTRIBUTING_vi.md
index cb03727..11991dd 100644
--- a/CONTRIBUTING_vi.md
+++ b/CONTRIBUTING_vi.md
@@ -1,6 +1,6 @@
# Đóng góp vào Tech Notes Hub
-Trước hết, xin chân thành cảm ơn bạn đã dành thời gian đóng góp! 🎉
+Trước hết, xin chân thành cảm ơn bạn đã dành thời gian đóng góp! 🎉
Sự đóng góp của bạn giúp dự án này trở nên hữu ích hơn cho cộng đồng lập trình viên.
## 🚀 Cách bạn có thể đóng góp
@@ -74,6 +74,7 @@ Viết commit rõ ràng, có ý nghĩa và dễ hiểu. Cấu trúc đề xuất
- `feature: add notes on HTTP Status Codes`
- `fix: correct typos in design-patterns.md`
- `update: improve binary search examples`
+- `refactor: reorganize folder structure`
- `remove: delete duplicate notes in aws folder`
- `docs: add instructions for creating pull requests`
@@ -81,7 +82,7 @@ Viết commit rõ ràng, có ý nghĩa và dễ hiểu. Cấu trúc đề xuất
- Bạn chỉ có thể viết bằng **tiếng Anh**
- **Tránh commit mơ hồ** như: `update 1`, `fix bug`, `test`
-- Nếu liên quan issue, thêm số vào cuối:
+- Nếu liên quan issue, thêm số vào cuối:
👉 `fix: typo in aws-note #12`
@@ -112,9 +113,9 @@ Trước khi gửi, hãy đảm bảo:
## 📁 Quy tắc đặt tên file & thư mục
-* Tên file và thư mục dùng chữ thường và dấu gạch ngang: `graph-traversal.md`
-* Nếu là bản dịch, thêm hậu tố ngôn ngữ: `graph-traversal_vi.md`
-* Ghi chú nên được nhóm theo thư mục chuyên đề (ví dụ: `algorithms/`, `aws/`, `design-patterns/`)
+* Tên file và thư mục dùng chữ thường và dấu gạch ngang: `graph_traversal.md` (trừ code như C# sử dụng PascalCase như `GraphTraversal.cs`, hoặc Java sử dụng CamelCase như `GraphTraversal.java`)
+* Nếu là bản dịch, thêm hậu tố ngôn ngữ: `graph_traversal_vi.md`
+* Ghi chú nên được nhóm theo thư mục trong docs (ví dụ: `docs/algorithms/`, `docs/aws/`, `docs/design-patterns/`)
## 🤝 Quy tắc ứng xử
diff --git a/PULL_REQUEST_RULES.md b/PULL_REQUEST_RULES.md
index 3a3793d..b25ef90 100644
--- a/PULL_REQUEST_RULES.md
+++ b/PULL_REQUEST_RULES.md
@@ -6,6 +6,36 @@ Please read carefully before submitting a PR.
---
+## 📝 Pull Request Template
+
+When submitting a pull request, please include:
+
+### Description
+A clear description of the changes you have made.
+
+### Related Issue
+Link to any related issues: `Fixes #(issue number)`
+
+### Type of Change
+Select the appropriate options:
+- [ ] New content (notes, snippets)
+- [ ] Content improvement (updates, fixes, expansion)
+- [ ] Documentation update
+- [ ] Bug fix (non-breaking change which fixes an issue)
+- [ ] Infrastructure/tooling (CI, scripts, etc.)
+- [ ] Translation (i18n) - specify language: ______
+- [ ] Other (please describe)
+
+### Checklist
+- [ ] My content follows the style guidelines of this project
+- [ ] I have performed a self-review of my own content/code
+- [ ] I have included references/links where appropriate
+- [ ] My changes generate no new warnings or errors
+- [ ] I have checked that all links are valid
+- [ ] For translations: I've followed the i18n folder structure (i18n/[language_code]/...)
+
+---
+
## ✅ Allowed in Pull Requests
- **New content** such as:
@@ -22,8 +52,9 @@ Please read carefully before submitting a PR.
- Typo and grammar fixes
- Markdown formatting or link corrections
- **New language versions**:
- - Translations with `_vi.md`, `_fr.md`, etc. suffix
+ - Translations in the `i18n/[language_code]/` folder structure (e.g., `i18n/vi/`, `i18n/fr/`)
- Must match the structure and logic of the original file
+ - Should be referenced in the SUMMARY.md under appropriate language section
## ❌ Not Allowed in Pull Requests
@@ -34,19 +65,21 @@ Please read carefully before submitting a PR.
- ❌ Personal promotion, affiliate links, or ads
- ❌ Files with broken structure, invalid markdown, or irrelevant naming
- ❌ Notes that contain **plagiarized content** (copying from copyrighted materials)
+- ❌ Translations not following the proper i18n folder structure
## 🔖 Style & Structure Reminders
- Use clear, **conversational but concise** explanations
- Use correct heading hierarchy (`#`, `##`, `###`, etc.)
- Name files using lowercase and hyphens: `binary-search.md`
-- For translated files, append language suffix: `binary-search_vi.md`
- Place content in the appropriate folder (`algorithms/`, `design-patterns/`, etc.)
+- For translations, use the `i18n/[language_code]/` structure, mirroring the main docs structure
+- Update SUMMARY.md to include new content or translations
## 📢 Final Note
-We appreciate your contribution and effort!
-All pull requests will be reviewed by maintainers before merging.
+We appreciate your contribution and effort!
+All pull requests will be reviewed by maintainers before merging.
Feel free to open a discussion issue if you're unsure whether something fits.
-Let’s build a high-quality, developer-friendly knowledge base together. 🚀
+Let's build a high-quality, developer-friendly knowledge base together. 🚀
diff --git a/PULL_REQUEST_RULES_vi.md b/PULL_REQUEST_RULES_vi.md
index 58b9022..a8d0fec 100644
--- a/PULL_REQUEST_RULES_vi.md
+++ b/PULL_REQUEST_RULES_vi.md
@@ -6,6 +6,36 @@ Vui lòng đọc kỹ trước khi gửi PR.
---
+## 📝 Mẫu Pull Request
+
+Khi gửi pull request, vui lòng bao gồm:
+
+### Mô tả
+Mô tả rõ ràng về các thay đổi bạn đã thực hiện.
+
+### Vấn đề liên quan
+Liên kết đến các vấn đề liên quan: `Fixes #(số issue)`
+
+### Loại thay đổi
+Chọn các tùy chọn thích hợp:
+- [ ] Nội dung mới (ghi chú, đoạn mã)
+- [ ] Cải thiện nội dung (cập nhật, sửa lỗi, mở rộng)
+- [ ] Cập nhật tài liệu
+- [ ] Sửa lỗi (thay đổi không gây ảnh hưởng)
+- [ ] Cơ sở hạ tầng/công cụ (CI, scripts, v.v.)
+- [ ] Bản dịch (i18n) - chỉ rõ ngôn ngữ: ______
+- [ ] Khác (vui lòng mô tả)
+
+### Danh sách kiểm tra
+- [ ] Nội dung của tôi tuân theo hướng dẫn về phong cách của dự án
+- [ ] Tôi đã tự đánh giá nội dung/mã của mình
+- [ ] Tôi đã bao gồm tài liệu tham khảo/liên kết khi thích hợp
+- [ ] Các thay đổi của tôi không tạo ra cảnh báo hoặc lỗi mới
+- [ ] Tôi đã kiểm tra rằng tất cả các liên kết đều hợp lệ
+- [ ] Đối với bản dịch: Tôi đã tuân theo cấu trúc thư mục i18n (i18n/[language_code]/...)
+
+---
+
## ✅ Được phép trong Pull Request
- **Thêm nội dung mới** như:
@@ -22,8 +52,9 @@ Vui lòng đọc kỹ trước khi gửi PR.
- Sửa lỗi chính tả, ngữ pháp
- Cập nhật liên kết hoặc định dạng Markdown
- **Bản dịch ghi chú**:
- - Dùng hậu tố `_vi.md`, `_ja.md`, v.v.
+ - Sử dụng cấu trúc thư mục `i18n/[mã_ngôn_ngữ]/` (ví dụ: `i18n/vi/`, `i18n/fr/`)
- Nội dung bám sát logic file gốc
+ - Cập nhật trong SUMMARY.md dưới phần ngôn ngữ tương ứng
## ❌ Không được phép trong Pull Request
@@ -34,19 +65,21 @@ Vui lòng đọc kỹ trước khi gửi PR.
- ❌ Chèn liên kết quảng cáo, giới thiệu cá nhân, affiliate link
- ❌ File đặt tên sai quy tắc, không dùng định dạng Markdown hợp lệ
- ❌ Nội dung **sao chép có bản quyền** từ nguồn khác
+- ❌ Bản dịch không tuân thủ cấu trúc thư mục i18n đúng quy định
## 🔖 Lưu ý về cấu trúc & định dạng
- Trình bày **ngắn gọn, dễ hiểu, gần gũi**
- Sử dụng đúng cấp độ tiêu đề: `#`, `##`, `###`,...
- Đặt tên file bằng chữ thường, dùng dấu gạch ngang: `binary-search.md`
-- File dịch có hậu tố ngôn ngữ: `binary-search_vi.md`
- Đặt đúng thư mục chuyên đề (`algorithms/`, `design-patterns/`, `aws/`,...)
+- Đối với bản dịch, sử dụng cấu trúc `i18n/[mã_ngôn_ngữ]/`, phản ánh cấu trúc thư mục chính
+- Cập nhật SUMMARY.md để bao gồm nội dung mới hoặc bản dịch
## 📢 Lưu ý cuối
-Cảm ơn bạn đã đóng góp cho dự án!
-Tất cả pull request sẽ được review kỹ trước khi merge.
+Cảm ơn bạn đã đóng góp cho dự án!
+Tất cả pull request sẽ được review kỹ trước khi merge.
Nếu chưa chắc nội dung có phù hợp không, bạn có thể mở một issue để trao đổi trước.
Cùng nhau xây dựng một kho kiến thức chất lượng cho lập trình viên! 🚀
diff --git a/README.md b/README.md
index c555839..3a87c67 100644
--- a/README.md
+++ b/README.md
@@ -51,6 +51,8 @@ It's designed to be your go-to resource whether you're preparing for interviews,
Simply browse the folders or use GitHub's search feature to find the topic or pattern you need. Each note is designed to be self-contained with theory and practical code.
+**For a complete table of contents with all available notes and resources, check out the [SUMMARY.md](SUMMARY.md) file.**
+
## 🤝 Contribution
Contributions are highly welcome! If you want to:
@@ -67,6 +69,10 @@ Before submitting a pull request, make sure to check the [Pull Request Rules](PU
This project is licensed under the MIT License. See the [LICENSE](LICENSE.txt) file for details.
+## 📝 Changelog
+
+For a detailed list of all notable changes to this project, please see the [changelog](changelog.md) file.
+
## 🙌 Acknowledgements
Thanks to all contributors and the open source community for making this knowledge base better every day.
diff --git a/README_vi.md b/README_vi.md
index 3950470..1ff2b93 100644
--- a/README_vi.md
+++ b/README_vi.md
@@ -49,9 +49,11 @@ Dự án được thiết kế để trở thành tài nguyên tham khảo hàng
## 📖 Cách sử dụng
-Bạn có thể duyệt các thư mục hoặc dùng tính năng tìm kiếm của GitHub để tra cứu chủ đề hoặc mẫu thiết kế bạn cần.
+Bạn có thể duyệt các thư mục hoặc dùng tính năng tìm kiếm của GitHub để tra cứu chủ đề hoặc mẫu thiết kế bạn cần.
Mỗi ghi chú đều độc lập, bao gồm lý thuyết và mã ví dụ thực tế.
+**Để xem danh mục đầy đủ với tất cả các ghi chú và tài nguyên có sẵn, hãy xem file [SUMMARY.md](SUMMARY.md).**
+
## 🤝 Đóng góp
Mọi đóng góp đều rất hoan nghênh! Nếu bạn muốn:
@@ -68,6 +70,10 @@ Trước khi gửi pull request, vui lòng đọc kỹ [Quy định nội dung P
Dự án này được phát hành theo giấy phép MIT. Xem chi tiết trong file [LICENSE](LICENSE.txt).
+## 📝 Changelog
+
+Để biết danh sách chi tiết về tất cả những thay đổi đáng chú ý trong dự án này, vui lòng xem tệp [changelog](changelog_vi.md).
+
## 🙌 Lời cảm ơn
Cảm ơn tất cả các contributors và cộng đồng mã nguồn mở đã cùng nhau làm phong phú thêm kho kiến thức này mỗi ngày.
diff --git a/SUMMARY.md b/SUMMARY.md
new file mode 100644
index 0000000..3497c69
--- /dev/null
+++ b/SUMMARY.md
@@ -0,0 +1,34 @@
+# Tech Notes Hub
+
+## Table of Contents
+
+### Algorithms
+
+- [Graph Traversal Algorithms](docs/algorithms/graph-traversal.md)
+
+### Databases
+
+- [Relational Databases](docs/databases/relational.md)
+
+### Design Patterns
+
+- [Factory Design Pattern](docs/design-patterns/factory.md)
+- [Observer Design Pattern](docs/design-patterns/observer.md)
+- [Singleton Design Pattern](docs/design-patterns/singleton.md)
+
+### Devops
+
+- [Continuous Integration and Continuous Deployment (CI/CD)](docs/devops/ci-cd.md)
+
+### Linux
+
+- [Bash Scripting](docs/linux/bash-scripting.md)
+
+### System Design
+
+- [Microservices Architecture](docs/system-design/microservices.md)
+
+### Testing
+
+- [Unit Testing](docs/testing/unit-testing.md)
+
diff --git a/assets/diagrams/init.txt b/assets/diagrams/init.txt
new file mode 100644
index 0000000..e69de29
diff --git a/assets/init.txt b/assets/init.txt
new file mode 100644
index 0000000..e69de29
diff --git a/changelog.md b/changelog.md
new file mode 100644
index 0000000..e12ea66
--- /dev/null
+++ b/changelog.md
@@ -0,0 +1,31 @@
+# Big changelog
+
+All notable changes to the Tech Notes Hub project will be documented in this file.
+
+The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
+and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
+
+## [Unreleased]
+
+### Added
+- Security enhancement: Moved database credentials to environment variables
+- Added database code examples for Python and C#
+- Added design pattern implementations (Observer, Factory, Singleton)
+- Created comprehensive documentation in English and Vietnamese
+
+### Changed
+- Restructured repository to match documentation and code examples
+- Updated SQL examples to use parameterized queries for better security
+- Improved code organization in snippets directory
+
+### Security
+- Removed hardcoded database credentials
+- Added .env.example file with placeholder values
+- Updated .gitignore to prevent committing sensitive information
+
+## [1.0.0] - 2025-06-04
+
+### Added
+- Initial repository structure
+- Basic documentation framework
+- Core code examples for algorithms and data structures
diff --git a/changelog_vi.md b/changelog_vi.md
new file mode 100644
index 0000000..a4bc9b1
--- /dev/null
+++ b/changelog_vi.md
@@ -0,0 +1,31 @@
+# Nhật ký thay đổi lớn
+
+Tất cả những thay đổi đáng chú ý đối với dự án Tech Notes Hub sẽ được ghi lại trong tệp này.
+
+Định dạng dựa trên [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
+và dự án này tuân theo [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
+
+## [Chưa phát hành]
+
+### Đã thêm
+- Tăng cường bảo mật: Chuyển thông tin đăng nhập cơ sở dữ liệu vào biến môi trường
+- Thêm các ví dụ mã nguồn cơ sở dữ liệu cho Python và C#
+- Thêm các triển khai mẫu thiết kế (Observer, Factory, Singleton)
+- Tạo tài liệu toàn diện bằng tiếng Anh và tiếng Việt
+
+### Đã thay đổi
+- Cơ cấu lại kho lưu trữ để phù hợp với tài liệu và các ví dụ mã nguồn
+- Cập nhật các ví dụ SQL để sử dụng truy vấn có tham số để bảo mật tốt hơn
+- Cải thiện tổ chức mã trong thư mục snippets
+
+### Bảo mật
+- Loại bỏ thông tin đăng nhập cơ sở dữ liệu được mã hóa cứng
+- Thêm tệp .env.example với các giá trị giữ chỗ
+- Cập nhật .gitignore để ngăn chặn việc commit thông tin nhạy cảm
+
+## [1.0.0] - 2025-06-04
+
+### Đã thêm
+- Cấu trúc kho lưu trữ ban đầu
+- Khung tài liệu cơ bản
+- Các ví dụ mã nguồn cốt lõi cho thuật toán và cấu trúc dữ liệu
diff --git a/docs/_index.md b/docs/_index.md
new file mode 100644
index 0000000..dac2e6e
--- /dev/null
+++ b/docs/_index.md
@@ -0,0 +1,53 @@
+# Tech Notes Hub
+
+Welcome to the Tech Notes Hub! This repository is a comprehensive collection of technical notes, code snippets, and examples covering various topics in software development, system design, and computer science.
+
+## Purpose
+
+Tech Notes Hub aims to:
+
+- Provide clear, concise explanations of important technical concepts
+- Offer practical code examples in multiple programming languages
+- Serve as a reference for developers at all skill levels
+- Create a collaborative knowledge base for the tech community
+
+## Repository Structure
+
+The repository is organized into the following main sections:
+
+### Algorithms
+Implementations and explanations of common algorithms, including search, sort, graph traversal, and more.
+
+### Databases
+Notes on database systems, query optimization, data modeling, and best practices for both SQL and NoSQL databases.
+
+### Design Patterns
+Detailed explanations and implementations of software design patterns across multiple programming languages.
+
+### DevOps
+Information about continuous integration, deployment, containerization, and infrastructure management.
+
+### Linux
+Guides for Linux system administration, shell scripting, and command-line tools.
+
+### System Design
+Approaches to designing scalable, reliable, and maintainable software systems.
+
+### Testing
+Best practices for unit testing, integration testing, and test-driven development.
+
+## How to Use This Repository
+
+Each section contains markdown files with explanations and code snippets. You can:
+
+1. Browse the sections to find topics of interest
+2. Use the code examples as reference for your own projects
+3. Contribute by adding new content or improving existing documentation
+
+## Contributing
+
+We welcome contributions from the community! Please see our [CONTRIBUTING.md](../CONTRIBUTING.md) file for guidelines on how to contribute.
+
+## License
+
+This project is licensed under the MIT License - see the [LICENSE.txt](../LICENSE.txt) file for details.
diff --git a/docs/algorithms/graph-traversal.md b/docs/algorithms/graph-traversal.md
new file mode 100644
index 0000000..b16b9a2
--- /dev/null
+++ b/docs/algorithms/graph-traversal.md
@@ -0,0 +1,148 @@
+# Graph Traversal Algorithms
+
+Graph traversal algorithms are fundamental techniques used to visit every vertex in a graph. They serve as building blocks for many more complex graph algorithms.
+
+## Table of Contents
+
+- [Breadth-First Search (BFS)](#breadth-first-search-bfs)
+- [Depth-First Search (DFS)](#depth-first-search-dfs)
+- [Comparison of BFS and DFS](#comparison-of-bfs-and-dfs)
+- [Applications](#applications)
+- [Time and Space Complexity](#time-and-space-complexity)
+
+## Breadth-First Search (BFS)
+
+Breadth-First Search is a graph traversal algorithm that explores all vertices at the current depth level before moving to vertices at the next depth level.
+
+### How BFS Works
+
+1. Start at a source vertex and mark it as visited
+2. Visit all its unvisited neighbors and mark them as visited
+3. For each of those neighbors, visit all of their unvisited neighbors
+4. Repeat until all vertices have been visited
+
+### Implementation
+
+```python
+from collections import deque
+
+def bfs(graph, start):
+ visited = set([start])
+ queue = deque([start])
+ result = []
+
+ while queue:
+ vertex = queue.popleft()
+ result.append(vertex)
+
+ for neighbor in graph[vertex]:
+ if neighbor not in visited:
+ visited.add(neighbor)
+ queue.append(neighbor)
+
+ return result
+
+# Example usage
+graph = {
+ 'A': ['B', 'C'],
+ 'B': ['A', 'D', 'E'],
+ 'C': ['A', 'F'],
+ 'D': ['B'],
+ 'E': ['B', 'F'],
+ 'F': ['C', 'E']
+}
+
+print(bfs(graph, 'A')) # Output: ['A', 'B', 'C', 'D', 'E', 'F']
+```
+
+## Depth-First Search (DFS)
+
+Depth-First Search is a graph traversal algorithm that explores as far as possible along each branch before backtracking.
+
+### How DFS Works
+
+1. Start at a source vertex and mark it as visited
+2. Recursively visit one of its unvisited neighbors
+3. Continue this process, going deeper into the graph
+4. When you reach a vertex with no unvisited neighbors, backtrack
+
+### Implementation
+
+```python
+def dfs_recursive(graph, vertex, visited=None, result=None):
+ if visited is None:
+ visited = set()
+ if result is None:
+ result = []
+
+ visited.add(vertex)
+ result.append(vertex)
+
+ for neighbor in graph[vertex]:
+ if neighbor not in visited:
+ dfs_recursive(graph, neighbor, visited, result)
+
+ return result
+
+# Iterative implementation using a stack
+def dfs_iterative(graph, start):
+ visited = set()
+ stack = [start]
+ result = []
+
+ while stack:
+ vertex = stack.pop()
+ if vertex not in visited:
+ visited.add(vertex)
+ result.append(vertex)
+
+ # Add neighbors in reverse order to simulate recursive DFS
+ for neighbor in reversed(graph[vertex]):
+ if neighbor not in visited:
+ stack.append(neighbor)
+
+ return result
+
+# Example usage (same graph as BFS example)
+print(dfs_recursive(graph, 'A')) # Output might be: ['A', 'B', 'D', 'E', 'F', 'C']
+print(dfs_iterative(graph, 'A')) # Similar output, might vary depending on neighbor order
+```
+
+## Comparison of BFS and DFS
+
+| Aspect | BFS | DFS |
+|--------|-----|-----|
+| Data Structure | Queue | Stack (or recursion) |
+| Space Complexity | O(b^d) where b is branching factor and d is distance from source | O(h) where h is the height of the tree |
+| Completeness | Complete (finds all nodes at a given depth before moving deeper) | Not complete for infinite graphs |
+| Optimality | Optimal for unweighted graphs | Not optimal in general |
+| Use Case | Shortest path in unweighted graphs, level order traversal | Topological sorting, cycle detection, path finding |
+
+## Applications
+
+- **BFS Applications**:
+ - Finding the shortest path in unweighted graphs
+ - Finding all nodes within one connected component
+ - Testing bipartiteness of a graph
+ - Web crawlers
+ - Social networking features (e.g., "Friends within 2 connections")
+
+- **DFS Applications**:
+ - Topological sorting
+ - Finding strongly connected components
+ - Solving puzzles with only one solution (e.g., mazes)
+ - Cycle detection
+ - Path finding in games and puzzles
+
+## Time and Space Complexity
+
+Both BFS and DFS have a time complexity of O(V + E) where V is the number of vertices and E is the number of edges. This is because in the worst case, each vertex and each edge will be explored once.
+
+Space complexity:
+- BFS: O(V) in the worst case when all vertices are stored in the queue
+- DFS: O(h) where h is the maximum depth of the recursion stack (which could be O(V) in the worst case)
+
+## References
+
+1. Cormen, T. H., Leiserson, C. E., Rivest, R. L., & Stein, C. (2009). Introduction to Algorithms (3rd ed.). MIT Press.
+2. Sedgewick, R., & Wayne, K. (2011). Algorithms (4th ed.). Addison-Wesley Professional.
\ No newline at end of file
diff --git a/docs/databases/relational.md b/docs/databases/relational.md
new file mode 100644
index 0000000..82132a6
--- /dev/null
+++ b/docs/databases/relational.md
@@ -0,0 +1,117 @@
+# Relational Databases
+
+Relational databases are organized collections of data that store information in tables with rows and columns. They follow the relational model proposed by Edgar F. Codd in 1970, which emphasizes relationships between data entities.
+
+## Core Concepts
+
+### Tables (Relations)
+
+The fundamental structure in relational databases:
+- Each **table** represents an entity type (e.g., customers, products)
+- Each **row** (tuple) represents an instance of that entity
+- Each **column** (attribute) represents a property of that entity
+
+### Keys
+
+Keys establish relationships and ensure data integrity:
+
+- **Primary Key**: Uniquely identifies each record in a table
+- **Foreign Key**: References a primary key in another table, establishing relationships
+- **Composite Key**: Combines multiple columns to form a unique identifier
+- **Candidate Key**: A column or set of columns that could serve as a primary key
+
+### Schema
+
+A schema defines the structure of the database:
+- Table definitions
+- Column data types and constraints
+- Relationships between tables
+
+## SQL (Structured Query Language)
+
+SQL is the standard language for interacting with relational databases.
+
+### Basic SQL Commands
+
+```sql
+-- Create a table
+CREATE TABLE customers (
+ customer_id INT PRIMARY KEY,
+ name VARCHAR(100),
+ email VARCHAR(100),
+ signup_date DATE
+);
+
+-- Insert data
+INSERT INTO customers (customer_id, name, email, signup_date)
+VALUES (1, 'John Smith', 'john@example.com', '2023-01-15');
+
+-- Query data
+SELECT * FROM customers WHERE signup_date > '2023-01-01';
+
+-- Update data
+UPDATE customers SET email = 'john.smith@example.com' WHERE customer_id = 1;
+
+-- Delete data
+DELETE FROM customers WHERE customer_id = 1;
+```
+
+## Normalization
+
+Normalization is the process of organizing data to reduce redundancy and improve data integrity:
+
+- **First Normal Form (1NF)**: Eliminate duplicate columns and create separate tables for related data
+- **Second Normal Form (2NF)**: Meet 1NF requirements and remove partial dependencies
+- **Third Normal Form (3NF)**: Meet 2NF requirements and remove transitive dependencies
+
+## ACID Properties
+
+Transactions in relational databases follow ACID properties:
+
+- **Atomicity**: Transactions are all-or-nothing operations
+- **Consistency**: Transactions bring the database from one valid state to another
+- **Isolation**: Concurrent transactions don't interfere with each other
+- **Durability**: Completed transactions persist even in case of system failure
+
+## Popular Relational Database Systems
+
+- **MySQL**: Open-source, widely used for web applications
+- **PostgreSQL**: Advanced open-source database with extensive features
+- **Oracle Database**: Enterprise-level commercial database
+- **Microsoft SQL Server**: Microsoft's commercial database solution
+- **SQLite**: Lightweight, serverless database engine
+
+## Indexes
+
+Indexes speed up data retrieval operations:
+- Similar to a book index
+- Improves query performance but adds overhead for write operations
+- Types include B-tree, hash, and bitmap indexes
+
+## Joins
+
+Joins combine records from two or more tables:
+- **INNER JOIN**: Returns records with matching values in both tables
+- **LEFT JOIN**: Returns all records from the left table and matching records from the right
+- **RIGHT JOIN**: Returns all records from the right table and matching records from the left
+- **FULL JOIN**: Returns all records when there's a match in either table
+
+```sql
+SELECT customers.name, orders.order_date
+FROM customers
+INNER JOIN orders ON customers.customer_id = orders.customer_id;
+```
+
+## When to Use Relational Databases
+
+Relational databases are ideal for:
+- Structured data with clear relationships
+- Applications requiring complex queries and transactions
+- Systems where data integrity is critical
+- Scenarios where consistency is more important than speed
+
+## References
+
+- Codd, E.F. (1970). "A Relational Model of Data for Large Shared Data Banks"
+- Date, C.J. "An Introduction to Database Systems"
+- Garcia-Molina, H., Ullman, J.D., & Widom, J. "Database Systems: The Complete Book"
\ No newline at end of file
diff --git a/docs/design-patterns/factory.md b/docs/design-patterns/factory.md
new file mode 100644
index 0000000..2ab9d1b
--- /dev/null
+++ b/docs/design-patterns/factory.md
@@ -0,0 +1,476 @@
+# Factory Design Pattern
+
+The Factory pattern is a creational design pattern that provides an interface for creating objects in a superclass, but allows subclasses to alter the type of objects that will be created.
+
+## Intent
+
+- Create objects without exposing the instantiation logic to the client
+- Refer to newly created objects using a common interface
+- Decouple the implementation of an object from its use
+
+## Problem
+
+When should you use the Factory pattern?
+
+- When a class cannot anticipate the type of objects it needs to create
+- When a class wants its subclasses to specify the objects it creates
+- When you want to localize the knowledge of which class gets created
+
+## Types of Factory Patterns
+
+There are several variations of the Factory pattern:
+
+1. **Simple Factory** - Not a formal pattern, but a simple way to separate object creation
+2. **Factory Method** - Defines an interface for creating objects, but lets subclasses decide which classes to instantiate
+3. **Abstract Factory** - Provides an interface for creating families of related or dependent objects
+
+## Structure
+
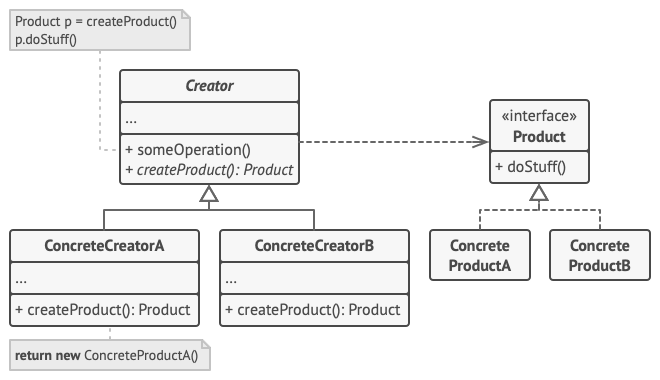
+### Factory Method Pattern
+
+
+
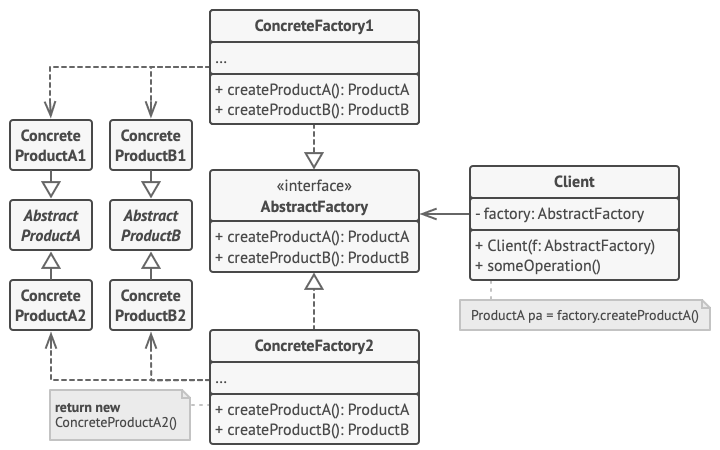
+### Abstract Factory Pattern
+
+
+
+## Implementation
+
+### Simple Factory Example
+
+```java
+// Product interface
+interface Product {
+ void operation();
+}
+
+// Concrete products
+class ConcreteProductA implements Product {
+ @Override
+ public void operation() {
+ System.out.println("ConcreteProductA operation");
+ }
+}
+
+class ConcreteProductB implements Product {
+ @Override
+ public void operation() {
+ System.out.println("ConcreteProductB operation");
+ }
+}
+
+// Simple factory
+class SimpleFactory {
+ public Product createProduct(String type) {
+ if (type.equals("A")) {
+ return new ConcreteProductA();
+ } else if (type.equals("B")) {
+ return new ConcreteProductB();
+ }
+ throw new IllegalArgumentException("Invalid product type: " + type);
+ }
+}
+
+// Client code
+class Client {
+ public static void main(String[] args) {
+ SimpleFactory factory = new SimpleFactory();
+
+ Product productA = factory.createProduct("A");
+ productA.operation();
+
+ Product productB = factory.createProduct("B");
+ productB.operation();
+ }
+}
+```
+
+### Factory Method Example
+
+```java
+// Product interface
+interface Product {
+ void operation();
+}
+
+// Concrete products
+class ConcreteProductA implements Product {
+ @Override
+ public void operation() {
+ System.out.println("ConcreteProductA operation");
+ }
+}
+
+class ConcreteProductB implements Product {
+ @Override
+ public void operation() {
+ System.out.println("ConcreteProductB operation");
+ }
+}
+
+// Creator abstract class with factory method
+abstract class Creator {
+ public abstract Product createProduct();
+
+ // The creator can also include some business logic
+ public void someOperation() {
+ // Call the factory method to create a Product object
+ Product product = createProduct();
+ // Use the product
+ product.operation();
+ }
+}
+
+// Concrete creators override factory method
+class ConcreteCreatorA extends Creator {
+ @Override
+ public Product createProduct() {
+ return new ConcreteProductA();
+ }
+}
+
+class ConcreteCreatorB extends Creator {
+ @Override
+ public Product createProduct() {
+ return new ConcreteProductB();
+ }
+}
+
+// Client code
+class Client {
+ public static void main(String[] args) {
+ Creator creatorA = new ConcreteCreatorA();
+ creatorA.someOperation();
+
+ Creator creatorB = new ConcreteCreatorB();
+ creatorB.someOperation();
+ }
+}
+```
+
+### Abstract Factory Example
+
+```java
+// Abstract products
+interface ProductA {
+ void operationA();
+}
+
+interface ProductB {
+ void operationB();
+}
+
+// Concrete products for family 1
+class ConcreteProductA1 implements ProductA {
+ @Override
+ public void operationA() {
+ System.out.println("Product A1 operation");
+ }
+}
+
+class ConcreteProductB1 implements ProductB {
+ @Override
+ public void operationB() {
+ System.out.println("Product B1 operation");
+ }
+}
+
+// Concrete products for family 2
+class ConcreteProductA2 implements ProductA {
+ @Override
+ public void operationA() {
+ System.out.println("Product A2 operation");
+ }
+}
+
+class ConcreteProductB2 implements ProductB {
+ @Override
+ public void operationB() {
+ System.out.println("Product B2 operation");
+ }
+}
+
+// Abstract factory interface
+interface AbstractFactory {
+ ProductA createProductA();
+ ProductB createProductB();
+}
+
+// Concrete factories
+class ConcreteFactory1 implements AbstractFactory {
+ @Override
+ public ProductA createProductA() {
+ return new ConcreteProductA1();
+ }
+
+ @Override
+ public ProductB createProductB() {
+ return new ConcreteProductB1();
+ }
+}
+
+class ConcreteFactory2 implements AbstractFactory {
+ @Override
+ public ProductA createProductA() {
+ return new ConcreteProductA2();
+ }
+
+ @Override
+ public ProductB createProductB() {
+ return new ConcreteProductB2();
+ }
+}
+
+// Client code
+class Client {
+ private ProductA productA;
+ private ProductB productB;
+
+ public Client(AbstractFactory factory) {
+ productA = factory.createProductA();
+ productB = factory.createProductB();
+ }
+
+ public void executeOperations() {
+ productA.operationA();
+ productB.operationB();
+ }
+}
+```
+
+## Examples in Different Languages
+
+### JavaScript
+
+```javascript
+// Factory Method in JavaScript
+
+// Product interface is implicit in JavaScript
+class Dog {
+ speak() {
+ return "Woof!";
+ }
+}
+
+class Cat {
+ speak() {
+ return "Meow!";
+ }
+}
+
+// Creator
+class AnimalFactory {
+ // Factory method
+ createAnimal(type) {
+ switch(type) {
+ case 'dog':
+ return new Dog();
+ case 'cat':
+ return new Cat();
+ default:
+ throw new Error(`Animal type ${type} is not supported.`);
+ }
+ }
+}
+
+// Usage
+const factory = new AnimalFactory();
+const dog = factory.createAnimal('dog');
+const cat = factory.createAnimal('cat');
+
+console.log(dog.speak()); // Outputs: Woof!
+console.log(cat.speak()); // Outputs: Meow!
+```
+
+### Python
+
+```python
+from abc import ABC, abstractmethod
+
+# Abstract Product
+class Button(ABC):
+ @abstractmethod
+ def render(self):
+ pass
+
+ @abstractmethod
+ def on_click(self):
+ pass
+
+# Concrete Products
+class HTMLButton(Button):
+ def render(self):
+ return ""
+
+ def on_click(self):
+ return "HTML Button clicked!"
+
+class WindowsButton(Button):
+ def render(self):
+ return "Windows Button"
+
+ def on_click(self):
+ return "Windows Button clicked!"
+
+# Abstract Creator
+class Dialog(ABC):
+ @abstractmethod
+ def create_button(self) -> Button:
+ pass
+
+ def render(self):
+ # Call the factory method to create a button object
+ button = self.create_button()
+ # Now use the product
+ return f"Dialog rendering with {button.render()}"
+
+# Concrete Creators
+class HTMLDialog(Dialog):
+ def create_button(self) -> Button:
+ return HTMLButton()
+
+class WindowsDialog(Dialog):
+ def create_button(self) -> Button:
+ return WindowsButton()
+
+# Client code
+def client_code(dialog: Dialog):
+ print(dialog.render())
+
+# Based on environment, we select the appropriate dialog
+import sys
+if sys.platform.startswith('win'):
+ dialog = WindowsDialog()
+else:
+ dialog = HTMLDialog()
+
+client_code(dialog)
+```
+
+### C#
+
+```csharp
+using System;
+
+// Abstract Product
+public interface IVehicle
+{
+ void Drive();
+}
+
+// Concrete Products
+public class Car : IVehicle
+{
+ public void Drive()
+ {
+ Console.WriteLine("Driving a car...");
+ }
+}
+
+public class Motorcycle : IVehicle
+{
+ public void Drive()
+ {
+ Console.WriteLine("Driving a motorcycle...");
+ }
+}
+
+// Abstract Creator
+public abstract class VehicleFactory
+{
+ // Factory Method
+ public abstract IVehicle CreateVehicle();
+
+ public void DeliverVehicle()
+ {
+ IVehicle vehicle = CreateVehicle();
+ Console.WriteLine("Delivering the vehicle...");
+ vehicle.Drive();
+ }
+}
+
+// Concrete Creators
+public class CarFactory : VehicleFactory
+{
+ public override IVehicle CreateVehicle()
+ {
+ return new Car();
+ }
+}
+
+public class MotorcycleFactory : VehicleFactory
+{
+ public override IVehicle CreateVehicle()
+ {
+ return new Motorcycle();
+ }
+}
+
+// Client code
+public class Program
+{
+ public static void Main()
+ {
+ VehicleFactory factory = GetFactory("car");
+ factory.DeliverVehicle();
+
+ factory = GetFactory("motorcycle");
+ factory.DeliverVehicle();
+ }
+
+ private static VehicleFactory GetFactory(string vehicleType)
+ {
+ switch (vehicleType.ToLower())
+ {
+ case "car":
+ return new CarFactory();
+ case "motorcycle":
+ return new MotorcycleFactory();
+ default:
+ throw new ArgumentException($"Vehicle type {vehicleType} is not supported.");
+ }
+ }
+}
+```
+
+## Use Cases
+
+- **UI Component Creation**: Creating different UI components based on user preferences or platform
+- **Database Connections**: Creating the right database connection based on configuration
+- **Document Generation**: Creating different document types (PDF, Word, etc.)
+- **Vehicle Manufacturing**: Creating different types of vehicles in a simulation
+- **Payment Processing**: Creating different payment methods in an e-commerce application
+
+## Pros and Cons
+
+### Pros
+
+- Avoids tight coupling between creator and concrete products
+- Single Responsibility Principle: Move product creation code to one place
+- Open/Closed Principle: New products can be added without breaking existing code
+- Creates objects on demand, rather than at initialization time
+
+### Cons
+
+- Code may become more complicated due to introduction of many new subclasses
+- Client might be limited to the products exposed by the factory interface
+
+## Relations with Other Patterns
+
+- **Abstract Factory** classes are often implemented with Factory Methods
+- **Factory Methods** are often used in Template Methods
+- **Prototype** can be an alternative to Factory when the goal is to reduce subclassing
+- **Builder** focuses on constructing complex objects step by step, while Factory Method is a single method call
+
+## Real-World Examples
+
+- Java's `Calendar.getInstance()`
+- UI frameworks' widget factories
+- Database connection factories
+- Document generators in office suites
+
+## References
+
+- "Design Patterns: Elements of Reusable Object-Oriented Software" by Gang of Four (GoF)
+- [Refactoring Guru - Factory Method Pattern](https://refactoring.guru/design-patterns/factory-method)
+- [Refactoring Guru - Abstract Factory Pattern](https://refactoring.guru/design-patterns/abstract-factory)
\ No newline at end of file
diff --git a/docs/design-patterns/observer.md b/docs/design-patterns/observer.md
new file mode 100644
index 0000000..b15b4b9
--- /dev/null
+++ b/docs/design-patterns/observer.md
@@ -0,0 +1,404 @@
+# Observer Design Pattern
+
+The Observer pattern is a behavioral design pattern where an object, called the subject, maintains a list of its dependents, called observers, and notifies them automatically of any state changes, usually by calling one of their methods.
+
+## Intent
+
+- Define a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically.
+- Encapsulate the core components in a Subject abstraction, and the variable components in an Observer hierarchy.
+- The Subject and Observer classes can vary independently.
+
+## Problem
+
+In many applications, specific types of objects need to be informed about changes in other objects. However, we don't want to couple these different types of objects too tightly to maintain flexibility and reusability.
+
+You need a way for an object to notify an open-ended number of other objects about changes, without having those objects tightly coupled to each other.
+
+## Structure
+
+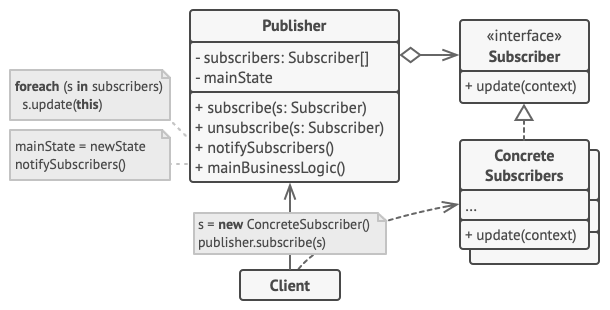
+
+- **Subject**: Interface or abstract class defining operations for attaching, detaching, and notifying observers.
+- **ConcreteSubject**: Maintains state of interest to observers and sends notifications when state changes.
+- **Observer**: Interface or abstract class with an update method that gets called when the subject's state changes.
+- **ConcreteObserver**: Implements the Observer interface to keep its state consistent with the subject's state.
+
+## Implementation
+
+### Basic Implementation
+
+```java
+// Observer interface
+interface Observer {
+ void update(Subject subject);
+}
+
+// Subject interface
+interface Subject {
+ void attach(Observer observer);
+ void detach(Observer observer);
+ void notifyObservers();
+}
+
+// Concrete Subject
+class ConcreteSubject implements Subject {
+ private List observers = new ArrayList<>();
+ private int state;
+
+ public int getState() {
+ return state;
+ }
+
+ public void setState(int state) {
+ this.state = state;
+ notifyObservers();
+ }
+
+ @Override
+ public void attach(Observer observer) {
+ observers.add(observer);
+ }
+
+ @Override
+ public void detach(Observer observer) {
+ observers.remove(observer);
+ }
+
+ @Override
+ public void notifyObservers() {
+ for (Observer observer : observers) {
+ observer.update(this);
+ }
+ }
+}
+
+// Concrete Observer
+class ConcreteObserver implements Observer {
+ private int observerState;
+
+ @Override
+ public void update(Subject subject) {
+ if (subject instanceof ConcreteSubject) {
+ observerState = ((ConcreteSubject) subject).getState();
+ System.out.println("Observer state updated to: " + observerState);
+ }
+ }
+}
+```
+
+### Push vs. Pull Models
+
+#### Push Model
+
+In the push model, the Subject sends detailed information about the change to all Observers, whether they need it or not:
+
+```java
+// In ConcreteSubject
+public void notifyObservers(int state) {
+ for (Observer observer : observers) {
+ observer.update(state);
+ }
+}
+
+// In Observer interface
+void update(int state);
+```
+
+#### Pull Model
+
+In the pull model, the Subject simply notifies Observers that a change occurred, and Observers are responsible for pulling the needed data:
+
+```java
+// In ConcreteSubject
+public void notifyObservers() {
+ for (Observer observer : observers) {
+ observer.update(this);
+ }
+}
+
+// In Observer interface
+void update(Subject subject);
+```
+
+## Examples in Different Languages
+
+### JavaScript
+
+```javascript
+// Using ES6 classes
+class Subject {
+ constructor() {
+ this.observers = [];
+ }
+
+ attach(observer) {
+ if (!this.observers.includes(observer)) {
+ this.observers.push(observer);
+ }
+ }
+
+ detach(observer) {
+ const index = this.observers.indexOf(observer);
+ if (index !== -1) {
+ this.observers.splice(index, 1);
+ }
+ }
+
+ notify() {
+ for (const observer of this.observers) {
+ observer.update(this);
+ }
+ }
+}
+
+class WeatherStation extends Subject {
+ constructor() {
+ super();
+ this.temperature = 0;
+ this.humidity = 0;
+ }
+
+ setMeasurements(temperature, humidity) {
+ this.temperature = temperature;
+ this.humidity = humidity;
+ this.notify();
+ }
+
+ getTemperature() {
+ return this.temperature;
+ }
+
+ getHumidity() {
+ return this.humidity;
+ }
+}
+
+class Observer {
+ update(subject) {}
+}
+
+class DisplayDevice extends Observer {
+ constructor(name) {
+ super();
+ this.name = name;
+ }
+
+ update(weatherStation) {
+ console.log(`${this.name} Display: Temperature ${weatherStation.getTemperature()}°C, Humidity ${weatherStation.getHumidity()}%`);
+ }
+}
+
+// Usage
+const weatherStation = new WeatherStation();
+const phoneDisplay = new DisplayDevice('Phone');
+const laptopDisplay = new DisplayDevice('Laptop');
+
+weatherStation.attach(phoneDisplay);
+weatherStation.attach(laptopDisplay);
+
+weatherStation.setMeasurements(25, 60); // Both displays update
+weatherStation.detach(laptopDisplay);
+weatherStation.setMeasurements(26, 70); // Only phone display updates
+```
+
+### Python
+
+```python
+from abc import ABC, abstractmethod
+
+# Observer interface
+class Observer(ABC):
+ @abstractmethod
+ def update(self, subject):
+ pass
+
+# Subject interface
+class Subject(ABC):
+ @abstractmethod
+ def attach(self, observer):
+ pass
+
+ @abstractmethod
+ def detach(self, observer):
+ pass
+
+ @abstractmethod
+ def notify(self):
+ pass
+
+# Concrete Subject
+class NewsPublisher(Subject):
+ def __init__(self):
+ self._observers = []
+ self._latest_news = None
+
+ def attach(self, observer):
+ self._observers.append(observer)
+
+ def detach(self, observer):
+ self._observers.remove(observer)
+
+ def notify(self):
+ for observer in self._observers:
+ observer.update(self)
+
+ def add_news(self, news):
+ self._latest_news = news
+ self.notify()
+
+ @property
+ def latest_news(self):
+ return self._latest_news
+
+# Concrete Observer
+class NewsSubscriber(Observer):
+ def __init__(self, name):
+ self._name = name
+
+ def update(self, subject):
+ print(f"{self._name} received news: {subject.latest_news}")
+
+# Usage
+if __name__ == "__main__":
+ publisher = NewsPublisher()
+
+ subscriber1 = NewsSubscriber("Subscriber 1")
+ subscriber2 = NewsSubscriber("Subscriber 2")
+
+ publisher.attach(subscriber1)
+ publisher.attach(subscriber2)
+
+ publisher.add_news("Breaking News: Observer Pattern in Action!")
+
+ publisher.detach(subscriber1)
+
+ publisher.add_news("Another Update: Subscriber 1 has unsubscribed!")
+```
+
+### C#
+
+```csharp
+using System;
+using System.Collections.Generic;
+
+// Observer interface
+public interface IObserver
+{
+ void Update(ISubject subject);
+}
+
+// Subject interface
+public interface ISubject
+{
+ void Attach(IObserver observer);
+ void Detach(IObserver observer);
+ void Notify();
+}
+
+// Concrete Subject
+public class StockMarket : ISubject
+{
+ private List _observers = new List();
+ private Dictionary _stocks = new Dictionary();
+
+ public void Attach(IObserver observer)
+ {
+ Console.WriteLine("StockMarket: Attached an observer.");
+ _observers.Add(observer);
+ }
+
+ public void Detach(IObserver observer)
+ {
+ _observers.Remove(observer);
+ Console.WriteLine("StockMarket: Detached an observer.");
+ }
+
+ public void Notify()
+ {
+ Console.WriteLine("StockMarket: Notifying observers...");
+
+ foreach (var observer in _observers)
+ {
+ observer.Update(this);
+ }
+ }
+
+ public void UpdateStockPrice(string stockSymbol, double price)
+ {
+ Console.WriteLine($"StockMarket: {stockSymbol} price updated to {price}");
+ _stocks[stockSymbol] = price;
+ Notify();
+ }
+
+ public Dictionary GetStocks()
+ {
+ return _stocks;
+ }
+}
+
+// Concrete Observer
+public class Investor : IObserver
+{
+ private string _name;
+ private Dictionary _watchlist = new Dictionary();
+
+ public Investor(string name)
+ {
+ _name = name;
+ }
+
+ public void Update(ISubject subject)
+ {
+ if (subject is StockMarket stockMarket)
+ {
+ var stocks = stockMarket.GetStocks();
+ foreach (var stock in stocks)
+ {
+ if (_watchlist.ContainsKey(stock.Key) && _watchlist[stock.Key] != stock.Value)
+ {
+ Console.WriteLine($"{_name}: Noticed {stock.Key} price changed from {_watchlist[stock.Key]} to {stock.Value}");
+ }
+ _watchlist[stock.Key] = stock.Value;
+ }
+ }
+ }
+}
+```
+
+## Real-World Use Cases
+
+1. **Event Handling Systems**: UI frameworks use Observer pattern to handle user actions.
+2. **News Subscription Services**: Users subscribe to topics and receive updates.
+3. **Stock Market Monitoring**: Investors monitor stock price changes.
+4. **Social Media Notifications**: Users get notified about activities related to their account.
+5. **Message Queue Systems**: Publishers send messages to subscribed consumers.
+6. **Monitoring Systems**: Applications monitor system resources or services.
+
+## Pros and Cons
+
+### Pros
+
+- **Open/Closed Principle**: You can introduce new subscriber classes without changing the publisher's code.
+- **Loose Coupling**: Publishers don't need to know anything about subscribers.
+- **Dynamic Relationships**: Relationships between publishers and subscribers can be established at runtime.
+- **Event Handling**: Effective for implementing event handling systems.
+
+### Cons
+
+- **Unexpected Updates**: Subscribers can be notified in an unpredictable order.
+- **Memory Leaks**: If observers forget to unsubscribe, they might not be garbage collected.
+- **Performance Overhead**: Notification can be costly if there are many observers or frequent state changes.
+- **Complexity**: Debugging can be challenging because the flow of control is less obvious.
+
+## Relations with Other Patterns
+
+- **Mediator**: While Observer distributes communication by introducing subscriber and publisher objects, Mediator encapsulates the communication between objects.
+- **Command**: Commands can be used to implement the Observer pattern by turning requests into objects.
+- **Memento**: Can be used with Observer to undo operations after notifying observers about the changes.
+- **MVC Pattern**: The Observer pattern is often used in MVC architectures where the View observes changes in the Model.
+
+## References
+
+- "Design Patterns: Elements of Reusable Object-Oriented Software" by Gang of Four (GoF)
+- [Refactoring Guru - Observer Pattern](https://refactoring.guru/design-patterns/observer)
+- [SourceMaking - Observer Pattern](https://sourcemaking.com/design_patterns/observer)
\ No newline at end of file
diff --git a/docs/design-patterns/singleton.md b/docs/design-patterns/singleton.md
new file mode 100644
index 0000000..2e72e49
--- /dev/null
+++ b/docs/design-patterns/singleton.md
@@ -0,0 +1,226 @@
+# Singleton Design Pattern
+
+The Singleton pattern is a creational design pattern that ensures a class has only one instance and provides a global point of access to that instance.
+
+## Intent
+
+- Ensure a class has only one instance.
+- Provide a global access point to that instance.
+- Control concurrent access to shared resources.
+
+## Problem
+
+When should you use the Singleton pattern?
+
+- When you need exactly one instance of a class to coordinate actions across the system
+- When you want to restrict the instantiation of a class to just one object
+- When you need stricter control over global variables
+
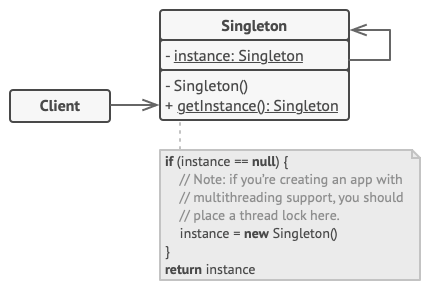
+## Structure
+
+```
++----------------+
+| Singleton |
++----------------+
+| -instance |
++----------------+
+| +getInstance() |
+| -constructor() |
++----------------+
+```
+
+
+
+## Implementation
+
+### Basic Implementation
+
+```java
+public class Singleton {
+ // The private static instance of the class
+ private static Singleton instance;
+
+ // Private constructor prevents instantiation from other classes
+ private Singleton() { }
+
+ // The public static method to get the instance
+ public static Singleton getInstance() {
+ if (instance == null) {
+ instance = new Singleton();
+ }
+ return instance;
+ }
+
+ // Other methods and fields
+ public void doSomething() {
+ System.out.println("Singleton is doing something");
+ }
+}
+```
+
+### Thread-Safe Implementation
+
+```java
+public class ThreadSafeSingleton {
+ private static volatile ThreadSafeSingleton instance;
+
+ private ThreadSafeSingleton() { }
+
+ public static ThreadSafeSingleton getInstance() {
+ // Double-checked locking
+ if (instance == null) {
+ synchronized (ThreadSafeSingleton.class) {
+ if (instance == null) {
+ instance = new ThreadSafeSingleton();
+ }
+ }
+ }
+ return instance;
+ }
+}
+```
+
+### Eager Initialization
+
+```java
+public class EagerSingleton {
+ // Instance is created at load time
+ private static final EagerSingleton INSTANCE = new EagerSingleton();
+
+ private EagerSingleton() { }
+
+ public static EagerSingleton getInstance() {
+ return INSTANCE;
+ }
+}
+```
+
+### Using Enum (Java)
+
+```java
+public enum EnumSingleton {
+ INSTANCE;
+
+ public void doSomething() {
+ System.out.println("Singleton enum is doing something");
+ }
+}
+```
+
+## Examples in Different Languages
+
+### JavaScript
+
+```javascript
+class Singleton {
+ constructor() {
+ if (Singleton.instance) {
+ return Singleton.instance;
+ }
+
+ // Initialize the singleton
+ this.data = [];
+ Singleton.instance = this;
+ }
+
+ add(item) {
+ this.data.push(item);
+ }
+
+ get(index) {
+ return this.data[index];
+ }
+}
+
+// Usage
+const instance1 = new Singleton();
+const instance2 = new Singleton();
+console.log(instance1 === instance2); // true
+```
+
+### Python
+
+```python
+class Singleton:
+ _instance = None
+
+ def __new__(cls):
+ if cls._instance is None:
+ cls._instance = super(Singleton, cls).__new__(cls)
+ # Initialize your singleton here
+ cls._instance.value = 0
+ return cls._instance
+
+# Usage
+s1 = Singleton()
+s2 = Singleton()
+print(s1 is s2) # True
+```
+
+### C#
+
+```csharp
+public sealed class Singleton
+{
+ private static Singleton instance = null;
+ private static readonly object padlock = new object();
+
+ Singleton() {}
+
+ public static Singleton Instance
+ {
+ get
+ {
+ lock(padlock)
+ {
+ if (instance == null)
+ {
+ instance = new Singleton();
+ }
+ return instance;
+ }
+ }
+ }
+}
+```
+
+## Use Cases
+
+- **Database connections**: Manage a connection pool
+- **Logger**: Create a single logging instance for an application
+- **Configuration settings**: Store application settings
+- **Cache**: Create a single cache manager
+- **Thread pools**: Manage thread creation and assignment
+
+## Pros and Cons
+
+### Pros
+
+- Ensures a class has just a single instance
+- Provides a global access point to that instance
+- The singleton object is initialized only when it's requested for the first time
+
+### Cons
+
+- Violates the Single Responsibility Principle (the class manages its own creation)
+- Can mask bad design, for instance, when components know too much about each other
+- Requires special treatment in a multithreaded environment
+- Makes unit testing more difficult
+
+## Relations with Other Patterns
+
+- A **Facade** might look like a Singleton if it only hides one object, but they have different purposes
+- **Abstract Factories**, **Builders**, and **Prototypes** can all be implemented as Singletons
+
+## Real-World Examples
+
+- Java's `java.lang.Runtime` class
+- UI Managers in many GUI frameworks
+- Windows Registry
+- Browser's window object
+
+## References
+
+- "Design Patterns: Elements of Reusable Object-Oriented Software" by Gang of Four (GoF)
+- [Refactoring Guru - Singleton Pattern](https://refactoring.guru/design-patterns/singleton)
+- [SourceMaking - Singleton Pattern](https://sourcemaking.com/design_patterns/singleton)
\ No newline at end of file
diff --git a/docs/devops/ci-cd.md b/docs/devops/ci-cd.md
new file mode 100644
index 0000000..bdaa6f5
--- /dev/null
+++ b/docs/devops/ci-cd.md
@@ -0,0 +1,162 @@
+# Continuous Integration and Continuous Deployment (CI/CD)
+
+Continuous Integration and Continuous Deployment (CI/CD) is a method to frequently deliver apps to customers by introducing automation into the stages of app development.
+
+## What is CI/CD?
+
+### Continuous Integration (CI)
+Continuous Integration is a development practice where developers integrate code into a shared repository frequently, preferably several times a day. Each integration can then be verified by an automated build and automated tests.
+
+### Continuous Delivery (CD)
+Continuous Delivery is an extension of continuous integration to ensure that you can release new changes to your customers quickly in a sustainable way. This means that on top of having automated your testing, you also have automated your release process and you can deploy your application at any point of time by clicking a button.
+
+### Continuous Deployment
+Continuous Deployment goes one step further than Continuous Delivery. With this practice, every change that passes all stages of your production pipeline is released to your customers. There's no human intervention, and only a failed test will prevent a new change to be deployed to production.
+
+## CI/CD Pipeline Components
+
+A typical CI/CD pipeline includes the following stages:
+
+1. **Source**: Code is committed to a version control system (Git, SVN, etc.)
+2. **Build**: Code is compiled, dependencies are resolved
+3. **Test**: Automated tests are run (unit tests, integration tests, etc.)
+4. **Deploy**: Application is deployed to staging/production environments
+5. **Monitor**: Application performance and errors are monitored
+
+## Popular CI/CD Tools
+
+### Jenkins
+
+Jenkins is an open-source automation server that enables developers to build, test, and deploy their software.
+
+```yaml
+# Example Jenkinsfile
+pipeline {
+ agent any
+
+ stages {
+ stage('Build') {
+ steps {
+ echo 'Building..'
+ sh 'npm install'
+ }
+ }
+ stage('Test') {
+ steps {
+ echo 'Testing..'
+ sh 'npm test'
+ }
+ }
+ stage('Deploy') {
+ steps {
+ echo 'Deploying....'
+ sh 'npm run deploy'
+ }
+ }
+ }
+}
+```
+
+### GitHub Actions
+
+GitHub Actions is a CI/CD platform that allows you to automate your build, test, and deployment pipeline directly from GitHub.
+
+```yaml
+# Example GitHub Actions workflow
+name: Node.js CI
+
+on:
+ push:
+ branches: [ main ]
+ pull_request:
+ branches: [ main ]
+
+jobs:
+ build:
+ runs-on: ubuntu-latest
+
+ steps:
+ - uses: actions/checkout@v2
+ - name: Use Node.js
+ uses: actions/setup-node@v1
+ with:
+ node-version: '14.x'
+ - name: Install dependencies
+ run: npm ci
+ - name: Run tests
+ run: npm test
+ - name: Deploy
+ if: github.ref == 'refs/heads/main'
+ run: npm run deploy
+```
+
+### GitLab CI/CD
+
+GitLab CI/CD is a part of GitLab that allows you to apply all the continuous methods (Continuous Integration, Delivery, and Deployment) to your software.
+
+```yaml
+# Example .gitlab-ci.yml
+stages:
+ - build
+ - test
+ - deploy
+
+build:
+ stage: build
+ script:
+ - echo "Building the app"
+ - npm install
+
+test:
+ stage: test
+ script:
+ - echo "Running tests"
+ - npm test
+
+deploy:
+ stage: deploy
+ script:
+ - echo "Deploying application"
+ - npm run deploy
+ only:
+ - main
+```
+
+### CircleCI
+
+CircleCI is a cloud-based CI/CD tool that automates the software development process.
+
+```yaml
+# Example CircleCI configuration
+version: 2.1
+jobs:
+ build:
+ docker:
+ - image: cimg/node:14.17
+ steps:
+ - checkout
+ - run: npm install
+ - run: npm test
+ - run: npm run deploy
+```
+
+## Best Practices for CI/CD
+
+1. **Automate Everything**: Automate as much of the software delivery process as possible.
+2. **Fail Fast**: Detect and address issues as early as possible in the development process.
+3. **Keep the Build Green**: A broken build should be the team's highest priority to fix.
+4. **Build Only Once**: Build artifacts once and promote the same artifacts through the pipeline.
+5. **Deploy the Same Way to Every Environment**: Use the same deployment process for all environments.
+6. **Smoke Test Your Deployments**: Run basic tests after deployment to verify the system is running correctly.
+7. **Keep Your CI/CD Pipeline Fast**: Aim for a pipeline that completes in less than 10 minutes.
+8. **Maintain Good Test Coverage**: Ensure your tests cover most of your codebase.
+
+## References
+
+- [Martin Fowler on Continuous Integration](https://martinfowler.com/articles/continuousIntegration.html)
+- [The DevOps Handbook](https://itrevolution.com/book/the-devops-handbook/)
+- [Continuous Delivery](https://continuousdelivery.com/)
+- [Jenkins Documentation](https://www.jenkins.io/doc/)
+- [GitHub Actions Documentation](https://docs.github.com/en/actions)
+- [GitLab CI/CD Documentation](https://docs.gitlab.com/ee/ci/)
+- [CircleCI Documentation](https://circleci.com/docs/)
diff --git a/docs/linux/bash-scripting.md b/docs/linux/bash-scripting.md
new file mode 100644
index 0000000..3173040
--- /dev/null
+++ b/docs/linux/bash-scripting.md
@@ -0,0 +1,325 @@
+# Bash Scripting
+
+Bash (Bourne Again SHell) is a command language interpreter that is widely used on various operating systems, and is the default shell on most Linux distributions.
+
+## Introduction to Bash Scripting
+
+Bash scripts are text files containing a series of commands that are executed by the Bash shell. They allow you to automate repetitive tasks, combine complex commands, and create custom utilities.
+
+## Basic Syntax
+
+### Creating a Bash Script
+
+1. Create a file with a `.sh` extension
+2. Add the shebang line at the top: `#!/bin/bash`
+3. Make the script executable: `chmod +x script.sh`
+4. Run the script: `./script.sh`
+
+### Hello World Example
+
+```bash
+#!/bin/bash
+# This is a comment
+echo "Hello, World!"
+```
+
+## Variables
+
+### Variable Declaration and Usage
+
+```bash
+#!/bin/bash
+
+# Variable declaration
+name="John"
+age=30
+
+# Using variables
+echo "Name: $name"
+echo "Age: $age"
+
+# Command substitution
+current_date=$(date)
+echo "Current date: $current_date"
+
+# Arithmetic operations
+result=$((10 + 5))
+echo "10 + 5 = $result"
+```
+
+### Special Variables
+
+| Variable | Description |
+|----------|-------------|
+| `$0` | The name of the script |
+| `$1` to `$9` | The first 9 arguments passed to the script |
+| `$#` | The number of arguments passed to the script |
+| `$@` | All arguments passed to the script |
+| `$?` | The exit status of the last command |
+| `$$` | The process ID of the current script |
+| `$USER` | The username of the user running the script |
+| `$HOSTNAME` | The hostname of the machine |
+| `$RANDOM` | A random number |
+| `$HOME` | The home directory of the user |
+
+## Control Structures
+
+### Conditional Statements
+
+#### If-Else Statement
+
+```bash
+#!/bin/bash
+
+age=25
+
+if [ $age -lt 18 ]; then
+ echo "You are a minor."
+elif [ $age -ge 18 ] && [ $age -lt 65 ]; then
+ echo "You are an adult."
+else
+ echo "You are a senior."
+fi
+```
+
+#### Case Statement
+
+```bash
+#!/bin/bash
+
+fruit="apple"
+
+case $fruit in
+ "apple")
+ echo "This is an apple."
+ ;;
+ "banana")
+ echo "This is a banana."
+ ;;
+ "orange")
+ echo "This is an orange."
+ ;;
+ *)
+ echo "Unknown fruit."
+ ;;
+esac
+```
+
+### Loops
+
+#### For Loop
+
+```bash
+#!/bin/bash
+
+# Simple for loop
+for i in 1 2 3 4 5; do
+ echo "Number: $i"
+done
+
+# For loop with range
+for i in {1..5}; do
+ echo "Number: $i"
+done
+
+# For loop with step
+for i in {1..10..2}; do
+ echo "Odd number: $i"
+done
+
+# For loop with command output
+for file in $(ls); do
+ echo "File: $file"
+done
+```
+
+#### While Loop
+
+```bash
+#!/bin/bash
+
+count=1
+
+while [ $count -le 5 ]; do
+ echo "Count: $count"
+ ((count++))
+done
+```
+
+#### Until Loop
+
+```bash
+#!/bin/bash
+
+count=1
+
+until [ $count -gt 5 ]; do
+ echo "Count: $count"
+ ((count++))
+done
+```
+
+## Functions
+
+### Function Definition and Usage
+
+```bash
+#!/bin/bash
+
+# Function definition
+greet() {
+ echo "Hello, $1!"
+}
+
+# Function with return value
+add() {
+ local result=$(($1 + $2))
+ echo $result
+}
+
+# Function calls
+greet "John"
+sum=$(add 5 3)
+echo "5 + 3 = $sum"
+```
+
+## Input and Output
+
+### Reading User Input
+
+```bash
+#!/bin/bash
+
+# Read a single value
+echo "Enter your name:"
+read name
+echo "Hello, $name!"
+
+# Read multiple values
+echo "Enter your first and last name:"
+read first_name last_name
+echo "Hello, $first_name $last_name!"
+
+# Read with prompt
+read -p "Enter your age: " age
+echo "You are $age years old."
+
+# Read password (hidden input)
+read -sp "Enter your password: " password
+echo -e "\nPassword received."
+```
+
+### File Input/Output
+
+```bash
+#!/bin/bash
+
+# Writing to a file
+echo "Hello, World!" > output.txt
+echo "This is a new line." >> output.txt
+
+# Reading from a file
+while IFS= read -r line; do
+ echo "Line: $line"
+done < input.txt
+
+# Process each line of a file
+cat input.txt | while read line; do
+ echo "Processing: $line"
+done
+```
+
+## Arrays
+
+### Array Operations
+
+```bash
+#!/bin/bash
+
+# Declare an array
+fruits=("apple" "banana" "orange" "grape")
+
+# Access array elements
+echo "First fruit: ${fruits[0]}"
+echo "All fruits: ${fruits[@]}"
+echo "Number of fruits: ${#fruits[@]}"
+
+# Iterate through array
+for fruit in "${fruits[@]}"; do
+ echo "Fruit: $fruit"
+done
+
+# Add element to array
+fruits+=("kiwi")
+
+# Remove element from array
+unset fruits[1]
+```
+
+## String Manipulation
+
+### String Operations
+
+```bash
+#!/bin/bash
+
+# String length
+str="Hello, World!"
+echo "Length: ${#str}"
+
+# Substring
+echo "Substring: ${str:7:5}"
+
+# String replacement
+echo "Replace: ${str/World/Bash}"
+
+# Convert to uppercase/lowercase
+echo "Uppercase: ${str^^}"
+echo "Lowercase: ${str,,}"
+```
+
+## Error Handling
+
+### Basic Error Handling
+
+```bash
+#!/bin/bash
+
+# Exit on error
+set -e
+
+# Custom error handling
+handle_error() {
+ echo "Error occurred at line $1"
+ exit 1
+}
+
+# Trap errors
+trap 'handle_error $LINENO' ERR
+
+# Check command success
+if ! command -v git &> /dev/null; then
+ echo "Git is not installed."
+ exit 1
+fi
+```
+
+## Best Practices
+
+1. **Use Shebang**: Always include `#!/bin/bash` at the top of your scripts.
+2. **Comments**: Add comments to explain complex logic.
+3. **Error Handling**: Implement proper error handling.
+4. **Indentation**: Use consistent indentation for readability.
+5. **Naming Conventions**: Use descriptive names for variables and functions.
+6. **Quoting Variables**: Always quote variables to handle spaces and special characters.
+7. **Exit Codes**: Return appropriate exit codes.
+8. **Modularity**: Break complex scripts into functions.
+9. **Debugging**: Use `set -x` for debugging.
+10. **Testing**: Test your scripts with different inputs.
+
+## References
+
+- [GNU Bash Manual](https://www.gnu.org/software/bash/manual/)
+- [Bash Guide for Beginners](https://tldp.org/LDP/Bash-Beginners-Guide/html/)
+- [Advanced Bash-Scripting Guide](https://tldp.org/LDP/abs/html/)
+- [ShellCheck](https://www.shellcheck.net/) - A shell script analysis tool
diff --git a/docs/system-design/microservices.md b/docs/system-design/microservices.md
new file mode 100644
index 0000000..df86b54
--- /dev/null
+++ b/docs/system-design/microservices.md
@@ -0,0 +1,467 @@
+# Microservices Architecture
+
+Microservices architecture is an architectural style that structures an application as a collection of small, loosely coupled services that can be developed, deployed, and scaled independently.
+
+## What are Microservices?
+
+Microservices are small, autonomous services that work together to form a complete application. Each microservice:
+
+- Focuses on a single business capability
+- Runs in its own process
+- Communicates via well-defined APIs
+- Can be deployed independently
+- Can be written in different programming languages
+- Can use different data storage technologies
+
+## Monolithic vs. Microservices Architecture
+
+| Aspect | Monolithic | Microservices |
+|--------|------------|---------------|
+| Structure | Single, unified codebase | Multiple, independent services |
+| Development | Simpler to develop initially | More complex initial setup |
+| Deployment | Deploy entire application | Deploy individual services |
+| Scaling | Scale entire application | Scale individual services as needed |
+| Technology | Single technology stack | Multiple technology stacks possible |
+| Team Structure | Larger teams working on same codebase | Smaller teams working on individual services |
+| Failure Impact | Single point of failure | Isolated failures |
+| Data Management | Shared database | Database per service |
+
+## Key Principles of Microservices
+
+1. **Single Responsibility**: Each service is responsible for a specific business capability.
+2. **Autonomy**: Services can be developed, deployed, and scaled independently.
+3. **Resilience**: Failure in one service should not cascade to others.
+4. **Decentralization**: Decentralized governance and data management.
+5. **Continuous Delivery**: Frequent, automated deployment of individual services.
+6. **Observability**: Comprehensive monitoring and logging.
+7. **Domain-Driven Design**: Services are designed around business domains.
+
+## Microservices Communication Patterns
+
+### Synchronous Communication
+
+#### REST API
+
+```json
+// Example REST API request
+GET /api/products/123
+Accept: application/json
+
+// Example response
+{
+ "id": "123",
+ "name": "Product Name",
+ "price": 19.99,
+ "category": "Electronics"
+}
+```
+
+#### gRPC
+
+```protobuf
+// Example gRPC service definition
+syntax = "proto3";
+
+service ProductService {
+ rpc GetProduct(ProductRequest) returns (Product);
+}
+
+message ProductRequest {
+ string id = 1;
+}
+
+message Product {
+ string id = 1;
+ string name = 2;
+ double price = 3;
+ string category = 4;
+}
+```
+
+### Asynchronous Communication
+
+#### Message Queue
+
+```javascript
+// Example message producer (Node.js with RabbitMQ)
+const amqp = require('amqplib');
+
+async function sendOrderCreatedEvent(order) {
+ const connection = await amqp.connect('amqp://localhost');
+ const channel = await connection.createChannel();
+
+ const queue = 'order_events';
+ const message = JSON.stringify({
+ type: 'ORDER_CREATED',
+ data: order
+ });
+
+ await channel.assertQueue(queue, { durable: true });
+ channel.sendToQueue(queue, Buffer.from(message));
+
+ console.log(`Sent: ${message}`);
+
+ setTimeout(() => {
+ connection.close();
+ }, 500);
+}
+```
+
+```javascript
+// Example message consumer (Node.js with RabbitMQ)
+const amqp = require('amqplib');
+
+async function processOrderEvents() {
+ const connection = await amqp.connect('amqp://localhost');
+ const channel = await connection.createChannel();
+
+ const queue = 'order_events';
+
+ await channel.assertQueue(queue, { durable: true });
+ console.log(`Waiting for messages in ${queue}`);
+
+ channel.consume(queue, (msg) => {
+ const event = JSON.parse(msg.content.toString());
+ console.log(`Received: ${event.type}`);
+
+ if (event.type === 'ORDER_CREATED') {
+ // Process the order
+ processOrder(event.data);
+ }
+
+ channel.ack(msg);
+ });
+}
+```
+
+#### Event Streaming
+
+```java
+// Example Kafka producer (Java)
+Properties props = new Properties();
+props.put("bootstrap.servers", "localhost:9092");
+props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
+props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
+
+Producer producer = new KafkaProducer<>(props);
+
+String topic = "order-events";
+String key = order.getId();
+String value = objectMapper.writeValueAsString(order);
+
+ProducerRecord record = new ProducerRecord<>(topic, key, value);
+producer.send(record);
+producer.close();
+```
+
+```java
+// Example Kafka consumer (Java)
+Properties props = new Properties();
+props.put("bootstrap.servers", "localhost:9092");
+props.put("group.id", "order-processing-group");
+props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
+props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
+
+Consumer consumer = new KafkaConsumer<>(props);
+consumer.subscribe(Arrays.asList("order-events"));
+
+while (true) {
+ ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
+ for (ConsumerRecord record : records) {
+ String key = record.key();
+ String value = record.value();
+
+ Order order = objectMapper.readValue(value, Order.class);
+ processOrder(order);
+ }
+}
+```
+
+## Service Discovery and API Gateway
+
+### Service Discovery
+
+```yaml
+# Example Consul service registration
+{
+ "service": {
+ "name": "product-service",
+ "id": "product-service-1",
+ "tags": ["api", "v1"],
+ "address": "10.0.0.1",
+ "port": 8080,
+ "checks": [
+ {
+ "http": "http://10.0.0.1:8080/health",
+ "interval": "10s"
+ }
+ ]
+ }
+}
+```
+
+### API Gateway
+
+```yaml
+# Example Kong API Gateway configuration
+services:
+ - name: product-service
+ url: http://product-service:8080
+ routes:
+ - name: product-routes
+ paths:
+ - /api/products
+ strip_path: true
+ plugins:
+ - name: rate-limiting
+ config:
+ minute: 100
+ - name: jwt
+```
+
+## Data Management in Microservices
+
+### Database per Service
+
+```yaml
+# Example docker-compose.yml for multiple databases
+version: '3'
+services:
+ product-service:
+ build: ./product-service
+ depends_on:
+ - product-db
+ environment:
+ - DB_HOST=product-db
+ - DB_PORT=5432
+ - DB_NAME=productdb
+
+ product-db:
+ image: postgres:13
+ environment:
+ - POSTGRES_DB=productdb
+ - POSTGRES_USER=user
+ - POSTGRES_PASSWORD=password
+ volumes:
+ - product-db-data:/var/lib/postgresql/data
+
+ order-service:
+ build: ./order-service
+ depends_on:
+ - order-db
+ environment:
+ - DB_HOST=order-db
+ - DB_PORT=27017
+ - DB_NAME=orderdb
+
+ order-db:
+ image: mongo:4.4
+ environment:
+ - MONGO_INITDB_DATABASE=orderdb
+ volumes:
+ - order-db-data:/data/db
+
+volumes:
+ product-db-data:
+ order-db-data:
+```
+
+### CQRS Pattern
+
+```csharp
+// Command side
+public class CreateOrderCommand
+{
+ public string CustomerId { get; set; }
+ public List Items { get; set; }
+}
+
+public class OrderCommandHandler
+{
+ private readonly IOrderRepository _repository;
+ private readonly IEventBus _eventBus;
+
+ public OrderCommandHandler(IOrderRepository repository, IEventBus eventBus)
+ {
+ _repository = repository;
+ _eventBus = eventBus;
+ }
+
+ public async Task Handle(CreateOrderCommand command)
+ {
+ var order = new Order(Guid.NewGuid(), command.CustomerId, command.Items);
+ await _repository.SaveAsync(order);
+
+ await _eventBus.PublishAsync(new OrderCreatedEvent
+ {
+ OrderId = order.Id,
+ CustomerId = order.CustomerId,
+ Items = order.Items
+ });
+ }
+}
+
+// Query side
+public class OrderQueryService
+{
+ private readonly IOrderReadModel _readModel;
+
+ public OrderQueryService(IOrderReadModel readModel)
+ {
+ _readModel = readModel;
+ }
+
+ public async Task GetOrderAsync(Guid orderId)
+ {
+ return await _readModel.GetOrderAsync(orderId);
+ }
+
+ public async Task> GetCustomerOrdersAsync(string customerId)
+ {
+ return await _readModel.GetCustomerOrdersAsync(customerId);
+ }
+}
+```
+
+## Deploying Microservices
+
+### Docker Containers
+
+```dockerfile
+# Example Dockerfile for a microservice
+FROM node:14-alpine
+
+WORKDIR /app
+
+COPY package*.json ./
+RUN npm install --production
+
+COPY . .
+
+EXPOSE 8080
+
+CMD ["node", "server.js"]
+```
+
+### Kubernetes
+
+```yaml
+# Example Kubernetes deployment for a microservice
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: product-service
+ labels:
+ app: product-service
+spec:
+ replicas: 3
+ selector:
+ matchLabels:
+ app: product-service
+ template:
+ metadata:
+ labels:
+ app: product-service
+ spec:
+ containers:
+ - name: product-service
+ image: my-registry/product-service:1.0.0
+ ports:
+ - containerPort: 8080
+ env:
+ - name: DB_HOST
+ value: product-db-service
+ - name: DB_PORT
+ value: "5432"
+ - name: DB_NAME
+ value: productdb
+ livenessProbe:
+ httpGet:
+ path: /health
+ port: 8080
+ initialDelaySeconds: 30
+ periodSeconds: 10
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: product-service
+spec:
+ selector:
+ app: product-service
+ ports:
+ - port: 80
+ targetPort: 8080
+ type: ClusterIP
+```
+
+## Monitoring and Observability
+
+### Distributed Tracing
+
+```java
+// Example using Spring Cloud Sleuth and Zipkin
+@RestController
+public class ProductController {
+
+ private final ProductService productService;
+
+ @Autowired
+ public ProductController(ProductService productService) {
+ this.productService = productService;
+ }
+
+ @GetMapping("/products/{id}")
+ public Product getProduct(@PathVariable String id) {
+ // Tracing is automatically handled by Sleuth
+ return productService.getProduct(id);
+ }
+}
+```
+
+### Metrics Collection
+
+```yaml
+# Example Prometheus configuration
+global:
+ scrape_interval: 15s
+
+scrape_configs:
+ - job_name: 'product-service'
+ metrics_path: '/actuator/prometheus'
+ static_configs:
+ - targets: ['product-service:8080']
+
+ - job_name: 'order-service'
+ metrics_path: '/actuator/prometheus'
+ static_configs:
+ - targets: ['order-service:8080']
+```
+
+## Challenges and Best Practices
+
+### Challenges
+
+1. **Distributed System Complexity**: Debugging and testing become more difficult.
+2. **Data Consistency**: Maintaining consistency across services is challenging.
+3. **Service Boundaries**: Defining the right service boundaries requires domain expertise.
+4. **Operational Overhead**: More services mean more infrastructure to manage.
+5. **Network Latency**: Communication between services adds latency.
+
+### Best Practices
+
+1. **Start Monolithic**: Begin with a monolith and extract microservices as needed.
+2. **Design for Failure**: Implement circuit breakers, retries, and fallbacks.
+3. **Automate Everything**: Use CI/CD pipelines for all services.
+4. **Implement Monitoring**: Comprehensive logging, metrics, and tracing.
+5. **Use Containers**: Containerize services for consistency across environments.
+6. **API Versioning**: Implement proper API versioning to manage changes.
+7. **Documentation**: Maintain clear documentation for all services and APIs.
+8. **Testing**: Implement comprehensive testing strategies, including contract testing.
+
+## References
+
+- [Microservices.io](https://microservices.io/)
+- [Martin Fowler on Microservices](https://martinfowler.com/articles/microservices.html)
+- [Sam Newman - Building Microservices](https://samnewman.io/books/building_microservices/)
+- [Chris Richardson - Microservices Patterns](https://microservices.io/book)
diff --git a/docs/testing/unit-testing.md b/docs/testing/unit-testing.md
new file mode 100644
index 0000000..600021c
--- /dev/null
+++ b/docs/testing/unit-testing.md
@@ -0,0 +1,467 @@
+# Unit Testing
+
+Unit testing is a software testing method where individual units or components of a software are tested in isolation from the rest of the system.
+
+## What is Unit Testing?
+
+A unit test verifies that a small, isolated piece of code (a "unit") behaves exactly as the developer expects. Units are typically:
+
+- Individual functions or methods
+- Classes
+- Modules or components
+
+The goal is to validate that each unit of the software performs as designed.
+
+## Benefits of Unit Testing
+
+- **Early Bug Detection**: Catch bugs early in the development cycle
+- **Facilitates Changes**: Makes it easier to refactor code and add new features
+- **Documentation**: Tests serve as documentation for how the code should behave
+- **Design Improvement**: Encourages better software design and modularity
+- **Confidence**: Provides confidence that the code works as expected
+- **Reduces Costs**: Cheaper to fix bugs found during unit testing than later stages
+
+## Unit Testing Principles
+
+### FIRST Principles
+
+- **Fast**: Tests should run quickly
+- **Independent**: Tests should not depend on each other
+- **Repeatable**: Tests should yield the same results every time
+- **Self-validating**: Tests should automatically determine if they pass or fail
+- **Timely**: Tests should be written at the right time (ideally before the code)
+
+### AAA Pattern
+
+- **Arrange**: Set up the test conditions
+- **Act**: Execute the code being tested
+- **Assert**: Verify the result is as expected
+
+## Unit Testing Frameworks
+
+### JavaScript (Jest)
+
+```javascript
+// math.js
+function add(a, b) {
+ return a + b;
+}
+
+function subtract(a, b) {
+ return a - b;
+}
+
+module.exports = { add, subtract };
+
+// math.test.js
+const { add, subtract } = require('./math');
+
+describe('Math functions', () => {
+ test('add should correctly add two numbers', () => {
+ // Arrange
+ const a = 5;
+ const b = 3;
+
+ // Act
+ const result = add(a, b);
+
+ // Assert
+ expect(result).toBe(8);
+ });
+
+ test('subtract should correctly subtract two numbers', () => {
+ // Arrange
+ const a = 5;
+ const b = 3;
+
+ // Act
+ const result = subtract(a, b);
+
+ // Assert
+ expect(result).toBe(2);
+ });
+});
+```
+
+### Python (pytest)
+
+```python
+# math_utils.py
+def add(a, b):
+ return a + b
+
+def subtract(a, b):
+ return a - b
+
+# test_math_utils.py
+import pytest
+from math_utils import add, subtract
+
+def test_add():
+ # Arrange
+ a = 5
+ b = 3
+
+ # Act
+ result = add(a, b)
+
+ # Assert
+ assert result == 8
+
+def test_subtract():
+ # Arrange
+ a = 5
+ b = 3
+
+ # Act
+ result = subtract(a, b)
+
+ # Assert
+ assert result == 2
+```
+
+### Java (JUnit)
+
+```java
+// MathUtils.java
+public class MathUtils {
+ public int add(int a, int b) {
+ return a + b;
+ }
+
+ public int subtract(int a, int b) {
+ return a - b;
+ }
+}
+
+// MathUtilsTest.java
+import static org.junit.jupiter.api.Assertions.assertEquals;
+import org.junit.jupiter.api.Test;
+
+public class MathUtilsTest {
+
+ @Test
+ public void testAdd() {
+ // Arrange
+ MathUtils mathUtils = new MathUtils();
+ int a = 5;
+ int b = 3;
+
+ // Act
+ int result = mathUtils.add(a, b);
+
+ // Assert
+ assertEquals(8, result);
+ }
+
+ @Test
+ public void testSubtract() {
+ // Arrange
+ MathUtils mathUtils = new MathUtils();
+ int a = 5;
+ int b = 3;
+
+ // Act
+ int result = mathUtils.subtract(a, b);
+
+ // Assert
+ assertEquals(2, result);
+ }
+}
+```
+
+### C# (xUnit)
+
+```csharp
+// MathUtils.cs
+public class MathUtils
+{
+ public int Add(int a, int b)
+ {
+ return a + b;
+ }
+
+ public int Subtract(int a, int b)
+ {
+ return a - b;
+ }
+}
+
+// MathUtilsTests.cs
+using Xunit;
+
+public class MathUtilsTests
+{
+ [Fact]
+ public void Add_ShouldCorrectlyAddTwoNumbers()
+ {
+ // Arrange
+ var mathUtils = new MathUtils();
+ int a = 5;
+ int b = 3;
+
+ // Act
+ int result = mathUtils.Add(a, b);
+
+ // Assert
+ Assert.Equal(8, result);
+ }
+
+ [Fact]
+ public void Subtract_ShouldCorrectlySubtractTwoNumbers()
+ {
+ // Arrange
+ var mathUtils = new MathUtils();
+ int a = 5;
+ int b = 3;
+
+ // Act
+ int result = mathUtils.Subtract(a, b);
+
+ // Assert
+ Assert.Equal(2, result);
+ }
+}
+```
+
+## Test Doubles
+
+Test doubles are objects that replace real components in tests to isolate the code being tested.
+
+### Types of Test Doubles
+
+#### Dummy
+
+Objects that are passed around but never actually used.
+
+```javascript
+// JavaScript example
+function createUser(user, logger) {
+ // logger is not used in this test
+ return { id: 123, ...user };
+}
+
+test('createUser should add an ID to the user', () => {
+ // Arrange
+ const dummyLogger = {}; // Dummy object that's never used
+ const user = { name: 'John' };
+
+ // Act
+ const result = createUser(user, dummyLogger);
+
+ // Assert
+ expect(result.id).toBeDefined();
+ expect(result.name).toBe('John');
+});
+```
+
+#### Stub
+
+Objects that provide predefined answers to calls made during the test.
+
+```java
+// Java example
+public interface WeatherService {
+ int getCurrentTemperature(String city);
+}
+
+// Stub implementation
+public class WeatherServiceStub implements WeatherService {
+ @Override
+ public int getCurrentTemperature(String city) {
+ return 25; // Always returns 25°C regardless of the city
+ }
+}
+
+@Test
+public void testWeatherReporter() {
+ // Arrange
+ WeatherService stubService = new WeatherServiceStub();
+ WeatherReporter reporter = new WeatherReporter(stubService);
+
+ // Act
+ String report = reporter.generateReport("London");
+
+ // Assert
+ assertEquals("Current temperature in London: 25°C", report);
+}
+```
+
+#### Spy
+
+Objects that record calls made to them.
+
+```python
+# Python example
+class EmailServiceSpy:
+ def __init__(self):
+ self.emails_sent = []
+
+ def send_email(self, to, subject, body):
+ self.emails_sent.append({
+ 'to': to,
+ 'subject': subject,
+ 'body': body
+ })
+
+def test_user_registration_sends_welcome_email():
+ # Arrange
+ email_service = EmailServiceSpy()
+ user_service = UserService(email_service)
+
+ # Act
+ user_service.register("john@example.com", "password123")
+
+ # Assert
+ assert len(email_service.emails_sent) == 1
+ assert email_service.emails_sent[0]['to'] == "john@example.com"
+ assert "Welcome" in email_service.emails_sent[0]['subject']
+```
+
+#### Mock
+
+Objects that verify that specific methods were called with specific arguments.
+
+```csharp
+// C# example with Moq
+[Fact]
+public void Register_ShouldSendWelcomeEmail()
+{
+ // Arrange
+ var mockEmailService = new Mock();
+ var userService = new UserService(mockEmailService.Object);
+
+ // Act
+ userService.Register("john@example.com", "password123");
+
+ // Assert
+ mockEmailService.Verify(
+ x => x.SendEmail(
+ "john@example.com",
+ It.Is(s => s.Contains("Welcome")),
+ It.IsAny()
+ ),
+ Times.Once
+ );
+}
+```
+
+#### Fake
+
+Objects that have working implementations but are not suitable for production.
+
+```javascript
+// JavaScript example
+class FakeUserRepository {
+ constructor() {
+ this.users = [];
+ this.nextId = 1;
+ }
+
+ create(userData) {
+ const user = { id: this.nextId++, ...userData };
+ this.users.push(user);
+ return user;
+ }
+
+ findById(id) {
+ return this.users.find(user => user.id === id);
+ }
+}
+
+test('UserService should create a user', () => {
+ // Arrange
+ const fakeRepo = new FakeUserRepository();
+ const userService = new UserService(fakeRepo);
+
+ // Act
+ const user = userService.createUser('John', 'john@example.com');
+
+ // Assert
+ expect(user.id).toBe(1);
+ expect(user.name).toBe('John');
+ expect(fakeRepo.findById(1)).toEqual(user);
+});
+```
+
+## Test Coverage
+
+Test coverage measures how much of your code is executed during tests.
+
+### Coverage Metrics
+
+- **Line Coverage**: Percentage of lines executed during tests
+- **Branch Coverage**: Percentage of branches (if/else, switch) executed during tests
+- **Function Coverage**: Percentage of functions called during tests
+- **Statement Coverage**: Percentage of statements executed during tests
+
+### Example Coverage Report (Jest)
+
+```
+--------------------|---------|----------|---------|---------|-------------------
+File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s
+--------------------|---------|----------|---------|---------|-------------------
+All files | 85.71 | 66.67 | 100 | 85.71 |
+ math.js | 100 | 100 | 100 | 100 |
+ string-utils.js | 71.43 | 33.33 | 100 | 71.43 | 15-18
+--------------------|---------|----------|---------|---------|-------------------
+```
+
+## Best Practices for Unit Testing
+
+1. **Test One Thing at a Time**: Each test should verify one specific behavior.
+2. **Keep Tests Simple**: Tests should be easy to understand and maintain.
+3. **Use Descriptive Test Names**: Names should clearly describe what is being tested.
+4. **Isolate the Unit**: Use test doubles to isolate the unit from its dependencies.
+5. **Test Edge Cases**: Include tests for boundary conditions and error cases.
+6. **Don't Test the Framework**: Focus on testing your code, not the framework or language.
+7. **Maintain Test Independence**: Tests should not depend on each other or run in a specific order.
+8. **Avoid Logic in Tests**: Tests should be straightforward with minimal logic.
+9. **Write Tests First (TDD)**: Consider writing tests before implementing the code.
+10. **Refactor Tests**: Keep tests clean and maintainable, just like production code.
+
+## Test-Driven Development (TDD)
+
+TDD is a development process where tests are written before the code. The cycle is:
+
+1. **Red**: Write a failing test
+2. **Green**: Write the minimal code to make the test pass
+3. **Refactor**: Improve the code while keeping the tests passing
+
+### TDD Example (JavaScript)
+
+```javascript
+// Step 1: Write a failing test
+test('isPalindrome should return true for palindromes', () => {
+ expect(isPalindrome('racecar')).toBe(true);
+});
+
+// Step 2: Write minimal code to make it pass
+function isPalindrome(str) {
+ return str === str.split('').reverse().join('');
+}
+
+// Step 3: Add more tests
+test('isPalindrome should return false for non-palindromes', () => {
+ expect(isPalindrome('hello')).toBe(false);
+});
+
+test('isPalindrome should be case insensitive', () => {
+ expect(isPalindrome('Racecar')).toBe(true);
+});
+
+// Step 4: Refactor the code
+function isPalindrome(str) {
+ const normalized = str.toLowerCase();
+ return normalized === normalized.split('').reverse().join('');
+}
+```
+
+## References
+
+- [Martin Fowler on Unit Testing](https://martinfowler.com/bliki/UnitTest.html)
+- [Test-Driven Development by Example](https://www.amazon.com/Test-Driven-Development-Kent-Beck/dp/0321146530)
+- [Jest Documentation](https://jestjs.io/docs/getting-started)
+- [pytest Documentation](https://docs.pytest.org/)
+- [JUnit Documentation](https://junit.org/junit5/docs/current/user-guide/)
+- [xUnit Documentation](https://xunit.net/docs/getting-started/netcore/cmdline)
diff --git a/i18n/es/init.txt b/i18n/es/init.txt
new file mode 100644
index 0000000..e69de29
diff --git a/i18n/vi/algorithms/graph-traversal_vi.md b/i18n/vi/algorithms/graph-traversal_vi.md
new file mode 100644
index 0000000..d41c6f1
--- /dev/null
+++ b/i18n/vi/algorithms/graph-traversal_vi.md
@@ -0,0 +1,148 @@
+# Các Thuật Toán Duyệt Đồ Thị (Graph Traversal Algorithms)
+
+Các thuật toán duyệt đồ thị là những kỹ thuật cơ bản được sử dụng để thăm mỗi đỉnh trong một đồ thị. Chúng là nền tảng cho nhiều thuật toán đồ thị phức tạp hơn.
+
+## Mục Lục
+
+- [Tìm Kiếm Theo Chiều Rộng (BFS)](#tìm-kiếm-theo-chiều-rộng-bfs)
+- [Tìm Kiếm Theo Chiều Sâu (DFS)](#tìm-kiếm-theo-chiều-sâu-dfs)
+- [So Sánh BFS và DFS](#so-sánh-bfs-và-dfs)
+- [Ứng Dụng](#ứng-dụng)
+- [Độ Phức Tạp Về Thời Gian và Không Gian](#độ-phức-tạp-về-thời-gian-và-không-gian)
+
+## Tìm Kiếm Theo Chiều Rộng (BFS)
+
+Tìm kiếm theo chiều rộng là một thuật toán duyệt đồ thị khám phá tất cả các đỉnh ở mức độ sâu hiện tại trước khi di chuyển đến các đỉnh ở mức độ sâu tiếp theo.
+
+### Cách Hoạt Động của BFS
+
+1. Bắt đầu từ một đỉnh nguồn và đánh dấu nó là đã thăm
+2. Thăm tất cả các đỉnh kề chưa thăm và đánh dấu chúng là đã thăm
+3. Đối với mỗi đỉnh kề đó, thăm tất cả các đỉnh kề chưa thăm của chúng
+4. Lặp lại cho đến khi tất cả các đỉnh đã được thăm
+
+### Cài Đặt
+
+```python
+from collections import deque
+
+def bfs(graph, start):
+ visited = set([start])
+ queue = deque([start])
+ result = []
+
+ while queue:
+ vertex = queue.popleft()
+ result.append(vertex)
+
+ for neighbor in graph[vertex]:
+ if neighbor not in visited:
+ visited.add(neighbor)
+ queue.append(neighbor)
+
+ return result
+
+# Ví dụ sử dụng
+graph = {
+ 'A': ['B', 'C'],
+ 'B': ['A', 'D', 'E'],
+ 'C': ['A', 'F'],
+ 'D': ['B'],
+ 'E': ['B', 'F'],
+ 'F': ['C', 'E']
+}
+
+print(bfs(graph, 'A')) # Kết quả: ['A', 'B', 'C', 'D', 'E', 'F']
+```
+
+## Tìm Kiếm Theo Chiều Sâu (DFS)
+
+Tìm kiếm theo chiều sâu là một thuật toán duyệt đồ thị khám phá càng xa càng tốt dọc theo mỗi nhánh trước khi quay lui.
+
+### Cách Hoạt Động của DFS
+
+1. Bắt đầu từ một đỉnh nguồn và đánh dấu nó là đã thăm
+2. Đệ quy thăm một trong các đỉnh kề chưa thăm của nó
+3. Tiếp tục quá trình này, đi sâu hơn vào đồ thị
+4. Khi bạn đến một đỉnh không có đỉnh kề chưa thăm, quay lui
+
+### Cài Đặt
+
+```python
+def dfs_recursive(graph, vertex, visited=None, result=None):
+ if visited is None:
+ visited = set()
+ if result is None:
+ result = []
+
+ visited.add(vertex)
+ result.append(vertex)
+
+ for neighbor in graph[vertex]:
+ if neighbor not in visited:
+ dfs_recursive(graph, neighbor, visited, result)
+
+ return result
+
+# Cài đặt lặp sử dụng ngăn xếp
+def dfs_iterative(graph, start):
+ visited = set()
+ stack = [start]
+ result = []
+
+ while stack:
+ vertex = stack.pop()
+ if vertex not in visited:
+ visited.add(vertex)
+ result.append(vertex)
+
+ # Thêm các đỉnh kề theo thứ tự ngược lại để mô phỏng DFS đệ quy
+ for neighbor in reversed(graph[vertex]):
+ if neighbor not in visited:
+ stack.append(neighbor)
+
+ return result
+
+# Ví dụ sử dụng (cùng đồ thị như ví dụ BFS)
+print(dfs_recursive(graph, 'A')) # Kết quả có thể là: ['A', 'B', 'D', 'E', 'F', 'C']
+print(dfs_iterative(graph, 'A')) # Kết quả tương tự, có thể thay đổi tùy thuộc vào thứ tự đỉnh kề
+```
+
+## So Sánh BFS và DFS
+
+| Khía cạnh | BFS | DFS |
+|-----------|-----|-----|
+| Cấu trúc dữ liệu | Hàng đợi (Queue) | Ngăn xếp (Stack) hoặc đệ quy |
+| Độ phức tạp không gian | O(b^d) với b là hệ số phân nhánh và d là khoảng cách từ nguồn | O(h) với h là chiều cao của cây |
+| Tính đầy đủ | Đầy đủ (tìm tất cả các đỉnh ở độ sâu nhất định trước khi đi sâu hơn) | Không đầy đủ cho đồ thị vô hạn |
+| Tính tối ưu | Tối ưu cho đồ thị không có trọng số | Không tối ưu nói chung |
+| Trường hợp sử dụng | Đường đi ngắn nhất trong đồ thị không trọng số, duyệt theo cấp | Sắp xếp tô-pô, phát hiện chu trình, tìm đường đi |
+
+## Ứng Dụng
+
+- **Ứng Dụng của BFS**:
+ - Tìm đường đi ngắn nhất trong đồ thị không trọng số
+ - Tìm tất cả các đỉnh trong một thành phần liên thông
+ - Kiểm tra tính hai phía của đồ thị
+ - Bộ thu thập thông tin web (Web crawlers)
+ - Tính năng mạng xã hội (ví dụ: "Bạn bè trong vòng 2 kết nối")
+
+- **Ứng Dụng của DFS**:
+ - Sắp xếp tô-pô
+ - Tìm thành phần liên thông mạnh
+ - Giải các câu đố chỉ có một lời giải (ví dụ: mê cung)
+ - Phát hiện chu trình
+ - Tìm đường đi trong trò chơi và câu đố
+
+## Độ Phức Tạp Về Thời Gian và Không Gian
+
+Cả BFS và DFS đều có độ phức tạp thời gian là O(V + E) với V là số đỉnh và E là số cạnh. Điều này là do trong trường hợp xấu nhất, mỗi đỉnh và mỗi cạnh sẽ được khám phá một lần.
+
+Độ phức tạp không gian:
+- BFS: O(V) trong trường hợp xấu nhất khi tất cả các đỉnh được lưu trữ trong hàng đợi
+- DFS: O(h) với h là độ sâu tối đa của ngăn xếp đệ quy (có thể là O(V) trong trường hợp xấu nhất)
+
+## Tài Liệu Tham Khảo
+
+1. Cormen, T. H., Leiserson, C. E., Rivest, R. L., & Stein, C. (2009). Introduction to Algorithms (3rd ed.). MIT Press.
+2. Sedgewick, R., & Wayne, K. (2011). Algorithms (4th ed.). Addison-Wesley Professional.
\ No newline at end of file
diff --git a/i18n/vi/databases/relational_vi.md b/i18n/vi/databases/relational_vi.md
new file mode 100644
index 0000000..6647b44
--- /dev/null
+++ b/i18n/vi/databases/relational_vi.md
@@ -0,0 +1,117 @@
+# Cơ sở dữ liệu quan hệ
+
+Cơ sở dữ liệu quan hệ là tập hợp dữ liệu có tổ chức lưu trữ thông tin trong các bảng với hàng và cột. Chúng tuân theo mô hình quan hệ do Edgar F. Codd đề xuất vào năm 1970, nhấn mạnh mối quan hệ giữa các thực thể dữ liệu.
+
+## Khái niệm cốt lõi
+
+### Bảng (Relations)
+
+Cấu trúc cơ bản trong cơ sở dữ liệu quan hệ:
+- Mỗi **bảng** đại diện cho một loại thực thể (ví dụ: khách hàng, sản phẩm)
+- Mỗi **hàng** (tuple) đại diện cho một thể hiện của thực thể đó
+- Mỗi **cột** (thuộc tính) đại diện cho một thuộc tính của thực thể đó
+
+### Khóa
+
+Khóa thiết lập mối quan hệ và đảm bảo tính toàn vẹn dữ liệu:
+
+- **Khóa chính (Primary Key)**: Xác định duy nhất mỗi bản ghi trong bảng
+- **Khóa ngoại (Foreign Key)**: Tham chiếu đến khóa chính trong bảng khác, thiết lập mối quan hệ
+- **Khóa tổng hợp (Composite Key)**: Kết hợp nhiều cột để tạo thành định danh duy nhất
+- **Khóa ứng viên (Candidate Key)**: Cột hoặc tập hợp các cột có thể đóng vai trò làm khóa chính
+
+### Lược đồ (Schema)
+
+Lược đồ xác định cấu trúc của cơ sở dữ liệu:
+- Định nghĩa bảng
+- Kiểu dữ liệu và ràng buộc cột
+- Mối quan hệ giữa các bảng
+
+## SQL (Ngôn ngữ truy vấn có cấu trúc)
+
+SQL là ngôn ngữ tiêu chuẩn để tương tác với cơ sở dữ liệu quan hệ.
+
+### Các lệnh SQL cơ bản
+
+```sql
+-- Tạo bảng
+CREATE TABLE customers (
+ customer_id INT PRIMARY KEY,
+ name VARCHAR(100),
+ email VARCHAR(100),
+ signup_date DATE
+);
+
+-- Chèn dữ liệu
+INSERT INTO customers (customer_id, name, email, signup_date)
+VALUES (1, 'Nguyễn Văn A', 'nguyenvana@example.com', '2023-01-15');
+
+-- Truy vấn dữ liệu
+SELECT * FROM customers WHERE signup_date > '2023-01-01';
+
+-- Cập nhật dữ liệu
+UPDATE customers SET email = 'nguyenvana.new@example.com' WHERE customer_id = 1;
+
+-- Xóa dữ liệu
+DELETE FROM customers WHERE customer_id = 1;
+```
+
+## Chuẩn hóa
+
+Chuẩn hóa là quá trình tổ chức dữ liệu để giảm dư thừa và cải thiện tính toàn vẹn dữ liệu:
+
+- **Dạng chuẩn 1 (1NF)**: Loại bỏ các cột trùng lặp và tạo bảng riêng cho dữ liệu liên quan
+- **Dạng chuẩn 2 (2NF)**: Đáp ứng yêu cầu 1NF và loại bỏ phụ thuộc một phần
+- **Dạng chuẩn 3 (3NF)**: Đáp ứng yêu cầu 2NF và loại bỏ phụ thuộc bắc cầu
+
+## Tính chất ACID
+
+Các giao dịch trong cơ sở dữ liệu quan hệ tuân theo tính chất ACID:
+
+- **Tính nguyên tử (Atomicity)**: Giao dịch là các hoạt động tất cả hoặc không có gì
+- **Tính nhất quán (Consistency)**: Giao dịch đưa cơ sở dữ liệu từ trạng thái hợp lệ này sang trạng thái hợp lệ khác
+- **Tính cô lập (Isolation)**: Các giao dịch đồng thời không ảnh hưởng đến nhau
+- **Tính bền vững (Durability)**: Giao dịch hoàn thành vẫn tồn tại ngay cả khi hệ thống gặp sự cố
+
+## Các hệ thống cơ sở dữ liệu quan hệ phổ biến
+
+- **MySQL**: Mã nguồn mở, được sử dụng rộng rãi cho các ứng dụng web
+- **PostgreSQL**: Cơ sở dữ liệu mã nguồn mở nâng cao với nhiều tính năng mở rộng
+- **Oracle Database**: Cơ sở dữ liệu thương mại cấp doanh nghiệp
+- **Microsoft SQL Server**: Giải pháp cơ sở dữ liệu thương mại của Microsoft
+- **SQLite**: Động cơ cơ sở dữ liệu nhẹ, không cần máy chủ
+
+## Chỉ mục (Indexes)
+
+Chỉ mục tăng tốc các hoạt động truy xuất dữ liệu:
+- Tương tự như chỉ mục sách
+- Cải thiện hiệu suất truy vấn nhưng tạo thêm chi phí cho các hoạt động ghi
+- Các loại bao gồm chỉ mục B-tree, hash, và bitmap
+
+## Joins (Kết hợp)
+
+Joins kết hợp các bản ghi từ hai hoặc nhiều bảng:
+- **INNER JOIN**: Trả về các bản ghi có giá trị khớp trong cả hai bảng
+- **LEFT JOIN**: Trả về tất cả bản ghi từ bảng bên trái và các bản ghi khớp từ bảng bên phải
+- **RIGHT JOIN**: Trả về tất cả bản ghi từ bảng bên phải và các bản ghi khớp từ bảng bên trái
+- **FULL JOIN**: Trả về tất cả bản ghi khi có sự khớp trong một trong hai bảng
+
+```sql
+SELECT customers.name, orders.order_date
+FROM customers
+INNER JOIN orders ON customers.customer_id = orders.customer_id;
+```
+
+## Khi nào sử dụng cơ sở dữ liệu quan hệ
+
+Cơ sở dữ liệu quan hệ lý tưởng cho:
+- Dữ liệu có cấu trúc với mối quan hệ rõ ràng
+- Ứng dụng yêu cầu truy vấn phức tạp và giao dịch
+- Hệ thống mà tính toàn vẹn dữ liệu là rất quan trọng
+- Các tình huống mà tính nhất quán quan trọng hơn tốc độ
+
+## Tài liệu tham khảo
+
+- Codd, E.F. (1970). "A Relational Model of Data for Large Shared Data Banks"
+- Date, C.J. "An Introduction to Database Systems"
+- Garcia-Molina, H., Ullman, J.D., & Widom, J. "Database Systems: The Complete Book"
\ No newline at end of file
diff --git a/i18n/vi/design-patterns/factory_vi.md b/i18n/vi/design-patterns/factory_vi.md
new file mode 100644
index 0000000..63ec969
--- /dev/null
+++ b/i18n/vi/design-patterns/factory_vi.md
@@ -0,0 +1,476 @@
+# Mẫu thiết kế Factory
+
+Mẫu Factory là một mẫu thiết kế tạo đối tượng cung cấp giao diện để tạo đối tượng trong lớp cha, nhưng cho phép các lớp con thay đổi loại đối tượng sẽ được tạo.
+
+## Mục đích
+
+- Tạo đối tượng mà không để lộ logic khởi tạo cho client
+- Tham chiếu đến các đối tượng mới tạo thông qua một giao diện chung
+- Tách biệt việc triển khai đối tượng khỏi việc sử dụng nó
+
+## Vấn đề
+
+Khi nào bạn nên sử dụng mẫu Factory?
+
+- Khi một lớp không thể dự đoán trước loại đối tượng mà nó cần tạo
+- Khi một lớp muốn các lớp con của nó chỉ định đối tượng mà nó tạo ra
+- Khi bạn muốn tập trung kiến thức về việc lớp nào được tạo
+
+## Các loại mẫu Factory
+
+Có một số biến thể của mẫu Factory:
+
+1. **Simple Factory** - Không phải là một mẫu chính thức, nhưng là một cách đơn giản để tách biệt việc tạo đối tượng
+2. **Factory Method** - Định nghĩa một giao diện để tạo đối tượng, nhưng để các lớp con quyết định lớp nào sẽ được khởi tạo
+3. **Abstract Factory** - Cung cấp một giao diện để tạo ra các họ đối tượng liên quan hoặc phụ thuộc
+
+## Cấu trúc
+
+### Mẫu Factory Method
+
+
+
+### Mẫu Abstract Factory
+
+
+
+## Triển khai
+
+### Ví dụ về Simple Factory
+
+```java
+// Giao diện Product
+interface Product {
+ void operation();
+}
+
+// Các sản phẩm cụ thể
+class ConcreteProductA implements Product {
+ @Override
+ public void operation() {
+ System.out.println("Thao tác của ConcreteProductA");
+ }
+}
+
+class ConcreteProductB implements Product {
+ @Override
+ public void operation() {
+ System.out.println("Thao tác của ConcreteProductB");
+ }
+}
+
+// Simple factory
+class SimpleFactory {
+ public Product createProduct(String type) {
+ if (type.equals("A")) {
+ return new ConcreteProductA();
+ } else if (type.equals("B")) {
+ return new ConcreteProductB();
+ }
+ throw new IllegalArgumentException("Loại sản phẩm không hợp lệ: " + type);
+ }
+}
+
+// Client code
+class Client {
+ public static void main(String[] args) {
+ SimpleFactory factory = new SimpleFactory();
+
+ Product productA = factory.createProduct("A");
+ productA.operation();
+
+ Product productB = factory.createProduct("B");
+ productB.operation();
+ }
+}
+```
+
+### Ví dụ về Factory Method
+
+```java
+// Giao diện Product
+interface Product {
+ void operation();
+}
+
+// Các sản phẩm cụ thể
+class ConcreteProductA implements Product {
+ @Override
+ public void operation() {
+ System.out.println("Thao tác của ConcreteProductA");
+ }
+}
+
+class ConcreteProductB implements Product {
+ @Override
+ public void operation() {
+ System.out.println("Thao tác của ConcreteProductB");
+ }
+}
+
+// Lớp trừu tượng Creator với factory method
+abstract class Creator {
+ public abstract Product createProduct();
+
+ // Creator cũng có thể bao gồm một số logic nghiệp vụ
+ public void someOperation() {
+ // Gọi factory method để tạo một đối tượng Product
+ Product product = createProduct();
+ // Sử dụng sản phẩm
+ product.operation();
+ }
+}
+
+// Các creator cụ thể ghi đè factory method
+class ConcreteCreatorA extends Creator {
+ @Override
+ public Product createProduct() {
+ return new ConcreteProductA();
+ }
+}
+
+class ConcreteCreatorB extends Creator {
+ @Override
+ public Product createProduct() {
+ return new ConcreteProductB();
+ }
+}
+
+// Client code
+class Client {
+ public static void main(String[] args) {
+ Creator creatorA = new ConcreteCreatorA();
+ creatorA.someOperation();
+
+ Creator creatorB = new ConcreteCreatorB();
+ creatorB.someOperation();
+ }
+}
+```
+
+### Ví dụ về Abstract Factory
+
+```java
+// Các sản phẩm trừu tượng
+interface ProductA {
+ void operationA();
+}
+
+interface ProductB {
+ void operationB();
+}
+
+// Các sản phẩm cụ thể cho họ 1
+class ConcreteProductA1 implements ProductA {
+ @Override
+ public void operationA() {
+ System.out.println("Thao tác của sản phẩm A1");
+ }
+}
+
+class ConcreteProductB1 implements ProductB {
+ @Override
+ public void operationB() {
+ System.out.println("Thao tác của sản phẩm B1");
+ }
+}
+
+// Các sản phẩm cụ thể cho họ 2
+class ConcreteProductA2 implements ProductA {
+ @Override
+ public void operationA() {
+ System.out.println("Thao tác của sản phẩm A2");
+ }
+}
+
+class ConcreteProductB2 implements ProductB {
+ @Override
+ public void operationB() {
+ System.out.println("Thao tác của sản phẩm B2");
+ }
+}
+
+// Giao diện Abstract factory
+interface AbstractFactory {
+ ProductA createProductA();
+ ProductB createProductB();
+}
+
+// Các factory cụ thể
+class ConcreteFactory1 implements AbstractFactory {
+ @Override
+ public ProductA createProductA() {
+ return new ConcreteProductA1();
+ }
+
+ @Override
+ public ProductB createProductB() {
+ return new ConcreteProductB1();
+ }
+}
+
+class ConcreteFactory2 implements AbstractFactory {
+ @Override
+ public ProductA createProductA() {
+ return new ConcreteProductA2();
+ }
+
+ @Override
+ public ProductB createProductB() {
+ return new ConcreteProductB2();
+ }
+}
+
+// Client code
+class Client {
+ private ProductA productA;
+ private ProductB productB;
+
+ public Client(AbstractFactory factory) {
+ productA = factory.createProductA();
+ productB = factory.createProductB();
+ }
+
+ public void executeOperations() {
+ productA.operationA();
+ productB.operationB();
+ }
+}
+```
+
+## Ví dụ trong các ngôn ngữ khác nhau
+
+### JavaScript
+
+```javascript
+// Factory Method trong JavaScript
+
+// Giao diện Product ngầm định trong JavaScript
+class Dog {
+ speak() {
+ return "Gâu gâu!";
+ }
+}
+
+class Cat {
+ speak() {
+ return "Meo meo!";
+ }
+}
+
+// Creator
+class AnimalFactory {
+ // Factory method
+ createAnimal(type) {
+ switch(type) {
+ case 'dog':
+ return new Dog();
+ case 'cat':
+ return new Cat();
+ default:
+ throw new Error(`Loại động vật ${type} không được hỗ trợ.`);
+ }
+ }
+}
+
+// Sử dụng
+const factory = new AnimalFactory();
+const dog = factory.createAnimal('dog');
+const cat = factory.createAnimal('cat');
+
+console.log(dog.speak()); // Đầu ra: Gâu gâu!
+console.log(cat.speak()); // Đầu ra: Meo meo!
+```
+
+### Python
+
+```python
+from abc import ABC, abstractmethod
+
+# Abstract Product
+class Button(ABC):
+ @abstractmethod
+ def render(self):
+ pass
+
+ @abstractmethod
+ def on_click(self):
+ pass
+
+# Concrete Products
+class HTMLButton(Button):
+ def render(self):
+ return ""
+
+ def on_click(self):
+ return "Nút HTML đã được nhấp!"
+
+class WindowsButton(Button):
+ def render(self):
+ return "Nút Windows"
+
+ def on_click(self):
+ return "Nút Windows đã được nhấp!"
+
+# Abstract Creator
+class Dialog(ABC):
+ @abstractmethod
+ def create_button(self) -> Button:
+ pass
+
+ def render(self):
+ # Gọi factory method để tạo đối tượng button
+ button = self.create_button()
+ # Bây giờ sử dụng sản phẩm
+ return f"Dialog hiển thị với {button.render()}"
+
+# Concrete Creators
+class HTMLDialog(Dialog):
+ def create_button(self) -> Button:
+ return HTMLButton()
+
+class WindowsDialog(Dialog):
+ def create_button(self) -> Button:
+ return WindowsButton()
+
+# Client code
+def client_code(dialog: Dialog):
+ print(dialog.render())
+
+# Dựa vào môi trường, chúng ta chọn dialog phù hợp
+import sys
+if sys.platform.startswith('win'):
+ dialog = WindowsDialog()
+else:
+ dialog = HTMLDialog()
+
+client_code(dialog)
+```
+
+### C#
+
+```csharp
+using System;
+
+// Abstract Product
+public interface IVehicle
+{
+ void Drive();
+}
+
+// Concrete Products
+public class Car : IVehicle
+{
+ public void Drive()
+ {
+ Console.WriteLine("Đang lái xe ô tô...");
+ }
+}
+
+public class Motorcycle : IVehicle
+{
+ public void Drive()
+ {
+ Console.WriteLine("Đang lái xe máy...");
+ }
+}
+
+// Abstract Creator
+public abstract class VehicleFactory
+{
+ // Factory Method
+ public abstract IVehicle CreateVehicle();
+
+ public void DeliverVehicle()
+ {
+ IVehicle vehicle = CreateVehicle();
+ Console.WriteLine("Đang giao phương tiện...");
+ vehicle.Drive();
+ }
+}
+
+// Concrete Creators
+public class CarFactory : VehicleFactory
+{
+ public override IVehicle CreateVehicle()
+ {
+ return new Car();
+ }
+}
+
+public class MotorcycleFactory : VehicleFactory
+{
+ public override IVehicle CreateVehicle()
+ {
+ return new Motorcycle();
+ }
+}
+
+// Client code
+public class Program
+{
+ public static void Main()
+ {
+ VehicleFactory factory = GetFactory("car");
+ factory.DeliverVehicle();
+
+ factory = GetFactory("motorcycle");
+ factory.DeliverVehicle();
+ }
+
+ private static VehicleFactory GetFactory(string vehicleType)
+ {
+ switch (vehicleType.ToLower())
+ {
+ case "car":
+ return new CarFactory();
+ case "motorcycle":
+ return new MotorcycleFactory();
+ default:
+ throw new ArgumentException($"Loại phương tiện {vehicleType} không được hỗ trợ.");
+ }
+ }
+}
+```
+
+## Trường hợp sử dụng
+
+- **Tạo thành phần UI**: Tạo các thành phần UI khác nhau dựa trên tùy chọn của người dùng hoặc nền tảng
+- **Kết nối cơ sở dữ liệu**: Tạo kết nối cơ sở dữ liệu phù hợp dựa trên cấu hình
+- **Tạo tài liệu**: Tạo các loại tài liệu khác nhau (PDF, Word, v.v.)
+- **Sản xuất phương tiện**: Tạo các loại phương tiện khác nhau trong một mô phỏng
+- **Xử lý thanh toán**: Tạo các phương thức thanh toán khác nhau trong ứng dụng thương mại điện tử
+
+## Ưu và nhược điểm
+
+### Ưu điểm
+
+- Tránh sự kết hợp chặt chẽ giữa creator và các sản phẩm cụ thể
+- Nguyên tắc trách nhiệm đơn lẻ: Di chuyển mã tạo sản phẩm đến một nơi
+- Nguyên tắc mở/đóng: Các sản phẩm mới có thể được thêm vào mà không phá vỡ mã hiện có
+- Tạo đối tượng theo yêu cầu, thay vì tại thời điểm khởi tạo
+
+### Nhược điểm
+
+- Mã có thể trở nên phức tạp hơn do việc giới thiệu nhiều lớp con mới
+- Client có thể bị giới hạn về các sản phẩm được hiển thị bởi giao diện factory
+
+## Mối quan hệ với các mẫu khác
+
+- Các lớp **Abstract Factory** thường được triển khai với Factory Methods
+- **Factory Methods** thường được sử dụng trong Template Methods
+- **Prototype** có thể là một giải pháp thay thế cho Factory khi mục tiêu là giảm việc tạo lớp con
+- **Builder** tập trung vào việc xây dựng các đối tượng phức tạp từng bước một, trong khi Factory Method là một lệnh gọi duy nhất
+
+## Ví dụ thực tế
+
+- `Calendar.getInstance()` trong Java
+- Các factory widget trong các framework UI
+- Các factory kết nối cơ sở dữ liệu
+- Các trình tạo tài liệu trong bộ ứng dụng văn phòng
+
+## Tài liệu tham khảo
+
+- "Design Patterns: Elements of Reusable Object-Oriented Software" của Gang of Four (GoF)
+- [Refactoring Guru - Mẫu Factory Method](https://refactoring.guru/design-patterns/factory-method)
+- [Refactoring Guru - Mẫu Abstract Factory](https://refactoring.guru/design-patterns/abstract-factory)
\ No newline at end of file
diff --git a/i18n/vi/design-patterns/observer_vi.md b/i18n/vi/design-patterns/observer_vi.md
new file mode 100644
index 0000000..69155cc
--- /dev/null
+++ b/i18n/vi/design-patterns/observer_vi.md
@@ -0,0 +1,404 @@
+# Mẫu thiết kế Observer
+
+Mẫu Observer là một mẫu thiết kế hành vi trong đó một đối tượng, gọi là chủ thể (subject), duy trì danh sách các phụ thuộc của nó, gọi là Observer, và thông báo cho họ tự động về bất kỳ thay đổi trạng thái nào, thường bằng cách gọi một trong các phương thức của họ.
+
+## Mục đích
+
+- Định nghĩa một mối quan hệ một-nhiều giữa các đối tượng để khi một đối tượng thay đổi trạng thái, tất cả các đối tượng phụ thuộc của nó được thông báo và cập nhật tự động.
+- Đóng gói các thành phần cốt lõi trong một lớp Subject trừu tượng, và các thành phần biến đổi trong một phân cấp Observer.
+- Các lớp Subject và Observer có thể thay đổi độc lập với nhau.
+
+## Vấn đề
+
+Trong nhiều ứng dụng, một số loại đối tượng cụ thể cần được thông báo về những thay đổi trong các đối tượng khác. Tuy nhiên, chúng ta không muốn kết nối quá chặt chẽ các loại đối tượng khác nhau này để duy trì tính linh hoạt và khả năng tái sử dụng.
+
+Bạn cần một cách để một đối tượng thông báo cho một số lượng không xác định trước các đối tượng khác về những thay đổi, mà không cần các đối tượng đó kết nối chặt chẽ với nhau.
+
+## Cấu trúc
+
+
+
+- **Subject (Chủ thể)**: Giao diện hoặc lớp trừu tượng định nghĩa các hoạt động để gắn, tách, và thông báo cho Observer.
+- **ConcreteSubject (Chủ thể cụ thể)**: Duy trì trạng thái mà Observer quan tâm và gửi thông báo khi trạng thái thay đổi.
+- **Observer (Observer)**: Giao diện hoặc lớp trừu tượng với phương thức cập nhật được gọi khi trạng thái của chủ thể thay đổi.
+- **ConcreteObserver (Observer cụ thể)**: Triển khai giao diện Observer để giữ trạng thái của nó nhất quán với trạng thái của chủ thể.
+
+## Triển khai
+
+### Triển khai cơ bản
+
+```java
+// Giao diện Observer
+interface Observer {
+ void update(Subject subject);
+}
+
+// Giao diện Subject
+interface Subject {
+ void attach(Observer observer);
+ void detach(Observer observer);
+ void notifyObservers();
+}
+
+// ConcreteSubject
+class ConcreteSubject implements Subject {
+ private List observers = new ArrayList<>();
+ private int state;
+
+ public int getState() {
+ return state;
+ }
+
+ public void setState(int state) {
+ this.state = state;
+ notifyObservers();
+ }
+
+ @Override
+ public void attach(Observer observer) {
+ observers.add(observer);
+ }
+
+ @Override
+ public void detach(Observer observer) {
+ observers.remove(observer);
+ }
+
+ @Override
+ public void notifyObservers() {
+ for (Observer observer : observers) {
+ observer.update(this);
+ }
+ }
+}
+
+// ConcreteObserver
+class ConcreteObserver implements Observer {
+ private int observerState;
+
+ @Override
+ public void update(Subject subject) {
+ if (subject instanceof ConcreteSubject) {
+ observerState = ((ConcreteSubject) subject).getState();
+ System.out.println("Trạng thái Observer được cập nhật thành: " + observerState);
+ }
+ }
+}
+```
+
+### Mô hình Push và Pull
+
+#### Mô hình Push
+
+Trong mô hình push, Chủ thể gửi thông tin chi tiết về thay đổi đến tất cả Observer, bất kể họ có cần hay không:
+
+```java
+// Trong ConcreteSubject
+public void notifyObservers(int state) {
+ for (Observer observer : observers) {
+ observer.update(state);
+ }
+}
+
+// Trong giao diện Observer
+void update(int state);
+```
+
+#### Mô hình Pull
+
+Trong mô hình pull, Chủ thể chỉ đơn giản thông báo cho Observer rằng có thay đổi xảy ra, và Observer chịu trách nhiệm lấy dữ liệu cần thiết:
+
+```java
+// Trong ConcreteSubject
+public void notifyObservers() {
+ for (Observer observer : observers) {
+ observer.update(this);
+ }
+}
+
+// Trong giao diện Observer
+void update(Subject subject);
+```
+
+## Ví dụ trong các ngôn ngữ khác nhau
+
+### JavaScript
+
+```javascript
+// Sử dụng lớp ES6
+class Subject {
+ constructor() {
+ this.observers = [];
+ }
+
+ attach(observer) {
+ if (!this.observers.includes(observer)) {
+ this.observers.push(observer);
+ }
+ }
+
+ detach(observer) {
+ const index = this.observers.indexOf(observer);
+ if (index !== -1) {
+ this.observers.splice(index, 1);
+ }
+ }
+
+ notify() {
+ for (const observer of this.observers) {
+ observer.update(this);
+ }
+ }
+}
+
+class WeatherStation extends Subject {
+ constructor() {
+ super();
+ this.temperature = 0;
+ this.humidity = 0;
+ }
+
+ setMeasurements(temperature, humidity) {
+ this.temperature = temperature;
+ this.humidity = humidity;
+ this.notify();
+ }
+
+ getTemperature() {
+ return this.temperature;
+ }
+
+ getHumidity() {
+ return this.humidity;
+ }
+}
+
+class Observer {
+ update(subject) {}
+}
+
+class DisplayDevice extends Observer {
+ constructor(name) {
+ super();
+ this.name = name;
+ }
+
+ update(weatherStation) {
+ console.log(`Màn hình ${this.name}: Nhiệt độ ${weatherStation.getTemperature()}°C, Độ ẩm ${weatherStation.getHumidity()}%`);
+ }
+}
+
+// Cách sử dụng
+const weatherStation = new WeatherStation();
+const phoneDisplay = new DisplayDevice('Điện thoại');
+const laptopDisplay = new DisplayDevice('Laptop');
+
+weatherStation.attach(phoneDisplay);
+weatherStation.attach(laptopDisplay);
+
+weatherStation.setMeasurements(25, 60); // Cả hai màn hình cập nhật
+weatherStation.detach(laptopDisplay);
+weatherStation.setMeasurements(26, 70); // Chỉ màn hình điện thoại cập nhật
+```
+
+### Python
+
+```python
+from abc import ABC, abstractmethod
+
+# Giao diện Observer
+class Observer(ABC):
+ @abstractmethod
+ def update(self, subject):
+ pass
+
+# Giao diện Subject
+class Subject(ABC):
+ @abstractmethod
+ def attach(self, observer):
+ pass
+
+ @abstractmethod
+ def detach(self, observer):
+ pass
+
+ @abstractmethod
+ def notify(self):
+ pass
+
+# ConcreteSubject
+class NewsPublisher(Subject):
+ def __init__(self):
+ self._observers = []
+ self._latest_news = None
+
+ def attach(self, observer):
+ self._observers.append(observer)
+
+ def detach(self, observer):
+ self._observers.remove(observer)
+
+ def notify(self):
+ for observer in self._observers:
+ observer.update(self)
+
+ def add_news(self, news):
+ self._latest_news = news
+ self.notify()
+
+ @property
+ def latest_news(self):
+ return self._latest_news
+
+# ConcreteObserver
+class NewsSubscriber(Observer):
+ def __init__(self, name):
+ self._name = name
+
+ def update(self, subject):
+ print(f"{self._name} nhận được tin tức: {subject.latest_news}")
+
+# Cách sử dụng
+if __name__ == "__main__":
+ publisher = NewsPublisher()
+
+ subscriber1 = NewsSubscriber("Người đăng ký 1")
+ subscriber2 = NewsSubscriber("Người đăng ký 2")
+
+ publisher.attach(subscriber1)
+ publisher.attach(subscriber2)
+
+ publisher.add_news("Tin nóng: Mẫu Observer đang hoạt động!")
+
+ publisher.detach(subscriber1)
+
+ publisher.add_news("Cập nhật mới: Người đăng ký 1 đã hủy đăng ký!")
+```
+
+### C#
+
+```csharp
+using System;
+using System.Collections.Generic;
+
+// Giao diện Observer
+public interface IObserver
+{
+ void Update(ISubject subject);
+}
+
+// Giao diện Subject
+public interface ISubject
+{
+ void Attach(IObserver observer);
+ void Detach(IObserver observer);
+ void Notify();
+}
+
+// ConcreteSubject
+public class StockMarket : ISubject
+{
+ private List _observers = new List();
+ private Dictionary _stocks = new Dictionary();
+
+ public void Attach(IObserver observer)
+ {
+ Console.WriteLine("Thị trường chứng khoán: Đã gắn một Observer.");
+ _observers.Add(observer);
+ }
+
+ public void Detach(IObserver observer)
+ {
+ _observers.Remove(observer);
+ Console.WriteLine("Thị trường chứng khoán: Đã tách một Observer.");
+ }
+
+ public void Notify()
+ {
+ Console.WriteLine("Thị trường chứng khoán: Đang thông báo cho Observer...");
+
+ foreach (var observer in _observers)
+ {
+ observer.Update(this);
+ }
+ }
+
+ public void UpdateStockPrice(string stockSymbol, double price)
+ {
+ Console.WriteLine($"Thị trường chứng khoán: Giá {stockSymbol} cập nhật thành {price}");
+ _stocks[stockSymbol] = price;
+ Notify();
+ }
+
+ public Dictionary GetStocks()
+ {
+ return _stocks;
+ }
+}
+
+// ConcreteObserver
+public class Investor : IObserver
+{
+ private string _name;
+ private Dictionary _watchlist = new Dictionary();
+
+ public Investor(string name)
+ {
+ _name = name;
+ }
+
+ public void Update(ISubject subject)
+ {
+ if (subject is StockMarket stockMarket)
+ {
+ var stocks = stockMarket.GetStocks();
+ foreach (var stock in stocks)
+ {
+ if (_watchlist.ContainsKey(stock.Key) && _watchlist[stock.Key] != stock.Value)
+ {
+ Console.WriteLine($"{_name}: Nhận thấy giá {stock.Key} thay đổi từ {_watchlist[stock.Key]} thành {stock.Value}");
+ }
+ _watchlist[stock.Key] = stock.Value;
+ }
+ }
+ }
+}
+```
+
+## Trường hợp sử dụng thực tế
+
+1. **Hệ thống xử lý sự kiện**: Các framework UI sử dụng mẫu Observer để xử lý hành động của người dùng.
+2. **Dịch vụ đăng ký tin tức**: Người dùng đăng ký các chủ đề và nhận cập nhật.
+3. **Theo dõi thị trường chứng khoán**: Nhà đầu tư theo dõi thay đổi giá cổ phiếu.
+4. **Thông báo mạng xã hội**: Người dùng nhận thông báo về các hoạt động liên quan đến tài khoản của họ.
+5. **Hệ thống hàng đợi tin nhắn**: Nhà xuất bản gửi tin nhắn đến người tiêu dùng đã đăng ký.
+6. **Hệ thống giám sát**: Ứng dụng giám sát tài nguyên hệ thống hoặc dịch vụ.
+
+## Ưu và nhược điểm
+
+### Ưu điểm
+
+- **Nguyên tắc Mở/Đóng**: Bạn có thể giới thiệu các lớp người đăng ký mới mà không cần thay đổi mã của nhà xuất bản.
+- **Liên kết lỏng lẻo**: Nhà xuất bản không cần biết bất cứ điều gì về người đăng ký.
+- **Mối quan hệ động**: Mối quan hệ giữa nhà xuất bản và người đăng ký có thể được thiết lập trong thời gian chạy.
+- **Xử lý sự kiện**: Hiệu quả cho việc triển khai hệ thống xử lý sự kiện.
+
+### Nhược điểm
+
+- **Cập nhật không mong đợi**: Người đăng ký có thể được thông báo theo thứ tự không thể dự đoán.
+- **Rò rỉ bộ nhớ**: Nếu Observer quên hủy đăng ký, họ có thể không được thu gom rác.
+- **Chi phí hiệu suất**: Thông báo có thể tốn kém nếu có nhiều Observer hoặc thay đổi trạng thái thường xuyên.
+- **Độ phức tạp**: Gỡ lỗi có thể gặp thách thức vì luồng điều khiển ít rõ ràng hơn.
+
+## Mối quan hệ với các mẫu khác
+
+- **Mediator (Người trung gian)**: Trong khi Observer phân phối giao tiếp bằng cách giới thiệu đối tượng người đăng ký và nhà xuất bản, Mediator đóng gói giao tiếp giữa các đối tượng.
+- **Command (Lệnh)**: Commands có thể được sử dụng để triển khai mẫu Observer bằng cách chuyển yêu cầu thành đối tượng.
+- **Memento (Bản ghi nhớ)**: Có thể được sử dụng với Observer để hoàn tác các hoạt động sau khi thông báo cho Observer về các thay đổi.
+- **Mẫu MVC**: Mẫu Observer thường được sử dụng trong kiến trúc MVC nơi View quan sát các thay đổi trong Model.
+
+## Tài liệu tham khảo
+
+- "Design Patterns: Elements of Reusable Object-Oriented Software" của Gang of Four (GoF)
+- [Refactoring Guru - Observer Pattern](https://refactoring.guru/design-patterns/observer)
+- [SourceMaking - Observer Pattern](https://sourcemaking.com/design_patterns/observer)
\ No newline at end of file
diff --git a/i18n/vi/design-patterns/singleton_vi.md b/i18n/vi/design-patterns/singleton_vi.md
new file mode 100644
index 0000000..27dd4c8
--- /dev/null
+++ b/i18n/vi/design-patterns/singleton_vi.md
@@ -0,0 +1,226 @@
+# Mẫu thiết kế Singleton
+
+Singleton là một mẫu thiết kế tạo đối tượng đảm bảo rằng một lớp chỉ có một thể hiện duy nhất và cung cấp một điểm truy cập toàn cục đến thể hiện đó.
+
+## Mục đích
+
+- Đảm bảo một lớp chỉ có một thể hiện duy nhất.
+- Cung cấp một điểm truy cập toàn cục đến thể hiện đó.
+- Kiểm soát truy cập đồng thời đến tài nguyên được chia sẻ.
+
+## Vấn đề
+
+Khi nào bạn nên sử dụng mẫu Singleton?
+
+- Khi bạn cần chính xác một thể hiện của lớp để điều phối các hành động trong hệ thống
+- Khi bạn muốn hạn chế việc khởi tạo của một lớp thành chỉ một đối tượng
+- Khi bạn cần kiểm soát chặt chẽ hơn đối với biến toàn cục
+
+## Cấu trúc
+
+```
++----------------+
+| Singleton |
++----------------+
+| -instance |
++----------------+
+| +getInstance() |
+| -constructor() |
++----------------+
+```
+
+
+
+## Triển khai
+
+### Triển khai cơ bản
+
+```java
+public class Singleton {
+ // Thể hiện tĩnh riêng tư của lớp
+ private static Singleton instance;
+
+ // Constructor riêng tư ngăn việc khởi tạo từ các lớp khác
+ private Singleton() { }
+
+ // Phương thức tĩnh công khai để lấy thể hiện
+ public static Singleton getInstance() {
+ if (instance == null) {
+ instance = new Singleton();
+ }
+ return instance;
+ }
+
+ // Các phương thức và trường khác
+ public void doSomething() {
+ System.out.println("Singleton đang thực hiện một việc gì đó");
+ }
+}
+```
+
+### Triển khai an toàn với đa luồng
+
+```java
+public class ThreadSafeSingleton {
+ private static volatile ThreadSafeSingleton instance;
+
+ private ThreadSafeSingleton() { }
+
+ public static ThreadSafeSingleton getInstance() {
+ // Kiểm tra khóa hai lần (Double-checked locking)
+ if (instance == null) {
+ synchronized (ThreadSafeSingleton.class) {
+ if (instance == null) {
+ instance = new ThreadSafeSingleton();
+ }
+ }
+ }
+ return instance;
+ }
+}
+```
+
+### Khởi tạo sớm
+
+```java
+public class EagerSingleton {
+ // Thể hiện được tạo tại thời điểm tải
+ private static final EagerSingleton INSTANCE = new EagerSingleton();
+
+ private EagerSingleton() { }
+
+ public static EagerSingleton getInstance() {
+ return INSTANCE;
+ }
+}
+```
+
+### Sử dụng Enum (Java)
+
+```java
+public enum EnumSingleton {
+ INSTANCE;
+
+ public void doSomething() {
+ System.out.println("Singleton enum đang thực hiện một việc gì đó");
+ }
+}
+```
+
+## Ví dụ trong các ngôn ngữ khác nhau
+
+### JavaScript
+
+```javascript
+class Singleton {
+ constructor() {
+ if (Singleton.instance) {
+ return Singleton.instance;
+ }
+
+ // Khởi tạo singleton
+ this.data = [];
+ Singleton.instance = this;
+ }
+
+ add(item) {
+ this.data.push(item);
+ }
+
+ get(index) {
+ return this.data[index];
+ }
+}
+
+// Sử dụng
+const instance1 = new Singleton();
+const instance2 = new Singleton();
+console.log(instance1 === instance2); // true
+```
+
+### Python
+
+```python
+class Singleton:
+ _instance = None
+
+ def __new__(cls):
+ if cls._instance is None:
+ cls._instance = super(Singleton, cls).__new__(cls)
+ # Khởi tạo singleton của bạn tại đây
+ cls._instance.value = 0
+ return cls._instance
+
+# Sử dụng
+s1 = Singleton()
+s2 = Singleton()
+print(s1 is s2) # True
+```
+
+### C#
+
+```csharp
+public sealed class Singleton
+{
+ private static Singleton instance = null;
+ private static readonly object padlock = new object();
+
+ Singleton() {}
+
+ public static Singleton Instance
+ {
+ get
+ {
+ lock(padlock)
+ {
+ if (instance == null)
+ {
+ instance = new Singleton();
+ }
+ return instance;
+ }
+ }
+ }
+}
+```
+
+## Trường hợp sử dụng
+
+- **Kết nối cơ sở dữ liệu**: Quản lý một pool kết nối
+- **Logger**: Tạo một thể hiện ghi log duy nhất cho ứng dụng
+- **Cài đặt cấu hình**: Lưu trữ cài đặt ứng dụng
+- **Cache**: Tạo một trình quản lý cache duy nhất
+- **Thread pools**: Quản lý việc tạo và gán thread
+
+## Ưu và nhược điểm
+
+### Ưu điểm
+
+- Đảm bảo một lớp chỉ có một thể hiện duy nhất
+- Cung cấp một điểm truy cập toàn cục đến thể hiện đó
+- Đối tượng singleton chỉ được khởi tạo khi nó được yêu cầu lần đầu tiên
+
+### Nhược điểm
+
+- Vi phạm Nguyên lý trách nhiệm đơn lẻ (lớp quản lý việc tạo ra chính nó)
+- Có thể che giấu thiết kế không tốt, ví dụ, khi các thành phần biết quá nhiều về nhau
+- Yêu cầu xử lý đặc biệt trong môi trường đa luồng
+- Làm cho việc kiểm thử đơn vị khó khăn hơn
+
+## Mối quan hệ với các mẫu khác
+
+- Một **Facade** có thể trông giống như một Singleton nếu nó chỉ ẩn một đối tượng, nhưng chúng có mục đích khác nhau
+- **Abstract Factories**, **Builders**, và **Prototypes** đều có thể được triển khai như Singletons
+
+## Ví dụ thực tế
+
+- Lớp `java.lang.Runtime` trong Java
+- Các trình quản lý UI trong nhiều framework GUI
+- Windows Registry
+- Đối tượng window trong trình duyệt
+
+## Tài liệu tham khảo
+
+- "Design Patterns: Elements of Reusable Object-Oriented Software" của Gang of Four (GoF)
+- [Refactoring Guru - Singleton Pattern](https://refactoring.guru/design-patterns/singleton)
+- [SourceMaking - Singleton Pattern](https://sourcemaking.com/design_patterns/singleton)
\ No newline at end of file
diff --git a/i18n/vi/devops/ci-cd_vi.md b/i18n/vi/devops/ci-cd_vi.md
new file mode 100644
index 0000000..8b9dd04
--- /dev/null
+++ b/i18n/vi/devops/ci-cd_vi.md
@@ -0,0 +1,162 @@
+# Tích Hợp Liên Tục và Triển Khai Liên Tục (CI/CD)
+
+Tích hợp liên tục và triển khai liên tục (CI/CD) là một phương pháp để thường xuyên cung cấp ứng dụng cho khách hàng bằng cách đưa tự động hóa vào các giai đoạn phát triển ứng dụng.
+
+## CI/CD là gì?
+
+### Tích Hợp Liên Tục (CI)
+Tích hợp liên tục là một phương pháp phát triển trong đó các nhà phát triển tích hợp mã vào kho lưu trữ chung thường xuyên, tốt nhất là nhiều lần mỗi ngày. Mỗi lần tích hợp sau đó được xác minh bằng một bản dựng tự động và các bài kiểm tra tự động.
+
+### Phân Phối Liên Tục (CD)
+Phân phối liên tục là một phần mở rộng của tích hợp liên tục để đảm bảo rằng bạn có thể phát hành các thay đổi mới cho khách hàng một cách nhanh chóng và bền vững. Điều này có nghĩa là ngoài việc tự động hóa kiểm tra, bạn cũng đã tự động hóa quy trình phát hành và bạn có thể triển khai ứng dụng của mình bất kỳ lúc nào bằng cách nhấn nút.
+
+### Triển Khai Liên Tục
+Triển khai liên tục tiến xa hơn một bước so với phân phối liên tục. Với phương pháp này, mọi thay đổi vượt qua tất cả các giai đoạn của đường ống sản xuất của bạn đều được phát hành cho khách hàng của bạn. Không có sự can thiệp của con người, và chỉ có một bài kiểm tra thất bại mới ngăn chặn một thay đổi mới được triển khai lên môi trường sản xuất.
+
+## Các Thành Phần của Đường Ống CI/CD
+
+Một đường ống CI/CD điển hình bao gồm các giai đoạn sau:
+
+1. **Nguồn**: Mã được commit vào hệ thống quản lý phiên bản (Git, SVN, v.v.)
+2. **Xây Dựng**: Mã được biên dịch, các phụ thuộc được giải quyết
+3. **Kiểm Tra**: Các bài kiểm tra tự động được chạy (kiểm tra đơn vị, kiểm tra tích hợp, v.v.)
+4. **Triển Khai**: Ứng dụng được triển khai lên môi trường dàn dựng/sản xuất
+5. **Giám Sát**: Hiệu suất ứng dụng và lỗi được giám sát
+
+## Các Công Cụ CI/CD Phổ Biến
+
+### Jenkins
+
+Jenkins là một máy chủ tự động hóa mã nguồn mở cho phép các nhà phát triển xây dựng, kiểm tra và triển khai phần mềm của họ.
+
+```yaml
+# Ví dụ Jenkinsfile
+pipeline {
+ agent any
+
+ stages {
+ stage('Xây Dựng') {
+ steps {
+ echo 'Đang xây dựng..'
+ sh 'npm install'
+ }
+ }
+ stage('Kiểm Tra') {
+ steps {
+ echo 'Đang kiểm tra..'
+ sh 'npm test'
+ }
+ }
+ stage('Triển Khai') {
+ steps {
+ echo 'Đang triển khai....'
+ sh 'npm run deploy'
+ }
+ }
+ }
+}
+```
+
+### GitHub Actions
+
+GitHub Actions là một nền tảng CI/CD cho phép bạn tự động hóa quy trình xây dựng, kiểm tra và triển khai trực tiếp từ GitHub.
+
+```yaml
+# Ví dụ quy trình làm việc GitHub Actions
+name: Node.js CI
+
+on:
+ push:
+ branches: [ main ]
+ pull_request:
+ branches: [ main ]
+
+jobs:
+ build:
+ runs-on: ubuntu-latest
+
+ steps:
+ - uses: actions/checkout@v2
+ - name: Sử dụng Node.js
+ uses: actions/setup-node@v1
+ with:
+ node-version: '14.x'
+ - name: Cài đặt phụ thuộc
+ run: npm ci
+ - name: Chạy kiểm tra
+ run: npm test
+ - name: Triển khai
+ if: github.ref == 'refs/heads/main'
+ run: npm run deploy
+```
+
+### GitLab CI/CD
+
+GitLab CI/CD là một phần của GitLab cho phép bạn áp dụng tất cả các phương pháp liên tục (Tích hợp, Phân phối và Triển khai liên tục) vào phần mềm của bạn.
+
+```yaml
+# Ví dụ .gitlab-ci.yml
+stages:
+ - build
+ - test
+ - deploy
+
+build:
+ stage: build
+ script:
+ - echo "Đang xây dựng ứng dụng"
+ - npm install
+
+test:
+ stage: test
+ script:
+ - echo "Đang chạy kiểm tra"
+ - npm test
+
+deploy:
+ stage: deploy
+ script:
+ - echo "Đang triển khai ứng dụng"
+ - npm run deploy
+ only:
+ - main
+```
+
+### CircleCI
+
+CircleCI là một công cụ CI/CD dựa trên đám mây tự động hóa quy trình phát triển phần mềm.
+
+```yaml
+# Ví dụ cấu hình CircleCI
+version: 2.1
+jobs:
+ build:
+ docker:
+ - image: cimg/node:14.17
+ steps:
+ - checkout
+ - run: npm install
+ - run: npm test
+ - run: npm run deploy
+```
+
+## Các Phương Pháp Tốt Nhất cho CI/CD
+
+1. **Tự Động Hóa Mọi Thứ**: Tự động hóa càng nhiều quy trình phân phối phần mềm càng tốt.
+2. **Thất Bại Nhanh Chóng**: Phát hiện và giải quyết vấn đề càng sớm càng tốt trong quy trình phát triển.
+3. **Giữ Bản Dựng Xanh**: Một bản dựng bị hỏng nên là ưu tiên cao nhất của nhóm để sửa chữa.
+4. **Xây Dựng Chỉ Một Lần**: Xây dựng các tạo phẩm một lần và thăng cấp cùng một tạo phẩm qua đường ống.
+5. **Triển Khai Theo Cùng Một Cách cho Mọi Môi Trường**: Sử dụng cùng một quy trình triển khai cho tất cả các môi trường.
+6. **Kiểm Tra Khói cho Các Triển Khai**: Chạy các bài kiểm tra cơ bản sau khi triển khai để xác minh hệ thống đang chạy đúng.
+7. **Giữ Đường Ống CI/CD Nhanh**: Hướng tới một đường ống hoàn thành trong vòng chưa đến 10 phút.
+8. **Duy Trì Độ Phủ Kiểm Tra Tốt**: Đảm bảo các bài kiểm tra của bạn bao phủ phần lớn mã nguồn của bạn.
+
+## Tài Liệu Tham Khảo
+
+- [Martin Fowler về Tích Hợp Liên Tục](https://martinfowler.com/articles/continuousIntegration.html)
+- [Sổ Tay DevOps](https://itrevolution.com/book/the-devops-handbook/)
+- [Phân Phối Liên Tục](https://continuousdelivery.com/)
+- [Tài Liệu Jenkins](https://www.jenkins.io/doc/)
+- [Tài Liệu GitHub Actions](https://docs.github.com/en/actions)
+- [Tài Liệu GitLab CI/CD](https://docs.gitlab.com/ee/ci/)
+- [Tài Liệu CircleCI](https://circleci.com/docs/)
diff --git a/i18n/vi/linux/bash-scripting_vi.md b/i18n/vi/linux/bash-scripting_vi.md
new file mode 100644
index 0000000..329f3ff
--- /dev/null
+++ b/i18n/vi/linux/bash-scripting_vi.md
@@ -0,0 +1,325 @@
+# Lập Trình Bash
+
+Bash (Bourne Again SHell) là một ngôn ngữ thông dịch lệnh được sử dụng rộng rãi trên nhiều hệ điều hành, và là shell mặc định trên hầu hết các bản phân phối Linux.
+
+## Giới Thiệu về Lập Trình Bash
+
+Các script Bash là các tệp văn bản chứa một chuỗi các lệnh được thực thi bởi shell Bash. Chúng cho phép bạn tự động hóa các tác vụ lặp đi lặp lại, kết hợp các lệnh phức tạp, và tạo các tiện ích tùy chỉnh.
+
+## Cú Pháp Cơ Bản
+
+### Tạo một Script Bash
+
+1. Tạo một tệp với phần mở rộng `.sh`
+2. Thêm dòng shebang ở đầu: `#!/bin/bash`
+3. Làm cho script có thể thực thi: `chmod +x script.sh`
+4. Chạy script: `./script.sh`
+
+### Ví Dụ Hello World
+
+```bash
+#!/bin/bash
+# Đây là một chú thích
+echo "Xin chào, Thế giới!"
+```
+
+## Biến
+
+### Khai Báo và Sử Dụng Biến
+
+```bash
+#!/bin/bash
+
+# Khai báo biến
+ten="Nguyen"
+tuoi=30
+
+# Sử dụng biến
+echo "Tên: $ten"
+echo "Tuổi: $tuoi"
+
+# Thay thế lệnh
+ngay_hien_tai=$(date)
+echo "Ngày hiện tại: $ngay_hien_tai"
+
+# Phép toán
+ket_qua=$((10 + 5))
+echo "10 + 5 = $ket_qua"
+```
+
+### Biến Đặc Biệt
+
+| Biến | Mô tả |
+|----------|-------------|
+| `$0` | Tên của script |
+| `$1` đến `$9` | 9 tham số đầu tiên được truyền vào script |
+| `$#` | Số lượng tham số được truyền vào script |
+| `$@` | Tất cả tham số được truyền vào script |
+| `$?` | Trạng thái thoát của lệnh cuối cùng |
+| `$$` | Process ID của script hiện tại |
+| `$USER` | Tên người dùng đang chạy script |
+| `$HOSTNAME` | Tên máy chủ |
+| `$RANDOM` | Một số ngẫu nhiên |
+| `$HOME` | Thư mục home của người dùng |
+
+## Cấu Trúc Điều Khiển
+
+### Câu Lệnh Điều Kiện
+
+#### Câu Lệnh If-Else
+
+```bash
+#!/bin/bash
+
+tuoi=25
+
+if [ $tuoi -lt 18 ]; then
+ echo "Bạn là trẻ vị thành niên."
+elif [ $tuoi -ge 18 ] && [ $tuoi -lt 65 ]; then
+ echo "Bạn là người trưởng thành."
+else
+ echo "Bạn là người cao tuổi."
+fi
+```
+
+#### Câu Lệnh Case
+
+```bash
+#!/bin/bash
+
+trai_cay="táo"
+
+case $trai_cay in
+ "táo")
+ echo "Đây là quả táo."
+ ;;
+ "chuối")
+ echo "Đây là quả chuối."
+ ;;
+ "cam")
+ echo "Đây là quả cam."
+ ;;
+ *)
+ echo "Không xác định được loại trái cây."
+ ;;
+esac
+```
+
+### Vòng Lặp
+
+#### Vòng Lặp For
+
+```bash
+#!/bin/bash
+
+# Vòng lặp for đơn giản
+for i in 1 2 3 4 5; do
+ echo "Số: $i"
+done
+
+# Vòng lặp for với khoảng
+for i in {1..5}; do
+ echo "Số: $i"
+done
+
+# Vòng lặp for với bước nhảy
+for i in {1..10..2}; do
+ echo "Số lẻ: $i"
+done
+
+# Vòng lặp for với đầu ra lệnh
+for file in $(ls); do
+ echo "Tệp: $file"
+done
+```
+
+#### Vòng Lặp While
+
+```bash
+#!/bin/bash
+
+count=1
+
+while [ $count -le 5 ]; do
+ echo "Đếm: $count"
+ ((count++))
+done
+```
+
+#### Vòng Lặp Until
+
+```bash
+#!/bin/bash
+
+count=1
+
+until [ $count -gt 5 ]; do
+ echo "Đếm: $count"
+ ((count++))
+done
+```
+
+## Hàm
+
+### Định Nghĩa và Sử Dụng Hàm
+
+```bash
+#!/bin/bash
+
+# Định nghĩa hàm
+chao_hoi() {
+ echo "Xin chào, $1!"
+}
+
+# Hàm với giá trị trả về
+cong() {
+ local ket_qua=$(($1 + $2))
+ echo $ket_qua
+}
+
+# Gọi hàm
+chao_hoi "Nguyễn"
+tong=$(cong 5 3)
+echo "5 + 3 = $tong"
+```
+
+## Đầu Vào và Đầu Ra
+
+### Đọc Đầu Vào Người Dùng
+
+```bash
+#!/bin/bash
+
+# Đọc một giá trị
+echo "Nhập tên của bạn:"
+read ten
+echo "Xin chào, $ten!"
+
+# Đọc nhiều giá trị
+echo "Nhập họ và tên của bạn:"
+read ho ten
+echo "Xin chào, $ho $ten!"
+
+# Đọc với lời nhắc
+read -p "Nhập tuổi của bạn: " tuoi
+echo "Bạn $tuoi tuổi."
+
+# Đọc mật khẩu (ẩn đầu vào)
+read -sp "Nhập mật khẩu của bạn: " mat_khau
+echo -e "\nĐã nhận mật khẩu."
+```
+
+### Đầu Vào/Đầu Ra Tệp
+
+```bash
+#!/bin/bash
+
+# Ghi vào tệp
+echo "Xin chào, Thế giới!" > output.txt
+echo "Đây là một dòng mới." >> output.txt
+
+# Đọc từ tệp
+while IFS= read -r line; do
+ echo "Dòng: $line"
+done < input.txt
+
+# Xử lý từng dòng của tệp
+cat input.txt | while read line; do
+ echo "Đang xử lý: $line"
+done
+```
+
+## Mảng
+
+### Thao Tác Mảng
+
+```bash
+#!/bin/bash
+
+# Khai báo mảng
+trai_cay=("táo" "chuối" "cam" "nho")
+
+# Truy cập phần tử mảng
+echo "Trái cây đầu tiên: ${trai_cay[0]}"
+echo "Tất cả trái cây: ${trai_cay[@]}"
+echo "Số lượng trái cây: ${#trai_cay[@]}"
+
+# Lặp qua mảng
+for trai_cay in "${trai_cay[@]}"; do
+ echo "Trái cây: $trai_cay"
+done
+
+# Thêm phần tử vào mảng
+trai_cay+=("kiwi")
+
+# Xóa phần tử khỏi mảng
+unset trai_cay[1]
+```
+
+## Thao Tác Chuỗi
+
+### Thao Tác Chuỗi
+
+```bash
+#!/bin/bash
+
+# Độ dài chuỗi
+str="Xin chào, Thế giới!"
+echo "Độ dài: ${#str}"
+
+# Chuỗi con
+echo "Chuỗi con: ${str:7:5}"
+
+# Thay thế chuỗi
+echo "Thay thế: ${str/Thế giới/Bash}"
+
+# Chuyển đổi sang chữ hoa/chữ thường
+echo "Chữ hoa: ${str^^}"
+echo "Chữ thường: ${str,,}"
+```
+
+## Xử Lý Lỗi
+
+### Xử Lý Lỗi Cơ Bản
+
+```bash
+#!/bin/bash
+
+# Thoát khi có lỗi
+set -e
+
+# Xử lý lỗi tùy chỉnh
+xu_ly_loi() {
+ echo "Lỗi xảy ra tại dòng $1"
+ exit 1
+}
+
+# Bắt lỗi
+trap 'xu_ly_loi $LINENO' ERR
+
+# Kiểm tra thành công của lệnh
+if ! command -v git &> /dev/null; then
+ echo "Git chưa được cài đặt."
+ exit 1
+fi
+```
+
+## Các Phương Pháp Tốt Nhất
+
+1. **Sử Dụng Shebang**: Luôn bao gồm `#!/bin/bash` ở đầu script của bạn.
+2. **Chú Thích**: Thêm chú thích để giải thích logic phức tạp.
+3. **Xử Lý Lỗi**: Triển khai xử lý lỗi thích hợp.
+4. **Thụt Lề**: Sử dụng thụt lề nhất quán để dễ đọc.
+5. **Quy Ước Đặt Tên**: Sử dụng tên mô tả cho biến và hàm.
+6. **Trích Dẫn Biến**: Luôn trích dẫn biến để xử lý khoảng trắng và ký tự đặc biệt.
+7. **Mã Thoát**: Trả về mã thoát thích hợp.
+8. **Tính Mô-đun**: Chia các script phức tạp thành các hàm.
+9. **Gỡ Lỗi**: Sử dụng `set -x` để gỡ lỗi.
+10. **Kiểm Tra**: Kiểm tra script của bạn với các đầu vào khác nhau.
+
+## Tài Liệu Tham Khảo
+
+- [Hướng Dẫn Sử Dụng GNU Bash](https://www.gnu.org/software/bash/manual/)
+- [Hướng Dẫn Bash cho Người Mới Bắt Đầu](https://tldp.org/LDP/Bash-Beginners-Guide/html/)
+- [Hướng Dẫn Lập Trình Bash Nâng Cao](https://tldp.org/LDP/abs/html/)
+- [ShellCheck](https://www.shellcheck.net/) - Một công cụ phân tích script shell
diff --git a/i18n/vi/system-design/microservices_vi.md b/i18n/vi/system-design/microservices_vi.md
new file mode 100644
index 0000000..80da511
--- /dev/null
+++ b/i18n/vi/system-design/microservices_vi.md
@@ -0,0 +1,467 @@
+# Kiến Trúc Microservices
+
+Kiến trúc microservices là một phong cách kiến trúc cấu trúc một ứng dụng như một tập hợp các dịch vụ nhỏ, liên kết lỏng lẻo có thể được phát triển, triển khai và mở rộng độc lập.
+
+## Microservices là gì?
+
+Microservices là các dịch vụ nhỏ, tự chủ hoạt động cùng nhau để tạo thành một ứng dụng hoàn chỉnh. Mỗi microservice:
+
+- Tập trung vào một khả năng kinh doanh duy nhất
+- Chạy trong quy trình riêng của nó
+- Giao tiếp thông qua API được định nghĩa rõ ràng
+- Có thể được triển khai độc lập
+- Có thể được viết bằng các ngôn ngữ lập trình khác nhau
+- Có thể sử dụng các công nghệ lưu trữ dữ liệu khác nhau
+
+## Kiến Trúc Nguyên Khối vs. Microservices
+
+| Khía cạnh | Nguyên khối | Microservices |
+|--------|------------|---------------|
+| Cấu trúc | Codebase thống nhất, đơn lẻ | Nhiều dịch vụ độc lập |
+| Phát triển | Đơn giản hơn để phát triển ban đầu | Thiết lập ban đầu phức tạp hơn |
+| Triển khai | Triển khai toàn bộ ứng dụng | Triển khai từng dịch vụ riêng biệt |
+| Mở rộng | Mở rộng toàn bộ ứng dụng | Mở rộng các dịch vụ riêng lẻ khi cần |
+| Công nghệ | Một ngăn xếp công nghệ duy nhất | Có thể sử dụng nhiều ngăn xếp công nghệ |
+| Cấu trúc nhóm | Các nhóm lớn hơn làm việc trên cùng một codebase | Các nhóm nhỏ hơn làm việc trên các dịch vụ riêng lẻ |
+| Tác động của lỗi | Điểm lỗi duy nhất | Lỗi cô lập |
+| Quản lý dữ liệu | Cơ sở dữ liệu được chia sẻ | Cơ sở dữ liệu cho mỗi dịch vụ |
+
+## Nguyên Tắc Chính của Microservices
+
+1. **Trách Nhiệm Đơn Lẻ**: Mỗi dịch vụ chịu trách nhiệm cho một khả năng kinh doanh cụ thể.
+2. **Tự Chủ**: Các dịch vụ có thể được phát triển, triển khai và mở rộng độc lập.
+3. **Khả Năng Phục Hồi**: Lỗi trong một dịch vụ không nên lan truyền sang các dịch vụ khác.
+4. **Phân Cấp**: Quản trị và quản lý dữ liệu phi tập trung.
+5. **Phân Phối Liên Tục**: Triển khai tự động, thường xuyên của các dịch vụ riêng lẻ.
+6. **Khả Năng Quan Sát**: Giám sát và ghi nhật ký toàn diện.
+7. **Thiết Kế Hướng Miền**: Các dịch vụ được thiết kế xung quanh các miền kinh doanh.
+
+## Mẫu Giao Tiếp Microservices
+
+### Giao Tiếp Đồng Bộ
+
+#### REST API
+
+```json
+// Ví dụ yêu cầu REST API
+GET /api/products/123
+Accept: application/json
+
+// Ví dụ phản hồi
+{
+ "id": "123",
+ "name": "Tên Sản Phẩm",
+ "price": 19.99,
+ "category": "Điện tử"
+}
+```
+
+#### gRPC
+
+```protobuf
+// Ví dụ định nghĩa dịch vụ gRPC
+syntax = "proto3";
+
+service ProductService {
+ rpc GetProduct(ProductRequest) returns (Product);
+}
+
+message ProductRequest {
+ string id = 1;
+}
+
+message Product {
+ string id = 1;
+ string name = 2;
+ double price = 3;
+ string category = 4;
+}
+```
+
+### Giao Tiếp Bất Đồng Bộ
+
+#### Hàng Đợi Thông Điệp
+
+```javascript
+// Ví dụ nhà sản xuất thông điệp (Node.js với RabbitMQ)
+const amqp = require('amqplib');
+
+async function sendOrderCreatedEvent(order) {
+ const connection = await amqp.connect('amqp://localhost');
+ const channel = await connection.createChannel();
+
+ const queue = 'order_events';
+ const message = JSON.stringify({
+ type: 'ORDER_CREATED',
+ data: order
+ });
+
+ await channel.assertQueue(queue, { durable: true });
+ channel.sendToQueue(queue, Buffer.from(message));
+
+ console.log(`Đã gửi: ${message}`);
+
+ setTimeout(() => {
+ connection.close();
+ }, 500);
+}
+```
+
+```javascript
+// Ví dụ người tiêu thụ thông điệp (Node.js với RabbitMQ)
+const amqp = require('amqplib');
+
+async function processOrderEvents() {
+ const connection = await amqp.connect('amqp://localhost');
+ const channel = await connection.createChannel();
+
+ const queue = 'order_events';
+
+ await channel.assertQueue(queue, { durable: true });
+ console.log(`Đang đợi thông điệp trong ${queue}`);
+
+ channel.consume(queue, (msg) => {
+ const event = JSON.parse(msg.content.toString());
+ console.log(`Đã nhận: ${event.type}`);
+
+ if (event.type === 'ORDER_CREATED') {
+ // Xử lý đơn hàng
+ processOrder(event.data);
+ }
+
+ channel.ack(msg);
+ });
+}
+```
+
+#### Luồng Sự Kiện
+
+```java
+// Ví dụ nhà sản xuất Kafka (Java)
+Properties props = new Properties();
+props.put("bootstrap.servers", "localhost:9092");
+props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
+props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
+
+Producer producer = new KafkaProducer<>(props);
+
+String topic = "order-events";
+String key = order.getId();
+String value = objectMapper.writeValueAsString(order);
+
+ProducerRecord record = new ProducerRecord<>(topic, key, value);
+producer.send(record);
+producer.close();
+```
+
+```java
+// Ví dụ người tiêu thụ Kafka (Java)
+Properties props = new Properties();
+props.put("bootstrap.servers", "localhost:9092");
+props.put("group.id", "order-processing-group");
+props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
+props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
+
+Consumer consumer = new KafkaConsumer<>(props);
+consumer.subscribe(Arrays.asList("order-events"));
+
+while (true) {
+ ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
+ for (ConsumerRecord record : records) {
+ String key = record.key();
+ String value = record.value();
+
+ Order order = objectMapper.readValue(value, Order.class);
+ processOrder(order);
+ }
+}
+```
+
+## Khám Phá Dịch Vụ và API Gateway
+
+### Khám Phá Dịch Vụ
+
+```yaml
+# Ví dụ đăng ký dịch vụ Consul
+{
+ "service": {
+ "name": "product-service",
+ "id": "product-service-1",
+ "tags": ["api", "v1"],
+ "address": "10.0.0.1",
+ "port": 8080,
+ "checks": [
+ {
+ "http": "http://10.0.0.1:8080/health",
+ "interval": "10s"
+ }
+ ]
+ }
+}
+```
+
+### API Gateway
+
+```yaml
+# Ví dụ cấu hình Kong API Gateway
+services:
+ - name: product-service
+ url: http://product-service:8080
+ routes:
+ - name: product-routes
+ paths:
+ - /api/products
+ strip_path: true
+ plugins:
+ - name: rate-limiting
+ config:
+ minute: 100
+ - name: jwt
+```
+
+## Quản Lý Dữ Liệu trong Microservices
+
+### Cơ Sở Dữ Liệu cho Mỗi Dịch Vụ
+
+```yaml
+# Ví dụ docker-compose.yml cho nhiều cơ sở dữ liệu
+version: '3'
+services:
+ product-service:
+ build: ./product-service
+ depends_on:
+ - product-db
+ environment:
+ - DB_HOST=product-db
+ - DB_PORT=5432
+ - DB_NAME=productdb
+
+ product-db:
+ image: postgres:13
+ environment:
+ - POSTGRES_DB=productdb
+ - POSTGRES_USER=user
+ - POSTGRES_PASSWORD=password
+ volumes:
+ - product-db-data:/var/lib/postgresql/data
+
+ order-service:
+ build: ./order-service
+ depends_on:
+ - order-db
+ environment:
+ - DB_HOST=order-db
+ - DB_PORT=27017
+ - DB_NAME=orderdb
+
+ order-db:
+ image: mongo:4.4
+ environment:
+ - MONGO_INITDB_DATABASE=orderdb
+ volumes:
+ - order-db-data:/data/db
+
+volumes:
+ product-db-data:
+ order-db-data:
+```
+
+### Mẫu CQRS
+
+```csharp
+// Phía lệnh
+public class CreateOrderCommand
+{
+ public string CustomerId { get; set; }
+ public List Items { get; set; }
+}
+
+public class OrderCommandHandler
+{
+ private readonly IOrderRepository _repository;
+ private readonly IEventBus _eventBus;
+
+ public OrderCommandHandler(IOrderRepository repository, IEventBus eventBus)
+ {
+ _repository = repository;
+ _eventBus = eventBus;
+ }
+
+ public async Task Handle(CreateOrderCommand command)
+ {
+ var order = new Order(Guid.NewGuid(), command.CustomerId, command.Items);
+ await _repository.SaveAsync(order);
+
+ await _eventBus.PublishAsync(new OrderCreatedEvent
+ {
+ OrderId = order.Id,
+ CustomerId = order.CustomerId,
+ Items = order.Items
+ });
+ }
+}
+
+// Phía truy vấn
+public class OrderQueryService
+{
+ private readonly IOrderReadModel _readModel;
+
+ public OrderQueryService(IOrderReadModel readModel)
+ {
+ _readModel = readModel;
+ }
+
+ public async Task GetOrderAsync(Guid orderId)
+ {
+ return await _readModel.GetOrderAsync(orderId);
+ }
+
+ public async Task> GetCustomerOrdersAsync(string customerId)
+ {
+ return await _readModel.GetCustomerOrdersAsync(customerId);
+ }
+}
+```
+
+## Triển Khai Microservices
+
+### Docker Containers
+
+```dockerfile
+# Ví dụ Dockerfile cho một microservice
+FROM node:14-alpine
+
+WORKDIR /app
+
+COPY package*.json ./
+RUN npm install --production
+
+COPY . .
+
+EXPOSE 8080
+
+CMD ["node", "server.js"]
+```
+
+### Kubernetes
+
+```yaml
+# Ví dụ triển khai Kubernetes cho một microservice
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: product-service
+ labels:
+ app: product-service
+spec:
+ replicas: 3
+ selector:
+ matchLabels:
+ app: product-service
+ template:
+ metadata:
+ labels:
+ app: product-service
+ spec:
+ containers:
+ - name: product-service
+ image: my-registry/product-service:1.0.0
+ ports:
+ - containerPort: 8080
+ env:
+ - name: DB_HOST
+ value: product-db-service
+ - name: DB_PORT
+ value: "5432"
+ - name: DB_NAME
+ value: productdb
+ livenessProbe:
+ httpGet:
+ path: /health
+ port: 8080
+ initialDelaySeconds: 30
+ periodSeconds: 10
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: product-service
+spec:
+ selector:
+ app: product-service
+ ports:
+ - port: 80
+ targetPort: 8080
+ type: ClusterIP
+```
+
+## Giám Sát và Khả Năng Quan Sát
+
+### Truy Vết Phân Tán
+
+```java
+// Ví dụ sử dụng Spring Cloud Sleuth và Zipkin
+@RestController
+public class ProductController {
+
+ private final ProductService productService;
+
+ @Autowired
+ public ProductController(ProductService productService) {
+ this.productService = productService;
+ }
+
+ @GetMapping("/products/{id}")
+ public Product getProduct(@PathVariable String id) {
+ // Truy vết được tự động xử lý bởi Sleuth
+ return productService.getProduct(id);
+ }
+}
+```
+
+### Thu Thập Số Liệu
+
+```yaml
+# Ví dụ cấu hình Prometheus
+global:
+ scrape_interval: 15s
+
+scrape_configs:
+ - job_name: 'product-service'
+ metrics_path: '/actuator/prometheus'
+ static_configs:
+ - targets: ['product-service:8080']
+
+ - job_name: 'order-service'
+ metrics_path: '/actuator/prometheus'
+ static_configs:
+ - targets: ['order-service:8080']
+```
+
+## Thách Thức và Phương Pháp Tốt Nhất
+
+### Thách Thức
+
+1. **Độ Phức Tạp của Hệ Thống Phân Tán**: Gỡ lỗi và kiểm tra trở nên khó khăn hơn.
+2. **Tính Nhất Quán của Dữ Liệu**: Duy trì tính nhất quán giữa các dịch vụ là một thách thức.
+3. **Ranh Giới Dịch Vụ**: Xác định ranh giới dịch vụ đúng đắn đòi hỏi chuyên môn về miền.
+4. **Phụ Phí Vận Hành**: Nhiều dịch vụ hơn đồng nghĩa với nhiều cơ sở hạ tầng cần quản lý hơn.
+5. **Độ Trễ Mạng**: Giao tiếp giữa các dịch vụ thêm độ trễ.
+
+### Phương Pháp Tốt Nhất
+
+1. **Bắt Đầu Nguyên Khối**: Bắt đầu với một ứng dụng nguyên khối và trích xuất microservices khi cần thiết.
+2. **Thiết Kế cho Lỗi**: Triển khai các bộ ngắt mạch, thử lại và dự phòng.
+3. **Tự Động Hóa Mọi Thứ**: Sử dụng đường ống CI/CD cho tất cả các dịch vụ.
+4. **Triển Khai Giám Sát**: Ghi nhật ký, số liệu và truy vết toàn diện.
+5. **Sử Dụng Container**: Containerize các dịch vụ để đảm bảo tính nhất quán giữa các môi trường.
+6. **Phiên Bản API**: Triển khai phiên bản API thích hợp để quản lý các thay đổi.
+7. **Tài Liệu**: Duy trì tài liệu rõ ràng cho tất cả các dịch vụ và API.
+8. **Kiểm Tra**: Triển khai các chiến lược kiểm tra toàn diện, bao gồm kiểm tra hợp đồng.
+
+## Tài Liệu Tham Khảo
+
+- [Microservices.io](https://microservices.io/)
+- [Martin Fowler về Microservices](https://martinfowler.com/articles/microservices.html)
+- [Sam Newman - Xây Dựng Microservices](https://samnewman.io/books/building_microservices/)
+- [Chris Richardson - Mẫu Microservices](https://microservices.io/book)
diff --git a/i18n/vi/testing/unit-testing_vi.md b/i18n/vi/testing/unit-testing_vi.md
new file mode 100644
index 0000000..018a504
--- /dev/null
+++ b/i18n/vi/testing/unit-testing_vi.md
@@ -0,0 +1,467 @@
+# Kiểm Thử Đơn Vị
+
+Kiểm thử đơn vị là một phương pháp kiểm thử phần mềm trong đó các đơn vị hoặc thành phần riêng lẻ của phần mềm được kiểm tra một cách cô lập với phần còn lại của hệ thống.
+
+## Kiểm Thử Đơn Vị là gì?
+
+Một bài kiểm thử đơn vị xác minh rằng một phần mã nhỏ, cô lập (một "đơn vị") hoạt động chính xác như mong đợi của nhà phát triển. Các đơn vị thường là:
+
+- Các hàm hoặc phương thức riêng lẻ
+- Các lớp
+- Các mô-đun hoặc thành phần
+
+Mục tiêu là xác nhận rằng mỗi đơn vị của phần mềm hoạt động như thiết kế.
+
+## Lợi Ích của Kiểm Thử Đơn Vị
+
+- **Phát Hiện Lỗi Sớm**: Phát hiện lỗi sớm trong chu trình phát triển
+- **Tạo Điều Kiện cho Thay Đổi**: Giúp việc tái cấu trúc mã và thêm tính năng mới dễ dàng hơn
+- **Tài Liệu**: Các bài kiểm thử đóng vai trò như tài liệu về cách mã nên hoạt động
+- **Cải Thiện Thiết Kế**: Khuyến khích thiết kế phần mềm và tính mô-đun tốt hơn
+- **Tự Tin**: Cung cấp sự tự tin rằng mã hoạt động như mong đợi
+- **Giảm Chi Phí**: Rẻ hơn để sửa lỗi được phát hiện trong quá trình kiểm thử đơn vị hơn là các giai đoạn sau
+
+## Nguyên Tắc Kiểm Thử Đơn Vị
+
+### Nguyên Tắc FIRST
+
+- **Fast (Nhanh)**: Các bài kiểm thử nên chạy nhanh
+- **Independent (Độc lập)**: Các bài kiểm thử không nên phụ thuộc vào nhau
+- **Repeatable (Lặp lại được)**: Các bài kiểm thử nên cho kết quả giống nhau mỗi lần chạy
+- **Self-validating (Tự xác thực)**: Các bài kiểm thử nên tự động xác định xem chúng đã vượt qua hay thất bại
+- **Timely (Kịp thời)**: Các bài kiểm thử nên được viết vào thời điểm thích hợp (lý tưởng là trước khi viết mã)
+
+### Mẫu AAA
+
+- **Arrange (Sắp xếp)**: Thiết lập điều kiện kiểm thử
+- **Act (Hành động)**: Thực thi mã đang được kiểm thử
+- **Assert (Khẳng định)**: Xác minh kết quả là như mong đợi
+
+## Các Framework Kiểm Thử Đơn Vị
+
+### JavaScript (Jest)
+
+```javascript
+// math.js
+function add(a, b) {
+ return a + b;
+}
+
+function subtract(a, b) {
+ return a - b;
+}
+
+module.exports = { add, subtract };
+
+// math.test.js
+const { add, subtract } = require('./math');
+
+describe('Các hàm toán học', () => {
+ test('hàm add nên cộng hai số chính xác', () => {
+ // Arrange
+ const a = 5;
+ const b = 3;
+
+ // Act
+ const result = add(a, b);
+
+ // Assert
+ expect(result).toBe(8);
+ });
+
+ test('hàm subtract nên trừ hai số chính xác', () => {
+ // Arrange
+ const a = 5;
+ const b = 3;
+
+ // Act
+ const result = subtract(a, b);
+
+ // Assert
+ expect(result).toBe(2);
+ });
+});
+```
+
+### Python (pytest)
+
+```python
+# math_utils.py
+def add(a, b):
+ return a + b
+
+def subtract(a, b):
+ return a - b
+
+# test_math_utils.py
+import pytest
+from math_utils import add, subtract
+
+def test_add():
+ # Arrange
+ a = 5
+ b = 3
+
+ # Act
+ result = add(a, b)
+
+ # Assert
+ assert result == 8
+
+def test_subtract():
+ # Arrange
+ a = 5
+ b = 3
+
+ # Act
+ result = subtract(a, b)
+
+ # Assert
+ assert result == 2
+```
+
+### Java (JUnit)
+
+```java
+// MathUtils.java
+public class MathUtils {
+ public int add(int a, int b) {
+ return a + b;
+ }
+
+ public int subtract(int a, int b) {
+ return a - b;
+ }
+}
+
+// MathUtilsTest.java
+import static org.junit.jupiter.api.Assertions.assertEquals;
+import org.junit.jupiter.api.Test;
+
+public class MathUtilsTest {
+
+ @Test
+ public void testAdd() {
+ // Arrange
+ MathUtils mathUtils = new MathUtils();
+ int a = 5;
+ int b = 3;
+
+ // Act
+ int result = mathUtils.add(a, b);
+
+ // Assert
+ assertEquals(8, result);
+ }
+
+ @Test
+ public void testSubtract() {
+ // Arrange
+ MathUtils mathUtils = new MathUtils();
+ int a = 5;
+ int b = 3;
+
+ // Act
+ int result = mathUtils.subtract(a, b);
+
+ // Assert
+ assertEquals(2, result);
+ }
+}
+```
+
+### C# (xUnit)
+
+```csharp
+// MathUtils.cs
+public class MathUtils
+{
+ public int Add(int a, int b)
+ {
+ return a + b;
+ }
+
+ public int Subtract(int a, int b)
+ {
+ return a - b;
+ }
+}
+
+// MathUtilsTests.cs
+using Xunit;
+
+public class MathUtilsTests
+{
+ [Fact]
+ public void Add_ShouldCorrectlyAddTwoNumbers()
+ {
+ // Arrange
+ var mathUtils = new MathUtils();
+ int a = 5;
+ int b = 3;
+
+ // Act
+ int result = mathUtils.Add(a, b);
+
+ // Assert
+ Assert.Equal(8, result);
+ }
+
+ [Fact]
+ public void Subtract_ShouldCorrectlySubtractTwoNumbers()
+ {
+ // Arrange
+ var mathUtils = new MathUtils();
+ int a = 5;
+ int b = 3;
+
+ // Act
+ int result = mathUtils.Subtract(a, b);
+
+ // Assert
+ Assert.Equal(2, result);
+ }
+}
+```
+
+## Test Doubles
+
+Test doubles là các đối tượng thay thế các thành phần thực trong các bài kiểm thử để cô lập mã đang được kiểm thử.
+
+### Các Loại Test Doubles
+
+#### Dummy
+
+Các đối tượng được truyền qua nhưng không bao giờ thực sự được sử dụng.
+
+```javascript
+// Ví dụ JavaScript
+function createUser(user, logger) {
+ // logger không được sử dụng trong bài kiểm thử này
+ return { id: 123, ...user };
+}
+
+test('createUser nên thêm một ID vào user', () => {
+ // Arrange
+ const dummyLogger = {}; // Đối tượng giả không bao giờ được sử dụng
+ const user = { name: 'John' };
+
+ // Act
+ const result = createUser(user, dummyLogger);
+
+ // Assert
+ expect(result.id).toBeDefined();
+ expect(result.name).toBe('John');
+});
+```
+
+#### Stub
+
+Các đối tượng cung cấp câu trả lời được định nghĩa trước cho các lời gọi được thực hiện trong quá trình kiểm thử.
+
+```java
+// Ví dụ Java
+public interface WeatherService {
+ int getCurrentTemperature(String city);
+}
+
+// Triển khai stub
+public class WeatherServiceStub implements WeatherService {
+ @Override
+ public int getCurrentTemperature(String city) {
+ return 25; // Luôn trả về 25°C bất kể thành phố nào
+ }
+}
+
+@Test
+public void testWeatherReporter() {
+ // Arrange
+ WeatherService stubService = new WeatherServiceStub();
+ WeatherReporter reporter = new WeatherReporter(stubService);
+
+ // Act
+ String report = reporter.generateReport("London");
+
+ // Assert
+ assertEquals("Nhiệt độ hiện tại ở London: 25°C", report);
+}
+```
+
+#### Spy
+
+Các đối tượng ghi lại các lời gọi được thực hiện đến chúng.
+
+```python
+# Ví dụ Python
+class EmailServiceSpy:
+ def __init__(self):
+ self.emails_sent = []
+
+ def send_email(self, to, subject, body):
+ self.emails_sent.append({
+ 'to': to,
+ 'subject': subject,
+ 'body': body
+ })
+
+def test_user_registration_sends_welcome_email():
+ # Arrange
+ email_service = EmailServiceSpy()
+ user_service = UserService(email_service)
+
+ # Act
+ user_service.register("john@example.com", "password123")
+
+ # Assert
+ assert len(email_service.emails_sent) == 1
+ assert email_service.emails_sent[0]['to'] == "john@example.com"
+ assert "Chào mừng" in email_service.emails_sent[0]['subject']
+```
+
+#### Mock
+
+Các đối tượng xác minh rằng các phương thức cụ thể đã được gọi với các đối số cụ thể.
+
+```csharp
+// Ví dụ C# với Moq
+[Fact]
+public void Register_ShouldSendWelcomeEmail()
+{
+ // Arrange
+ var mockEmailService = new Mock();
+ var userService = new UserService(mockEmailService.Object);
+
+ // Act
+ userService.Register("john@example.com", "password123");
+
+ // Assert
+ mockEmailService.Verify(
+ x => x.SendEmail(
+ "john@example.com",
+ It.Is(s => s.Contains("Chào mừng")),
+ It.IsAny()
+ ),
+ Times.Once
+ );
+}
+```
+
+#### Fake
+
+Các đối tượng có triển khai hoạt động nhưng không phù hợp cho môi trường sản xuất.
+
+```javascript
+// Ví dụ JavaScript
+class FakeUserRepository {
+ constructor() {
+ this.users = [];
+ this.nextId = 1;
+ }
+
+ create(userData) {
+ const user = { id: this.nextId++, ...userData };
+ this.users.push(user);
+ return user;
+ }
+
+ findById(id) {
+ return this.users.find(user => user.id === id);
+ }
+}
+
+test('UserService nên tạo một người dùng', () => {
+ // Arrange
+ const fakeRepo = new FakeUserRepository();
+ const userService = new UserService(fakeRepo);
+
+ // Act
+ const user = userService.createUser('John', 'john@example.com');
+
+ // Assert
+ expect(user.id).toBe(1);
+ expect(user.name).toBe('John');
+ expect(fakeRepo.findById(1)).toEqual(user);
+});
+```
+
+## Độ Phủ Kiểm Thử
+
+Độ phủ kiểm thử đo lường bao nhiêu mã của bạn được thực thi trong quá trình kiểm thử.
+
+### Các Số Liệu Độ Phủ
+
+- **Độ Phủ Dòng**: Phần trăm dòng được thực thi trong quá trình kiểm thử
+- **Độ Phủ Nhánh**: Phần trăm nhánh (if/else, switch) được thực thi trong quá trình kiểm thử
+- **Độ Phủ Hàm**: Phần trăm hàm được gọi trong quá trình kiểm thử
+- **Độ Phủ Câu Lệnh**: Phần trăm câu lệnh được thực thi trong quá trình kiểm thử
+
+### Ví Dụ Báo Cáo Độ Phủ (Jest)
+
+```
+--------------------|---------|----------|---------|---------|-------------------
+File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s
+--------------------|---------|----------|---------|---------|-------------------
+All files | 85.71 | 66.67 | 100 | 85.71 |
+ math.js | 100 | 100 | 100 | 100 |
+ string-utils.js | 71.43 | 33.33 | 100 | 71.43 | 15-18
+--------------------|---------|----------|---------|---------|-------------------
+```
+
+## Các Phương Pháp Tốt Nhất cho Kiểm Thử Đơn Vị
+
+1. **Kiểm Thử Một Thứ Tại Một Thời Điểm**: Mỗi bài kiểm thử nên xác minh một hành vi cụ thể.
+2. **Giữ Các Bài Kiểm Thử Đơn Giản**: Các bài kiểm thử nên dễ hiểu và duy trì.
+3. **Sử Dụng Tên Bài Kiểm Thử Mô Tả**: Tên nên mô tả rõ ràng những gì đang được kiểm thử.
+4. **Cô Lập Đơn Vị**: Sử dụng test doubles để cô lập đơn vị khỏi các phụ thuộc của nó.
+5. **Kiểm Thử Các Trường Hợp Biên**: Bao gồm các bài kiểm thử cho điều kiện biên và trường hợp lỗi.
+6. **Không Kiểm Thử Framework**: Tập trung vào việc kiểm thử mã của bạn, không phải framework hoặc ngôn ngữ.
+7. **Duy Trì Tính Độc Lập của Bài Kiểm Thử**: Các bài kiểm thử không nên phụ thuộc vào nhau hoặc chạy theo một thứ tự cụ thể.
+8. **Tránh Logic trong Bài Kiểm Thử**: Các bài kiểm thử nên đơn giản với logic tối thiểu.
+9. **Viết Bài Kiểm Thử Trước (TDD)**: Cân nhắc viết bài kiểm thử trước khi triển khai mã.
+10. **Tái Cấu Trúc Bài Kiểm Thử**: Giữ bài kiểm thử sạch sẽ và có thể bảo trì, giống như mã sản xuất.
+
+## Phát Triển Hướng Kiểm Thử (TDD)
+
+TDD là một quy trình phát triển trong đó các bài kiểm thử được viết trước mã. Chu kỳ là:
+
+1. **Red (Đỏ)**: Viết một bài kiểm thử thất bại
+2. **Green (Xanh)**: Viết mã tối thiểu để làm cho bài kiểm thử vượt qua
+3. **Refactor (Tái cấu trúc)**: Cải thiện mã trong khi giữ cho các bài kiểm thử vượt qua
+
+### Ví Dụ TDD (JavaScript)
+
+```javascript
+// Bước 1: Viết một bài kiểm thử thất bại
+test('isPalindrome nên trả về true cho các chuỗi đối xứng', () => {
+ expect(isPalindrome('racecar')).toBe(true);
+});
+
+// Bước 2: Viết mã tối thiểu để làm cho nó vượt qua
+function isPalindrome(str) {
+ return str === str.split('').reverse().join('');
+}
+
+// Bước 3: Thêm nhiều bài kiểm thử
+test('isPalindrome nên trả về false cho các chuỗi không đối xứng', () => {
+ expect(isPalindrome('hello')).toBe(false);
+});
+
+test('isPalindrome nên không phân biệt chữ hoa chữ thường', () => {
+ expect(isPalindrome('Racecar')).toBe(true);
+});
+
+// Bước 4: Tái cấu trúc mã
+function isPalindrome(str) {
+ const normalized = str.toLowerCase();
+ return normalized === normalized.split('').reverse().join('');
+}
+```
+
+## Tài Liệu Tham Khảo
+
+- [Martin Fowler về Kiểm Thử Đơn Vị](https://martinfowler.com/bliki/UnitTest.html)
+- [Phát Triển Hướng Kiểm Thử bởi Ví Dụ](https://www.amazon.com/Test-Driven-Development-Kent-Beck/dp/0321146530)
+- [Tài Liệu Jest](https://jestjs.io/docs/getting-started)
+- [Tài Liệu pytest](https://docs.pytest.org/)
+- [Tài Liệu JUnit](https://junit.org/junit5/docs/current/user-guide/)
+- [Tài Liệu xUnit](https://xunit.net/docs/getting-started/netcore/cmdline)
diff --git a/snippets/algorithms/graph-traversal/GraphTraversal.cs b/snippets/algorithms/graph-traversal/GraphTraversal.cs
new file mode 100644
index 0000000..225b3c1
--- /dev/null
+++ b/snippets/algorithms/graph-traversal/GraphTraversal.cs
@@ -0,0 +1,312 @@
+using System;
+using System.Collections.Generic;
+using System.Linq;
+using System.Threading;
+
+/**
+ * Graph Traversal Algorithms in C#
+ *
+ * This program demonstrates BFS and DFS traversal algorithms on a graph.
+ *
+ * Compile: dotnet build
+ * Run: dotnet run
+ */
+namespace GraphTraversalAlgorithms
+{
+ ///
+ /// A graph class using adjacency list representation
+ ///
+ public class Graph
+ {
+ // Adjacency list representation
+ private Dictionary> adjacencyList;
+
+ ///
+ /// Initializes a new empty graph
+ ///
+ public Graph()
+ {
+ adjacencyList = new Dictionary>();
+ }
+
+ ///
+ /// Adds a vertex to the graph
+ ///
+ /// The vertex to add
+ public void AddVertex(string vertex)
+ {
+ if (!adjacencyList.ContainsKey(vertex))
+ {
+ adjacencyList[vertex] = new List();
+ }
+ }
+
+ ///
+ /// Adds an edge between two vertices
+ ///
+ /// First vertex
+ /// Second vertex
+ public void AddEdge(string v1, string v2)
+ {
+ // Ensure both vertices exist
+ AddVertex(v1);
+ AddVertex(v2);
+
+ // Add the edge (undirected graph)
+ adjacencyList[v1].Add(v2);
+ adjacencyList[v2].Add(v1);
+ }
+
+ ///
+ /// Helper method to get sorted neighbors for consistent output
+ ///
+ /// The vertex to get neighbors for
+ /// Sorted list of neighbors
+ private List GetSortedNeighbors(string vertex)
+ {
+ var neighbors = new List(adjacencyList[vertex]);
+ neighbors.Sort();
+ return neighbors;
+ }
+
+ ///
+ /// Performs a breadth-first search traversal starting from the given vertex
+ ///
+ /// Starting vertex
+ /// List of vertices in the order they were visited
+ public List BFS(string start)
+ {
+ if (!adjacencyList.ContainsKey(start))
+ {
+ return new List();
+ }
+
+ HashSet visited = new HashSet();
+ Queue queue = new Queue();
+ List result = new List();
+
+ // Initialize with starting vertex
+ visited.Add(start);
+ queue.Enqueue(start);
+
+ Console.WriteLine($"Starting BFS traversal from vertex {start}");
+
+ while (queue.Count > 0)
+ {
+ // Dequeue the first vertex
+ string vertex = queue.Dequeue();
+ result.Add(vertex);
+
+ Console.WriteLine($"Visiting: {vertex}");
+ Console.WriteLine($"Queue: [{string.Join(", ", queue)}]");
+ Console.WriteLine($"Visited so far: [{string.Join(", ", result)}]");
+ Console.WriteLine("------------------------------");
+
+ // Pause for demonstration
+ Thread.Sleep(500);
+
+ // Get sorted neighbors for consistent order
+ List neighbors = GetSortedNeighbors(vertex);
+
+ // Enqueue all unvisited neighbors
+ foreach (string neighbor in neighbors)
+ {
+ if (!visited.Contains(neighbor))
+ {
+ visited.Add(neighbor);
+ queue.Enqueue(neighbor);
+ }
+ }
+ }
+
+ return result;
+ }
+
+ ///
+ /// Performs a recursive depth-first search traversal starting from the given vertex
+ ///
+ /// Starting vertex
+ /// List of vertices in the order they were visited
+ public List DFSRecursive(string start)
+ {
+ if (!adjacencyList.ContainsKey(start))
+ {
+ return new List();
+ }
+
+ HashSet visited = new HashSet();
+ List result = new List();
+
+ Console.WriteLine($"Starting recursive DFS traversal from vertex {start}");
+
+ DFSHelper(start, visited, result);
+
+ return result;
+ }
+
+ ///
+ /// Helper method for recursive DFS
+ ///
+ /// Current vertex
+ /// Set of visited vertices
+ /// List to store the traversal result
+ private void DFSHelper(string vertex, HashSet visited, List result)
+ {
+ // Mark as visited and add to result
+ visited.Add(vertex);
+ result.Add(vertex);
+
+ Console.WriteLine($"Visiting: {vertex}");
+ Console.WriteLine($"Visited so far: [{string.Join(", ", result)}]");
+ Console.WriteLine("------------------------------");
+
+ // Pause for demonstration
+ Thread.Sleep(500);
+
+ // Get sorted neighbors for consistent order
+ List neighbors = GetSortedNeighbors(vertex);
+
+ // Recursively visit all unvisited neighbors
+ foreach (string neighbor in neighbors)
+ {
+ if (!visited.Contains(neighbor))
+ {
+ DFSHelper(neighbor, visited, result);
+ }
+ }
+ }
+
+ ///
+ /// Performs an iterative depth-first search traversal starting from the given vertex
+ ///
+ /// Starting vertex
+ /// List of vertices in the order they were visited
+ public List DFSIterative(string start)
+ {
+ if (!adjacencyList.ContainsKey(start))
+ {
+ return new List();
+ }
+
+ HashSet visited = new HashSet();
+ Stack stack = new Stack();
+ List result = new List();
+
+ // Initialize with starting vertex
+ stack.Push(start);
+
+ Console.WriteLine($"Starting iterative DFS traversal from vertex {start}");
+
+ while (stack.Count > 0)
+ {
+ // Pop the top vertex
+ string vertex = stack.Pop();
+
+ // If not visited, process it
+ if (!visited.Contains(vertex))
+ {
+ visited.Add(vertex);
+ result.Add(vertex);
+
+ Console.WriteLine($"Visiting: {vertex}");
+ Console.WriteLine($"Stack: [{string.Join(", ", stack)}]");
+ Console.WriteLine($"Visited so far: [{string.Join(", ", result)}]");
+ Console.WriteLine("------------------------------");
+
+ // Pause for demonstration
+ Thread.Sleep(500);
+
+ // Get sorted neighbors in reverse order for stack
+ List neighbors = GetSortedNeighbors(vertex);
+ neighbors.Reverse();
+
+ // Push all unvisited neighbors onto the stack
+ foreach (string neighbor in neighbors)
+ {
+ if (!visited.Contains(neighbor))
+ {
+ stack.Push(neighbor);
+ }
+ }
+ }
+ }
+
+ return result;
+ }
+
+ ///
+ /// Prints a visualization of the graph structure
+ ///
+ public void VisualizeGraph()
+ {
+ Console.WriteLine("\nGraph Structure:");
+ Console.WriteLine("------------------------------");
+
+ // Sort vertices for consistent output
+ var vertices = adjacencyList.Keys.ToList();
+ vertices.Sort();
+
+ foreach (string vertex in vertices)
+ {
+ List neighbors = GetSortedNeighbors(vertex);
+ Console.WriteLine($"{vertex} -> [{string.Join(", ", neighbors)}]");
+ }
+
+ Console.WriteLine("------------------------------");
+ }
+ }
+
+ public class Program
+ {
+ ///
+ /// Creates a sample graph for demonstration
+ ///
+ /// A sample graph
+ public static Graph CreateSampleGraph()
+ {
+ Graph g = new Graph();
+
+ // Add edges to build this graph:
+ // A
+ // / \
+ // B C
+ // / \ \
+ // D E---F
+
+ string[,] edges = {
+ {"A", "B"}, {"A", "C"},
+ {"B", "D"}, {"B", "E"},
+ {"C", "F"}, {"E", "F"}
+ };
+
+ for (int i = 0; i < edges.GetLength(0); i++)
+ {
+ g.AddEdge(edges[i, 0], edges[i, 1]);
+ }
+
+ return g;
+ }
+
+ public static void Main(string[] args)
+ {
+ // Create a sample graph
+ Graph g = CreateSampleGraph();
+ g.VisualizeGraph();
+
+ // Demonstrate BFS
+ Console.WriteLine("\n=== BFS Traversal ===");
+ List bfsResult = g.BFS("A");
+ Console.WriteLine($"BFS Result: [{string.Join(", ", bfsResult)}]");
+
+ // Demonstrate recursive DFS
+ Console.WriteLine("\n=== DFS Traversal (Recursive) ===");
+ List dfsRecResult = g.DFSRecursive("A");
+ Console.WriteLine($"DFS Recursive Result: [{string.Join(", ", dfsRecResult)}]");
+
+ // Demonstrate iterative DFS
+ Console.WriteLine("\n=== DFS Traversal (Iterative) ===");
+ List dfsIterResult = g.DFSIterative("A");
+ Console.WriteLine($"DFS Iterative Result: [{string.Join(", ", dfsIterResult)}]");
+ }
+ }
+}
\ No newline at end of file
diff --git a/snippets/algorithms/graph-traversal/GraphTraversal.java b/snippets/algorithms/graph-traversal/GraphTraversal.java
new file mode 100644
index 0000000..0fce771
--- /dev/null
+++ b/snippets/algorithms/graph-traversal/GraphTraversal.java
@@ -0,0 +1,295 @@
+import java.util.*;
+
+/**
+ * Graph Traversal Algorithms in Java
+ *
+ * This class demonstrates BFS and DFS traversal algorithms on a graph.
+ *
+ * Compile: javac GraphTraversal.java
+ * Run: java GraphTraversal
+ */
+public class GraphTraversal {
+
+ /**
+ * Graph class representing a graph using adjacency list
+ */
+ static class Graph {
+ // Adjacency list representation
+ private Map> adjacencyList;
+
+ /**
+ * Initialize an empty graph
+ */
+ public Graph() {
+ this.adjacencyList = new HashMap<>();
+ }
+
+ /**
+ * Add a vertex to the graph
+ * @param vertex The vertex to add
+ */
+ public void addVertex(String vertex) {
+ if (!adjacencyList.containsKey(vertex)) {
+ adjacencyList.put(vertex, new ArrayList<>());
+ }
+ }
+
+ /**
+ * Add an edge between two vertices
+ * @param v1 First vertex
+ * @param v2 Second vertex
+ */
+ public void addEdge(String v1, String v2) {
+ // Ensure both vertices exist
+ addVertex(v1);
+ addVertex(v2);
+
+ // Add the edge (undirected graph)
+ adjacencyList.get(v1).add(v2);
+ adjacencyList.get(v2).add(v1);
+ }
+
+ /**
+ * Helper method to get sorted neighbors for consistent output
+ * @param vertex The vertex to get neighbors for
+ * @return Sorted list of neighbors
+ */
+ private List getSortedNeighbors(String vertex) {
+ List neighbors = new ArrayList<>(adjacencyList.get(vertex));
+ Collections.sort(neighbors);
+ return neighbors;
+ }
+
+ /**
+ * Breadth-First Search traversal
+ * @param start Starting vertex
+ * @return List of vertices in the order they were visited
+ */
+ public List bfs(String start) {
+ if (!adjacencyList.containsKey(start)) {
+ return new ArrayList<>();
+ }
+
+ Set visited = new HashSet<>();
+ Queue queue = new LinkedList<>();
+ List result = new ArrayList<>();
+
+ // Initialize with starting vertex
+ visited.add(start);
+ queue.add(start);
+
+ System.out.println("Starting BFS traversal from vertex " + start);
+
+ while (!queue.isEmpty()) {
+ // Dequeue the first vertex
+ String vertex = queue.poll();
+ result.add(vertex);
+
+ System.out.println("Visiting: " + vertex);
+ System.out.println("Queue: " + queue);
+ System.out.println("Visited so far: " + result);
+ System.out.println("------------------------------");
+
+ // Pause for demonstration
+ try {
+ Thread.sleep(500);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+
+ // Get sorted neighbors for consistent order
+ List neighbors = getSortedNeighbors(vertex);
+
+ // Enqueue all unvisited neighbors
+ for (String neighbor : neighbors) {
+ if (!visited.contains(neighbor)) {
+ visited.add(neighbor);
+ queue.add(neighbor);
+ }
+ }
+ }
+
+ return result;
+ }
+
+ /**
+ * Depth-First Search traversal (recursive)
+ * @param start Starting vertex
+ * @return List of vertices in the order they were visited
+ */
+ public List dfsRecursive(String start) {
+ if (!adjacencyList.containsKey(start)) {
+ return new ArrayList<>();
+ }
+
+ Set visited = new HashSet<>();
+ List result = new ArrayList<>();
+
+ System.out.println("Starting recursive DFS traversal from vertex " + start);
+
+ dfsHelper(start, visited, result);
+
+ return result;
+ }
+
+ /**
+ * Helper method for recursive DFS
+ * @param vertex Current vertex
+ * @param visited Set of visited vertices
+ * @param result List to store the traversal result
+ */
+ private void dfsHelper(String vertex, Set visited, List result) {
+ // Mark as visited and add to result
+ visited.add(vertex);
+ result.add(vertex);
+
+ System.out.println("Visiting: " + vertex);
+ System.out.println("Visited so far: " + result);
+ System.out.println("------------------------------");
+
+ // Pause for demonstration
+ try {
+ Thread.sleep(500);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+
+ // Get sorted neighbors for consistent order
+ List neighbors = getSortedNeighbors(vertex);
+
+ // Recursively visit all unvisited neighbors
+ for (String neighbor : neighbors) {
+ if (!visited.contains(neighbor)) {
+ dfsHelper(neighbor, visited, result);
+ }
+ }
+ }
+
+ /**
+ * Depth-First Search traversal (iterative)
+ * @param start Starting vertex
+ * @return List of vertices in the order they were visited
+ */
+ public List dfsIterative(String start) {
+ if (!adjacencyList.containsKey(start)) {
+ return new ArrayList<>();
+ }
+
+ Set visited = new HashSet<>();
+ Stack stack = new Stack<>();
+ List result = new ArrayList<>();
+
+ // Initialize with starting vertex
+ stack.push(start);
+
+ System.out.println("Starting iterative DFS traversal from vertex " + start);
+
+ while (!stack.isEmpty()) {
+ // Pop the top vertex
+ String vertex = stack.pop();
+
+ // If not visited, process it
+ if (!visited.contains(vertex)) {
+ visited.add(vertex);
+ result.add(vertex);
+
+ System.out.println("Visiting: " + vertex);
+ System.out.println("Stack: " + stack);
+ System.out.println("Visited so far: " + result);
+ System.out.println("------------------------------");
+
+ // Pause for demonstration
+ try {
+ Thread.sleep(500);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+
+ // Get sorted neighbors in reverse order for stack
+ List neighbors = getSortedNeighbors(vertex);
+ Collections.reverse(neighbors);
+
+ // Push all unvisited neighbors onto the stack
+ for (String neighbor : neighbors) {
+ if (!visited.contains(neighbor)) {
+ stack.push(neighbor);
+ }
+ }
+ }
+ }
+
+ return result;
+ }
+
+ /**
+ * Print the graph structure
+ */
+ public void visualizeGraph() {
+ System.out.println("\nGraph Structure:");
+ System.out.println("------------------------------");
+
+ // Sort vertices for consistent output
+ List vertices = new ArrayList<>(adjacencyList.keySet());
+ Collections.sort(vertices);
+
+ for (String vertex : vertices) {
+ List neighbors = getSortedNeighbors(vertex);
+ System.out.println(vertex + " -> " + neighbors);
+ }
+
+ System.out.println("------------------------------");
+ }
+ }
+
+ /**
+ * Create a sample graph for demonstration
+ * @return A sample graph
+ */
+ public static Graph createSampleGraph() {
+ Graph g = new Graph();
+
+ // Add edges to build this graph:
+ // A
+ // / \
+ // B C
+ // / \ \
+ // D E---F
+
+ String[][] edges = {
+ {"A", "B"}, {"A", "C"},
+ {"B", "D"}, {"B", "E"},
+ {"C", "F"}, {"E", "F"}
+ };
+
+ for (String[] edge : edges) {
+ g.addEdge(edge[0], edge[1]);
+ }
+
+ return g;
+ }
+
+ /**
+ * Main method to demonstrate graph traversal algorithms
+ * @param args Command line arguments (not used)
+ */
+ public static void main(String[] args) {
+ // Create a sample graph
+ Graph g = createSampleGraph();
+ g.visualizeGraph();
+
+ // Demonstrate BFS
+ System.out.println("\n=== BFS Traversal ===");
+ List bfsResult = g.bfs("A");
+ System.out.println("BFS Result: " + bfsResult);
+
+ // Demonstrate recursive DFS
+ System.out.println("\n=== DFS Traversal (Recursive) ===");
+ List dfsRecResult = g.dfsRecursive("A");
+ System.out.println("DFS Recursive Result: " + dfsRecResult);
+
+ // Demonstrate iterative DFS
+ System.out.println("\n=== DFS Traversal (Iterative) ===");
+ List dfsIterResult = g.dfsIterative("A");
+ System.out.println("DFS Iterative Result: " + dfsIterResult);
+ }
+}
\ No newline at end of file
diff --git a/snippets/algorithms/graph-traversal/graphTraversal.js b/snippets/algorithms/graph-traversal/graphTraversal.js
new file mode 100644
index 0000000..9b2c596
--- /dev/null
+++ b/snippets/algorithms/graph-traversal/graphTraversal.js
@@ -0,0 +1,229 @@
+/**
+ * Graph Traversal Algorithms in JavaScript
+ *
+ * This module provides implementations of BFS and DFS for graph traversal.
+ *
+ * Example usage:
+ * node graphTraversal.js
+ */
+
+class Graph {
+ /**
+ * Initialize an empty graph
+ */
+ constructor() {
+ this.adjacencyList = {};
+ }
+
+ /**
+ * Add a vertex to the graph
+ * @param {string|number} vertex - The vertex to add
+ */
+ addVertex(vertex) {
+ if (!this.adjacencyList[vertex]) {
+ this.adjacencyList[vertex] = [];
+ }
+ }
+
+ /**
+ * Add an edge between two vertices
+ * @param {string|number} v1 - First vertex
+ * @param {string|number} v2 - Second vertex
+ */
+ addEdge(v1, v2) {
+ if (!this.adjacencyList[v1]) {
+ this.addVertex(v1);
+ }
+ if (!this.adjacencyList[v2]) {
+ this.addVertex(v2);
+ }
+
+ this.adjacencyList[v1].push(v2);
+ this.adjacencyList[v2].push(v1); // For undirected graph
+ }
+
+ /**
+ * Breadth-First Search traversal
+ * @param {string|number} start - Starting vertex
+ * @returns {Array} - Vertices in the order they were visited
+ */
+ bfs(start) {
+ if (!this.adjacencyList[start]) return [];
+
+ const queue = [start];
+ const visited = { [start]: true };
+ const result = [];
+
+ console.log(`Starting BFS traversal from vertex ${start}`);
+
+ while (queue.length) {
+ const currentVertex = queue.shift();
+ result.push(currentVertex);
+
+ console.log(`Visiting: ${currentVertex}`);
+ console.log(`Queue: [${queue.join(', ')}]`);
+ console.log(`Visited so far: [${result.join(', ')}]`);
+ console.log('-'.repeat(30));
+
+ // Get neighbors and sort for consistent order
+ const neighbors = [...this.adjacencyList[currentVertex]].sort();
+
+ for (const neighbor of neighbors) {
+ if (!visited[neighbor]) {
+ visited[neighbor] = true;
+ queue.push(neighbor);
+ }
+ }
+ }
+
+ return result;
+ }
+
+ /**
+ * Depth-First Search traversal (recursive)
+ * @param {string|number} start - Starting vertex
+ * @returns {Array} - Vertices in the order they were visited
+ */
+ dfsRecursive(start) {
+ if (!this.adjacencyList[start]) return [];
+
+ const visited = {};
+ const result = [];
+
+ console.log(`Starting recursive DFS traversal from vertex ${start}`);
+
+ const dfs = (vertex) => {
+ visited[vertex] = true;
+ result.push(vertex);
+
+ console.log(`Visiting: ${vertex}`);
+ console.log(`Visited so far: [${result.join(', ')}]`);
+ console.log('-'.repeat(30));
+
+ // Get neighbors and sort for consistent order
+ const neighbors = [...this.adjacencyList[vertex]].sort();
+
+ for (const neighbor of neighbors) {
+ if (!visited[neighbor]) {
+ dfs(neighbor);
+ }
+ }
+ };
+
+ dfs(start);
+ return result;
+ }
+
+ /**
+ * Depth-First Search traversal (iterative)
+ * @param {string|number} start - Starting vertex
+ * @returns {Array} - Vertices in the order they were visited
+ */
+ dfsIterative(start) {
+ if (!this.adjacencyList[start]) return [];
+
+ const stack = [start];
+ const visited = {};
+ const result = [];
+
+ console.log(`Starting iterative DFS traversal from vertex ${start}`);
+
+ while (stack.length) {
+ const currentVertex = stack.pop();
+
+ if (!visited[currentVertex]) {
+ visited[currentVertex] = true;
+ result.push(currentVertex);
+
+ console.log(`Visiting: ${currentVertex}`);
+ console.log(`Stack: [${stack.join(', ')}]`);
+ console.log(`Visited so far: [${result.join(', ')}]`);
+ console.log('-'.repeat(30));
+
+ // Get neighbors and sort in reverse order for stack
+ const neighbors = [...this.adjacencyList[currentVertex]].sort().reverse();
+
+ for (const neighbor of neighbors) {
+ if (!visited[neighbor]) {
+ stack.push(neighbor);
+ }
+ }
+ }
+ }
+
+ return result;
+ }
+
+ /**
+ * Print a visualization of the graph structure
+ */
+ visualizeGraph() {
+ console.log('\nGraph Structure:');
+ console.log('-'.repeat(30));
+
+ // Sort the vertices for consistent output
+ const vertices = Object.keys(this.adjacencyList).sort();
+
+ for (const vertex of vertices) {
+ const neighbors = [...this.adjacencyList[vertex]].sort();
+ console.log(`${vertex} -> [${neighbors.join(', ')}]`);
+ }
+
+ console.log('-'.repeat(30));
+ }
+}
+
+/**
+ * Create a sample graph for demonstration
+ * @returns {Graph} - A sample graph
+ */
+function createSampleGraph() {
+ const g = new Graph();
+
+ // Add edges to build this graph:
+ // A
+ // / \
+ // B C
+ // / \ \
+ // D E---F
+
+ const edges = [
+ ['A', 'B'], ['A', 'C'],
+ ['B', 'D'], ['B', 'E'],
+ ['C', 'F'], ['E', 'F']
+ ];
+
+ for (const [v1, v2] of edges) {
+ g.addEdge(v1, v2);
+ }
+
+ return g;
+}
+
+/**
+ * Main function to demonstrate graph traversal algorithms
+ */
+function main() {
+ const g = createSampleGraph();
+ g.visualizeGraph();
+
+ console.log('\n=== BFS Traversal ===');
+ const bfsResult = g.bfs('A');
+ console.log(`BFS Result: [${bfsResult.join(', ')}]`);
+
+ console.log('\n=== DFS Traversal (Recursive) ===');
+ const dfsRecResult = g.dfsRecursive('A');
+ console.log(`DFS Recursive Result: [${dfsRecResult.join(', ')}]`);
+
+ console.log('\n=== DFS Traversal (Iterative) ===');
+ const dfsIterResult = g.dfsIterative('A');
+ console.log(`DFS Iterative Result: [${dfsIterResult.join(', ')}]`);
+}
+
+// Run the main function if this file is executed directly
+if (require.main === module) {
+ main();
+}
+
+// Export the Graph class for use in other modules
+module.exports = { Graph, createSampleGraph };
\ No newline at end of file
diff --git a/snippets/algorithms/graph-traversal/graph_traversal.c b/snippets/algorithms/graph-traversal/graph_traversal.c
new file mode 100644
index 0000000..3ee5ea9
--- /dev/null
+++ b/snippets/algorithms/graph-traversal/graph_traversal.c
@@ -0,0 +1,542 @@
+#include
+#include
+#include
+#include
+
+/**
+ * Graph Traversal Algorithms in C
+ *
+ * This program demonstrates BFS and DFS traversal algorithms on a graph.
+ *
+ * Compile: gcc graph_traversal.c -o graph_traversal
+ * Run: ./graph_traversal
+ */
+
+#define MAX_VERTICES 10
+#define MAX_VERTEX_NAME 10
+
+// Graph structure using adjacency matrix
+typedef struct {
+ char vertices[MAX_VERTICES][MAX_VERTEX_NAME];
+ int adjacency_matrix[MAX_VERTICES][MAX_VERTICES];
+ int num_vertices;
+} Graph;
+
+// Queue for BFS traversal
+typedef struct {
+ int items[MAX_VERTICES];
+ int front;
+ int rear;
+} Queue;
+
+// Stack for iterative DFS traversal
+typedef struct {
+ int items[MAX_VERTICES];
+ int top;
+} Stack;
+
+// Queue functions
+Queue* create_queue() {
+ Queue* q = (Queue*)malloc(sizeof(Queue));
+ q->front = -1;
+ q->rear = -1;
+ return q;
+}
+
+int is_queue_empty(Queue* q) {
+ return q->rear == -1;
+}
+
+void enqueue(Queue* q, int value) {
+ if (q->rear == MAX_VERTICES - 1)
+ return;
+ else {
+ if (q->front == -1)
+ q->front = 0;
+ q->rear++;
+ q->items[q->rear] = value;
+ }
+}
+
+int dequeue(Queue* q) {
+ int item;
+ if (is_queue_empty(q)) {
+ return -1;
+ } else {
+ item = q->items[q->front];
+ q->front++;
+ if (q->front > q->rear) {
+ q->front = q->rear = -1;
+ }
+ return item;
+ }
+}
+
+// Stack functions
+Stack* create_stack() {
+ Stack* s = (Stack*)malloc(sizeof(Stack));
+ s->top = -1;
+ return s;
+}
+
+int is_stack_empty(Stack* s) {
+ return s->top == -1;
+}
+
+void push(Stack* s, int value) {
+ if (s->top == MAX_VERTICES - 1)
+ return;
+ else {
+ s->top++;
+ s->items[s->top] = value;
+ }
+}
+
+int pop(Stack* s) {
+ int item;
+ if (is_stack_empty(s)) {
+ return -1;
+ } else {
+ item = s->items[s->top];
+ s->top--;
+ return item;
+ }
+}
+
+// Graph functions
+Graph* create_graph() {
+ Graph* g = (Graph*)malloc(sizeof(Graph));
+ g->num_vertices = 0;
+
+ // Initialize adjacency matrix to 0
+ for (int i = 0; i < MAX_VERTICES; i++) {
+ for (int j = 0; j < MAX_VERTICES; j++) {
+ g->adjacency_matrix[i][j] = 0;
+ }
+ }
+
+ return g;
+}
+
+// Add a vertex to the graph
+int add_vertex(Graph* g, const char* vertex) {
+ if (g->num_vertices >= MAX_VERTICES) {
+ printf("Graph is full, cannot add more vertices\n");
+ return -1;
+ }
+
+ // Check if vertex already exists
+ for (int i = 0; i < g->num_vertices; i++) {
+ if (strcmp(g->vertices[i], vertex) == 0) {
+ return i;
+ }
+ }
+
+ // Add new vertex
+ strcpy(g->vertices[g->num_vertices], vertex);
+ return g->num_vertices++;
+}
+
+// Add an edge between two vertices
+void add_edge(Graph* g, const char* v1, const char* v2) {
+ // Ensure both vertices exist
+ int v1_idx = add_vertex(g, v1);
+ int v2_idx = add_vertex(g, v2);
+
+ if (v1_idx == -1 || v2_idx == -1) {
+ return;
+ }
+
+ // Add the edge (undirected graph)
+ g->adjacency_matrix[v1_idx][v2_idx] = 1;
+ g->adjacency_matrix[v2_idx][v1_idx] = 1;
+}
+
+// Print neighbors in sorted order
+void print_sorted_neighbors(Graph* g, int vertex_idx) {
+ // Create a sorted copy of neighbors
+ int neighbors[MAX_VERTICES];
+ int count = 0;
+
+ for (int i = 0; i < g->num_vertices; i++) {
+ if (g->adjacency_matrix[vertex_idx][i]) {
+ neighbors[count++] = i;
+ }
+ }
+
+ // Simple bubble sort
+ for (int i = 0; i < count - 1; i++) {
+ for (int j = 0; j < count - i - 1; j++) {
+ if (strcmp(g->vertices[neighbors[j]], g->vertices[neighbors[j + 1]]) > 0) {
+ int temp = neighbors[j];
+ neighbors[j] = neighbors[j + 1];
+ neighbors[j + 1] = temp;
+ }
+ }
+ }
+
+ printf("[");
+ for (int i = 0; i < count; i++) {
+ printf("%s", g->vertices[neighbors[i]]);
+ if (i < count - 1) {
+ printf(", ");
+ }
+ }
+ printf("]");
+}
+
+// Get the index of a vertex by name
+int get_vertex_index(Graph* g, const char* vertex) {
+ for (int i = 0; i < g->num_vertices; i++) {
+ if (strcmp(g->vertices[i], vertex) == 0) {
+ return i;
+ }
+ }
+ return -1;
+}
+
+// BFS traversal
+void bfs(Graph* g, const char* start) {
+ int start_idx = get_vertex_index(g, start);
+ if (start_idx == -1) {
+ printf("Starting vertex not found\n");
+ return;
+ }
+
+ int visited[MAX_VERTICES] = {0};
+ int result[MAX_VERTICES];
+ int result_count = 0;
+
+ Queue* q = create_queue();
+
+ // Initialize with starting vertex
+ visited[start_idx] = 1;
+ enqueue(q, start_idx);
+
+ printf("Starting BFS traversal from vertex %s\n", start);
+
+ while (!is_queue_empty(q)) {
+ // Dequeue the first vertex
+ int vertex = dequeue(q);
+ result[result_count++] = vertex;
+
+ printf("Visiting: %s\n", g->vertices[vertex]);
+
+ // Print queue contents
+ printf("Queue: [");
+ for (int i = q->front; i <= q->rear; i++) {
+ printf("%s", g->vertices[q->items[i]]);
+ if (i < q->rear) {
+ printf(", ");
+ }
+ }
+ printf("]\n");
+
+ // Print visited vertices
+ printf("Visited so far: [");
+ for (int i = 0; i < result_count; i++) {
+ printf("%s", g->vertices[result[i]]);
+ if (i < result_count - 1) {
+ printf(", ");
+ }
+ }
+ printf("]\n");
+ printf("------------------------------\n");
+
+ // Pause for demonstration
+ usleep(500000); // 500ms
+
+ // Visit neighbors in sorted order
+ int neighbors[MAX_VERTICES];
+ int count = 0;
+
+ for (int i = 0; i < g->num_vertices; i++) {
+ if (g->adjacency_matrix[vertex][i]) {
+ neighbors[count++] = i;
+ }
+ }
+
+ // Simple bubble sort
+ for (int i = 0; i < count - 1; i++) {
+ for (int j = 0; j < count - i - 1; j++) {
+ if (strcmp(g->vertices[neighbors[j]], g->vertices[neighbors[j + 1]]) > 0) {
+ int temp = neighbors[j];
+ neighbors[j] = neighbors[j + 1];
+ neighbors[j + 1] = temp;
+ }
+ }
+ }
+
+ // Enqueue all unvisited neighbors
+ for (int i = 0; i < count; i++) {
+ int neighbor = neighbors[i];
+ if (!visited[neighbor]) {
+ visited[neighbor] = 1;
+ enqueue(q, neighbor);
+ }
+ }
+ }
+
+ free(q);
+
+ // Print final result
+ printf("BFS Result: [");
+ for (int i = 0; i < result_count; i++) {
+ printf("%s", g->vertices[result[i]]);
+ if (i < result_count - 1) {
+ printf(", ");
+ }
+ }
+ printf("]\n");
+}
+
+// Helper for recursive DFS
+void dfs_helper(Graph* g, int vertex, int* visited, int* result, int* result_count) {
+ // Mark as visited and add to result
+ visited[vertex] = 1;
+ result[(*result_count)++] = vertex;
+
+ printf("Visiting: %s\n", g->vertices[vertex]);
+
+ // Print visited vertices
+ printf("Visited so far: [");
+ for (int i = 0; i < *result_count; i++) {
+ printf("%s", g->vertices[result[i]]);
+ if (i < *result_count - 1) {
+ printf(", ");
+ }
+ }
+ printf("]\n");
+ printf("------------------------------\n");
+
+ // Pause for demonstration
+ usleep(500000); // 500ms
+
+ // Visit neighbors in sorted order
+ int neighbors[MAX_VERTICES];
+ int count = 0;
+
+ for (int i = 0; i < g->num_vertices; i++) {
+ if (g->adjacency_matrix[vertex][i]) {
+ neighbors[count++] = i;
+ }
+ }
+
+ // Simple bubble sort
+ for (int i = 0; i < count - 1; i++) {
+ for (int j = 0; j < count - i - 1; j++) {
+ if (strcmp(g->vertices[neighbors[j]], g->vertices[neighbors[j + 1]]) > 0) {
+ int temp = neighbors[j];
+ neighbors[j] = neighbors[j + 1];
+ neighbors[j + 1] = temp;
+ }
+ }
+ }
+
+ // Recursively visit all unvisited neighbors
+ for (int i = 0; i < count; i++) {
+ int neighbor = neighbors[i];
+ if (!visited[neighbor]) {
+ dfs_helper(g, neighbor, visited, result, result_count);
+ }
+ }
+}
+
+// DFS traversal (recursive)
+void dfs_recursive(Graph* g, const char* start) {
+ int start_idx = get_vertex_index(g, start);
+ if (start_idx == -1) {
+ printf("Starting vertex not found\n");
+ return;
+ }
+
+ int visited[MAX_VERTICES] = {0};
+ int result[MAX_VERTICES];
+ int result_count = 0;
+
+ printf("Starting recursive DFS traversal from vertex %s\n", start);
+
+ dfs_helper(g, start_idx, visited, result, &result_count);
+
+ // Print final result
+ printf("DFS Recursive Result: [");
+ for (int i = 0; i < result_count; i++) {
+ printf("%s", g->vertices[result[i]]);
+ if (i < result_count - 1) {
+ printf(", ");
+ }
+ }
+ printf("]\n");
+}
+
+// DFS traversal (iterative)
+void dfs_iterative(Graph* g, const char* start) {
+ int start_idx = get_vertex_index(g, start);
+ if (start_idx == -1) {
+ printf("Starting vertex not found\n");
+ return;
+ }
+
+ int visited[MAX_VERTICES] = {0};
+ int result[MAX_VERTICES];
+ int result_count = 0;
+
+ Stack* s = create_stack();
+
+ // Initialize with starting vertex
+ push(s, start_idx);
+
+ printf("Starting iterative DFS traversal from vertex %s\n", start);
+
+ while (!is_stack_empty(s)) {
+ // Pop the top vertex
+ int vertex = pop(s);
+
+ // If not visited, process it
+ if (!visited[vertex]) {
+ visited[vertex] = 1;
+ result[result_count++] = vertex;
+
+ printf("Visiting: %s\n", g->vertices[vertex]);
+
+ // Print stack contents
+ printf("Stack: [");
+ for (int i = 0; i <= s->top; i++) {
+ printf("%s", g->vertices[s->items[i]]);
+ if (i < s->top) {
+ printf(", ");
+ }
+ }
+ printf("]\n");
+
+ // Print visited vertices
+ printf("Visited so far: [");
+ for (int i = 0; i < result_count; i++) {
+ printf("%s", g->vertices[result[i]]);
+ if (i < result_count - 1) {
+ printf(", ");
+ }
+ }
+ printf("]\n");
+ printf("------------------------------\n");
+
+ // Pause for demonstration
+ usleep(500000); // 500ms
+
+ // Visit neighbors in reverse sorted order for stack
+ int neighbors[MAX_VERTICES];
+ int count = 0;
+
+ for (int i = 0; i < g->num_vertices; i++) {
+ if (g->adjacency_matrix[vertex][i]) {
+ neighbors[count++] = i;
+ }
+ }
+
+ // Simple bubble sort (in reverse order)
+ for (int i = 0; i < count - 1; i++) {
+ for (int j = 0; j < count - i - 1; j++) {
+ if (strcmp(g->vertices[neighbors[j]], g->vertices[neighbors[j + 1]]) < 0) {
+ int temp = neighbors[j];
+ neighbors[j] = neighbors[j + 1];
+ neighbors[j + 1] = temp;
+ }
+ }
+ }
+
+ // Push all unvisited neighbors onto the stack
+ for (int i = 0; i < count; i++) {
+ int neighbor = neighbors[i];
+ if (!visited[neighbor]) {
+ push(s, neighbor);
+ }
+ }
+ }
+ }
+
+ free(s);
+
+ // Print final result
+ printf("DFS Iterative Result: [");
+ for (int i = 0; i < result_count; i++) {
+ printf("%s", g->vertices[result[i]]);
+ if (i < result_count - 1) {
+ printf(", ");
+ }
+ }
+ printf("]\n");
+}
+
+// Visualize the graph structure
+void visualize_graph(Graph* g) {
+ printf("\nGraph Structure:\n");
+ printf("------------------------------\n");
+
+ // Sort vertices for consistent output
+ int sorted_indices[MAX_VERTICES];
+ for (int i = 0; i < g->num_vertices; i++) {
+ sorted_indices[i] = i;
+ }
+
+ // Simple bubble sort
+ for (int i = 0; i < g->num_vertices - 1; i++) {
+ for (int j = 0; j < g->num_vertices - i - 1; j++) {
+ if (strcmp(g->vertices[sorted_indices[j]], g->vertices[sorted_indices[j + 1]]) > 0) {
+ int temp = sorted_indices[j];
+ sorted_indices[j] = sorted_indices[j + 1];
+ sorted_indices[j + 1] = temp;
+ }
+ }
+ }
+
+ for (int i = 0; i < g->num_vertices; i++) {
+ int vertex = sorted_indices[i];
+ printf("%s -> ", g->vertices[vertex]);
+ print_sorted_neighbors(g, vertex);
+ printf("\n");
+ }
+
+ printf("------------------------------\n");
+}
+
+// Create a sample graph for demonstration
+Graph* create_sample_graph() {
+ Graph* g = create_graph();
+
+ // Add edges to build this graph:
+ // A
+ // / \
+ // B C
+ // / \ \
+ // D E---F
+
+ add_edge(g, "A", "B");
+ add_edge(g, "A", "C");
+ add_edge(g, "B", "D");
+ add_edge(g, "B", "E");
+ add_edge(g, "C", "F");
+ add_edge(g, "E", "F");
+
+ return g;
+}
+
+int main() {
+ // Create a sample graph
+ Graph* g = create_sample_graph();
+ visualize_graph(g);
+
+ // Demonstrate BFS
+ printf("\n=== BFS Traversal ===\n");
+ bfs(g, "A");
+
+ // Demonstrate recursive DFS
+ printf("\n=== DFS Traversal (Recursive) ===\n");
+ dfs_recursive(g, "A");
+
+ // Demonstrate iterative DFS
+ printf("\n=== DFS Traversal (Iterative) ===\n");
+ dfs_iterative(g, "A");
+
+ free(g);
+ return 0;
+}
\ No newline at end of file
diff --git a/snippets/algorithms/graph-traversal/graph_traversal.cpp b/snippets/algorithms/graph-traversal/graph_traversal.cpp
new file mode 100644
index 0000000..a63c87d
--- /dev/null
+++ b/snippets/algorithms/graph-traversal/graph_traversal.cpp
@@ -0,0 +1,318 @@
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+
+/**
+ * Graph Traversal Algorithms in C++
+ *
+ * This program demonstrates BFS and DFS traversal algorithms on a graph.
+ *
+ * Compile: g++ -std=c++11 graph_traversal.cpp -o graph_traversal
+ * Run: ./graph_traversal
+ */
+
+class Graph {
+private:
+ // Adjacency list representation
+ std::unordered_map> adjacencyList;
+
+ // Helper function to get sorted neighbors for consistent output
+ std::vector getSortedNeighbors(const std::string& vertex) const {
+ std::vector neighbors = adjacencyList.at(vertex);
+ std::sort(neighbors.begin(), neighbors.end());
+ return neighbors;
+ }
+
+ // Helper for recursive DFS
+ void dfsHelper(const std::string& vertex, std::unordered_set& visited,
+ std::vector& result) const {
+ // Mark as visited and add to result
+ visited.insert(vertex);
+ result.push_back(vertex);
+
+ std::cout << "Visiting: " << vertex << std::endl;
+ std::cout << "Visited so far: [";
+ for (size_t i = 0; i < result.size(); ++i) {
+ std::cout << result[i];
+ if (i < result.size() - 1) std::cout << ", ";
+ }
+ std::cout << "]" << std::endl;
+ std::cout << "------------------------------" << std::endl;
+
+ // Pause for demonstration
+ std::this_thread::sleep_for(std::chrono::milliseconds(500));
+
+ // Get sorted neighbors for consistent order
+ std::vector neighbors = getSortedNeighbors(vertex);
+
+ // Recursively visit all unvisited neighbors
+ for (const auto& neighbor : neighbors) {
+ if (visited.find(neighbor) == visited.end()) {
+ dfsHelper(neighbor, visited, result);
+ }
+ }
+ }
+
+public:
+ // Add a vertex to the graph
+ void addVertex(const std::string& vertex) {
+ if (adjacencyList.find(vertex) == adjacencyList.end()) {
+ adjacencyList[vertex] = std::vector();
+ }
+ }
+
+ // Add an edge between two vertices
+ void addEdge(const std::string& v1, const std::string& v2) {
+ // Ensure both vertices exist
+ addVertex(v1);
+ addVertex(v2);
+
+ // Add the edge (undirected graph)
+ adjacencyList[v1].push_back(v2);
+ adjacencyList[v2].push_back(v1);
+ }
+
+ // Breadth-First Search traversal
+ std::vector bfs(const std::string& start) const {
+ if (adjacencyList.find(start) == adjacencyList.end()) {
+ return {};
+ }
+
+ std::unordered_set visited;
+ std::queue queue;
+ std::vector result;
+
+ // Initialize with starting vertex
+ visited.insert(start);
+ queue.push(start);
+
+ std::cout << "Starting BFS traversal from vertex " << start << std::endl;
+
+ while (!queue.empty()) {
+ // Dequeue the first vertex
+ std::string vertex = queue.front();
+ queue.pop();
+ result.push_back(vertex);
+
+ std::cout << "Visiting: " << vertex << std::endl;
+
+ // Print queue contents
+ std::cout << "Queue: [";
+ std::queue queueCopy = queue;
+ bool first = true;
+ while (!queueCopy.empty()) {
+ if (!first) std::cout << ", ";
+ std::cout << queueCopy.front();
+ queueCopy.pop();
+ first = false;
+ }
+ std::cout << "]" << std::endl;
+
+ // Print visited vertices
+ std::cout << "Visited so far: [";
+ for (size_t i = 0; i < result.size(); ++i) {
+ std::cout << result[i];
+ if (i < result.size() - 1) std::cout << ", ";
+ }
+ std::cout << "]" << std::endl;
+ std::cout << "------------------------------" << std::endl;
+
+ // Pause for demonstration
+ std::this_thread::sleep_for(std::chrono::milliseconds(500));
+
+ // Get sorted neighbors for consistent order
+ std::vector neighbors = getSortedNeighbors(vertex);
+
+ // Enqueue all unvisited neighbors
+ for (const auto& neighbor : neighbors) {
+ if (visited.find(neighbor) == visited.end()) {
+ visited.insert(neighbor);
+ queue.push(neighbor);
+ }
+ }
+ }
+
+ return result;
+ }
+
+ // Depth-First Search traversal (recursive)
+ std::vector dfsRecursive(const std::string& start) const {
+ if (adjacencyList.find(start) == adjacencyList.end()) {
+ return {};
+ }
+
+ std::unordered_set visited;
+ std::vector result;
+
+ std::cout << "Starting recursive DFS traversal from vertex " << start << std::endl;
+
+ dfsHelper(start, visited, result);
+
+ return result;
+ }
+
+ // Depth-First Search traversal (iterative)
+ std::vector dfsIterative(const std::string& start) const {
+ if (adjacencyList.find(start) == adjacencyList.end()) {
+ return {};
+ }
+
+ std::unordered_set visited;
+ std::stack stack;
+ std::vector result;
+
+ // Initialize with starting vertex
+ stack.push(start);
+
+ std::cout << "Starting iterative DFS traversal from vertex " << start << std::endl;
+
+ while (!stack.empty()) {
+ // Pop the top vertex
+ std::string vertex = stack.top();
+ stack.pop();
+
+ // If not visited, process it
+ if (visited.find(vertex) == visited.end()) {
+ visited.insert(vertex);
+ result.push_back(vertex);
+
+ std::cout << "Visiting: " << vertex << std::endl;
+
+ // Print stack contents (in reverse order since it's LIFO)
+ std::cout << "Stack: [";
+ std::vector stackContents;
+ std::stack stackCopy = stack;
+ while (!stackCopy.empty()) {
+ stackContents.push_back(stackCopy.top());
+ stackCopy.pop();
+ }
+ std::reverse(stackContents.begin(), stackContents.end());
+ for (size_t i = 0; i < stackContents.size(); ++i) {
+ std::cout << stackContents[i];
+ if (i < stackContents.size() - 1) std::cout << ", ";
+ }
+ std::cout << "]" << std::endl;
+
+ // Print visited vertices
+ std::cout << "Visited so far: [";
+ for (size_t i = 0; i < result.size(); ++i) {
+ std::cout << result[i];
+ if (i < result.size() - 1) std::cout << ", ";
+ }
+ std::cout << "]" << std::endl;
+ std::cout << "------------------------------" << std::endl;
+
+ // Pause for demonstration
+ std::this_thread::sleep_for(std::chrono::milliseconds(500));
+
+ // Get sorted neighbors in reverse order for stack
+ std::vector neighbors = getSortedNeighbors(vertex);
+ std::reverse(neighbors.begin(), neighbors.end());
+
+ // Push all unvisited neighbors onto the stack
+ for (const auto& neighbor : neighbors) {
+ if (visited.find(neighbor) == visited.end()) {
+ stack.push(neighbor);
+ }
+ }
+ }
+ }
+
+ return result;
+ }
+
+ // Print the graph structure
+ void visualizeGraph() const {
+ std::cout << "\nGraph Structure:" << std::endl;
+ std::cout << "------------------------------" << std::endl;
+
+ // Sort vertices for consistent output
+ std::vector vertices;
+ for (const auto& pair : adjacencyList) {
+ vertices.push_back(pair.first);
+ }
+ std::sort(vertices.begin(), vertices.end());
+
+ for (const auto& vertex : vertices) {
+ std::vector neighbors = getSortedNeighbors(vertex);
+
+ std::cout << vertex << " -> [";
+ for (size_t i = 0; i < neighbors.size(); ++i) {
+ std::cout << neighbors[i];
+ if (i < neighbors.size() - 1) std::cout << ", ";
+ }
+ std::cout << "]" << std::endl;
+ }
+
+ std::cout << "------------------------------" << std::endl;
+ }
+};
+
+// Create a sample graph for demonstration
+Graph createSampleGraph() {
+ Graph g;
+
+ // Add edges to build this graph:
+ // A
+ // / \
+ // B C
+ // / \ \
+ // D E---F
+
+ std::vector> edges = {
+ {"A", "B"}, {"A", "C"},
+ {"B", "D"}, {"B", "E"},
+ {"C", "F"}, {"E", "F"}
+ };
+
+ for (const auto& edge : edges) {
+ g.addEdge(edge.first, edge.second);
+ }
+
+ return g;
+}
+
+// Main function
+int main() {
+ // Create a sample graph
+ Graph g = createSampleGraph();
+ g.visualizeGraph();
+
+ // Demonstrate BFS
+ std::cout << "\n=== BFS Traversal ===" << std::endl;
+ std::vector bfsResult = g.bfs("A");
+ std::cout << "BFS Result: [";
+ for (size_t i = 0; i < bfsResult.size(); ++i) {
+ std::cout << bfsResult[i];
+ if (i < bfsResult.size() - 1) std::cout << ", ";
+ }
+ std::cout << "]" << std::endl;
+
+ // Demonstrate recursive DFS
+ std::cout << "\n=== DFS Traversal (Recursive) ===" << std::endl;
+ std::vector dfsRecResult = g.dfsRecursive("A");
+ std::cout << "DFS Recursive Result: [";
+ for (size_t i = 0; i < dfsRecResult.size(); ++i) {
+ std::cout << dfsRecResult[i];
+ if (i < dfsRecResult.size() - 1) std::cout << ", ";
+ }
+ std::cout << "]" << std::endl;
+
+ // Demonstrate iterative DFS
+ std::cout << "\n=== DFS Traversal (Iterative) ===" << std::endl;
+ std::vector dfsIterResult = g.dfsIterative("A");
+ std::cout << "DFS Iterative Result: [";
+ for (size_t i = 0; i < dfsIterResult.size(); ++i) {
+ std::cout << dfsIterResult[i];
+ if (i < dfsIterResult.size() - 1) std::cout << ", ";
+ }
+ std::cout << "]" << std::endl;
+
+ return 0;
+}
\ No newline at end of file
diff --git a/snippets/algorithms/graph-traversal/graph_traversal.go b/snippets/algorithms/graph-traversal/graph_traversal.go
new file mode 100644
index 0000000..56a5d72
--- /dev/null
+++ b/snippets/algorithms/graph-traversal/graph_traversal.go
@@ -0,0 +1,242 @@
+package main
+
+import (
+ "fmt"
+ "sort"
+ "time"
+)
+
+// Graph represents an undirected graph using an adjacency list
+type Graph struct {
+ adjacencyList map[string][]string
+}
+
+// NewGraph creates a new empty graph
+func NewGraph() *Graph {
+ return &Graph{
+ adjacencyList: make(map[string][]string),
+ }
+}
+
+// AddVertex adds a vertex to the graph
+func (g *Graph) AddVertex(vertex string) {
+ if _, exists := g.adjacencyList[vertex]; !exists {
+ g.adjacencyList[vertex] = []string{}
+ }
+}
+
+// AddEdge adds an edge between two vertices
+func (g *Graph) AddEdge(v1, v2 string) {
+ // Ensure both vertices exist
+ g.AddVertex(v1)
+ g.AddVertex(v2)
+
+ // Add the edge (for undirected graph)
+ g.adjacencyList[v1] = append(g.adjacencyList[v1], v2)
+ g.adjacencyList[v2] = append(g.adjacencyList[v2], v1)
+}
+
+// BFS performs a breadth-first search traversal starting from the given vertex
+func (g *Graph) BFS(start string) []string {
+ if _, exists := g.adjacencyList[start]; !exists {
+ return []string{}
+ }
+
+ // Initialize data structures
+ visited := make(map[string]bool)
+ visited[start] = true
+
+ queue := []string{start}
+ result := []string{}
+
+ fmt.Printf("Starting BFS traversal from vertex %s\n", start)
+
+ // BFS traversal
+ for len(queue) > 0 {
+ // Dequeue the first vertex
+ vertex := queue[0]
+ queue = queue[1:]
+ result = append(result, vertex)
+
+ fmt.Printf("Visiting: %s\n", vertex)
+ fmt.Printf("Queue: %v\n", queue)
+ fmt.Printf("Visited so far: %v\n", result)
+ fmt.Println("------------------------------")
+ time.Sleep(500 * time.Millisecond) // Slow down for demonstration
+
+ // Get sorted neighbors for consistent order
+ neighbors := g.getSortedNeighbors(vertex)
+
+ // Enqueue all unvisited neighbors
+ for _, neighbor := range neighbors {
+ if !visited[neighbor] {
+ visited[neighbor] = true
+ queue = append(queue, neighbor)
+ }
+ }
+ }
+
+ return result
+}
+
+// DFSRecursive performs a recursive depth-first search traversal starting from the given vertex
+func (g *Graph) DFSRecursive(start string) []string {
+ if _, exists := g.adjacencyList[start]; !exists {
+ return []string{}
+ }
+
+ // Initialize data structures
+ visited := make(map[string]bool)
+ result := []string{}
+
+ fmt.Printf("Starting recursive DFS traversal from vertex %s\n", start)
+
+ // Define the recursive helper function
+ var dfs func(vertex string)
+ dfs = func(vertex string) {
+ // Mark as visited and add to result
+ visited[vertex] = true
+ result = append(result, vertex)
+
+ fmt.Printf("Visiting: %s\n", vertex)
+ fmt.Printf("Visited so far: %v\n", result)
+ fmt.Println("------------------------------")
+ time.Sleep(500 * time.Millisecond) // Slow down for demonstration
+
+ // Get sorted neighbors for consistent order
+ neighbors := g.getSortedNeighbors(vertex)
+
+ // Recursively visit all unvisited neighbors
+ for _, neighbor := range neighbors {
+ if !visited[neighbor] {
+ dfs(neighbor)
+ }
+ }
+ }
+
+ // Start the DFS traversal
+ dfs(start)
+ return result
+}
+
+// DFSIterative performs an iterative depth-first search traversal starting from the given vertex
+func (g *Graph) DFSIterative(start string) []string {
+ if _, exists := g.adjacencyList[start]; !exists {
+ return []string{}
+ }
+
+ // Initialize data structures
+ visited := make(map[string]bool)
+ stack := []string{start}
+ result := []string{}
+
+ fmt.Printf("Starting iterative DFS traversal from vertex %s\n", start)
+
+ // DFS traversal using a stack
+ for len(stack) > 0 {
+ // Pop the last vertex from the stack
+ lastIndex := len(stack) - 1
+ vertex := stack[lastIndex]
+ stack = stack[:lastIndex]
+
+ // If not visited, process it
+ if !visited[vertex] {
+ visited[vertex] = true
+ result = append(result, vertex)
+
+ fmt.Printf("Visiting: %s\n", vertex)
+ fmt.Printf("Stack: %v\n", stack)
+ fmt.Printf("Visited so far: %v\n", result)
+ fmt.Println("------------------------------")
+ time.Sleep(500 * time.Millisecond) // Slow down for demonstration
+
+ // Get sorted neighbors in reverse order for stack
+ neighbors := g.getSortedNeighbors(vertex)
+ // Reverse the order for stack to simulate recursive DFS
+ for i, j := 0, len(neighbors)-1; i < j; i, j = i+1, j-1 {
+ neighbors[i], neighbors[j] = neighbors[j], neighbors[i]
+ }
+
+ // Push all unvisited neighbors onto the stack
+ for _, neighbor := range neighbors {
+ if !visited[neighbor] {
+ stack = append(stack, neighbor)
+ }
+ }
+ }
+ }
+
+ return result
+}
+
+// VisualizeGraph prints a visualization of the graph structure
+func (g *Graph) VisualizeGraph() {
+ fmt.Println("\nGraph Structure:")
+ fmt.Println("------------------------------")
+
+ // Sort vertices for consistent output
+ var vertices []string
+ for vertex := range g.adjacencyList {
+ vertices = append(vertices, vertex)
+ }
+ sort.Strings(vertices)
+
+ for _, vertex := range vertices {
+ neighbors := g.getSortedNeighbors(vertex)
+ fmt.Printf("%s -> %v\n", vertex, neighbors)
+ }
+
+ fmt.Println("------------------------------")
+}
+
+// getSortedNeighbors returns the sorted neighbors of a vertex
+func (g *Graph) getSortedNeighbors(vertex string) []string {
+ neighbors := g.adjacencyList[vertex]
+ sort.Strings(neighbors)
+ return neighbors
+}
+
+// CreateSampleGraph creates a sample graph for demonstration
+func CreateSampleGraph() *Graph {
+ g := NewGraph()
+
+ // Add edges to build this graph:
+ // A
+ // / \
+ // B C
+ // / \ \
+ // D E---F
+
+ edges := [][2]string{
+ {"A", "B"}, {"A", "C"},
+ {"B", "D"}, {"B", "E"},
+ {"C", "F"}, {"E", "F"},
+ }
+
+ for _, edge := range edges {
+ g.AddEdge(edge[0], edge[1])
+ }
+
+ return g
+}
+
+func main() {
+ // Create a sample graph
+ g := CreateSampleGraph()
+ g.VisualizeGraph()
+
+ // Demonstrate BFS
+ fmt.Println("\n=== BFS Traversal ===")
+ bfsResult := g.BFS("A")
+ fmt.Printf("BFS Result: %v\n", bfsResult)
+
+ // Demonstrate recursive DFS
+ fmt.Println("\n=== DFS Traversal (Recursive) ===")
+ dfsRecResult := g.DFSRecursive("A")
+ fmt.Printf("DFS Recursive Result: %v\n", dfsRecResult)
+
+ // Demonstrate iterative DFS
+ fmt.Println("\n=== DFS Traversal (Iterative) ===")
+ dfsIterResult := g.DFSIterative("A")
+ fmt.Printf("DFS Iterative Result: %v\n", dfsIterResult)
+}
\ No newline at end of file
diff --git a/snippets/algorithms/graph-traversal/graph_traversal.php b/snippets/algorithms/graph-traversal/graph_traversal.php
new file mode 100644
index 0000000..17175b2
--- /dev/null
+++ b/snippets/algorithms/graph-traversal/graph_traversal.php
@@ -0,0 +1,268 @@
+adjacencyList[$vertex])) {
+ $this->adjacencyList[$vertex] = [];
+ }
+ }
+
+ /**
+ * Adds an edge between two vertices
+ *
+ * @param string $v1 First vertex
+ * @param string $v2 Second vertex
+ */
+ public function addEdge($v1, $v2) {
+ // Ensure both vertices exist
+ $this->addVertex($v1);
+ $this->addVertex($v2);
+
+ // Add the edge (undirected graph)
+ $this->adjacencyList[$v1][] = $v2;
+ $this->adjacencyList[$v2][] = $v1;
+ }
+
+ /**
+ * Helper method to get sorted neighbors for consistent output
+ *
+ * @param string $vertex The vertex to get neighbors for
+ * @return array Sorted array of neighbors
+ */
+ private function getSortedNeighbors($vertex) {
+ $neighbors = $this->adjacencyList[$vertex];
+ sort($neighbors);
+ return $neighbors;
+ }
+
+ /**
+ * Performs a breadth-first search traversal starting from the given vertex
+ *
+ * @param string $start Starting vertex
+ * @return array Array of vertices in the order they were visited
+ */
+ public function bfs($start) {
+ if (!isset($this->adjacencyList[$start])) {
+ return [];
+ }
+
+ $visited = [$start => true];
+ $queue = [$start];
+ $result = [];
+
+ echo "Starting BFS traversal from vertex $start\n";
+
+ while (count($queue) > 0) {
+ // Dequeue the first vertex
+ $vertex = array_shift($queue);
+ $result[] = $vertex;
+
+ echo "Visiting: $vertex\n";
+ echo "Queue: [" . implode(", ", $queue) . "]\n";
+ echo "Visited so far: [" . implode(", ", $result) . "]\n";
+ echo "------------------------------\n";
+
+ // Pause for demonstration
+ usleep(500000); // 500ms
+
+ // Get sorted neighbors for consistent order
+ $neighbors = $this->getSortedNeighbors($vertex);
+
+ // Enqueue all unvisited neighbors
+ foreach ($neighbors as $neighbor) {
+ if (!isset($visited[$neighbor])) {
+ $visited[$neighbor] = true;
+ $queue[] = $neighbor;
+ }
+ }
+ }
+
+ return $result;
+ }
+
+ /**
+ * Performs a recursive depth-first search traversal starting from the given vertex
+ *
+ * @param string $start Starting vertex
+ * @return array Array of vertices in the order they were visited
+ */
+ public function dfsRecursive($start) {
+ if (!isset($this->adjacencyList[$start])) {
+ return [];
+ }
+
+ $visited = [];
+ $result = [];
+
+ echo "Starting recursive DFS traversal from vertex $start\n";
+
+ $this->dfsHelper($start, $visited, $result);
+
+ return $result;
+ }
+
+ /**
+ * Helper method for recursive DFS
+ *
+ * @param string $vertex Current vertex
+ * @param array &$visited Reference to array of visited vertices
+ * @param array &$result Reference to array to store the traversal result
+ */
+ private function dfsHelper($vertex, &$visited, &$result) {
+ // Mark as visited and add to result
+ $visited[$vertex] = true;
+ $result[] = $vertex;
+
+ echo "Visiting: $vertex\n";
+ echo "Visited so far: [" . implode(", ", $result) . "]\n";
+ echo "------------------------------\n";
+
+ // Pause for demonstration
+ usleep(500000); // 500ms
+
+ // Get sorted neighbors for consistent order
+ $neighbors = $this->getSortedNeighbors($vertex);
+
+ // Recursively visit all unvisited neighbors
+ foreach ($neighbors as $neighbor) {
+ if (!isset($visited[$neighbor])) {
+ $this->dfsHelper($neighbor, $visited, $result);
+ }
+ }
+ }
+
+ /**
+ * Performs an iterative depth-first search traversal starting from the given vertex
+ *
+ * @param string $start Starting vertex
+ * @return array Array of vertices in the order they were visited
+ */
+ public function dfsIterative($start) {
+ if (!isset($this->adjacencyList[$start])) {
+ return [];
+ }
+
+ $visited = [];
+ $stack = [$start];
+ $result = [];
+
+ echo "Starting iterative DFS traversal from vertex $start\n";
+
+ while (count($stack) > 0) {
+ // Pop the top vertex
+ $vertex = array_pop($stack);
+
+ // If not visited, process it
+ if (!isset($visited[$vertex])) {
+ $visited[$vertex] = true;
+ $result[] = $vertex;
+
+ echo "Visiting: $vertex\n";
+ echo "Stack: [" . implode(", ", $stack) . "]\n";
+ echo "Visited so far: [" . implode(", ", $result) . "]\n";
+ echo "------------------------------\n";
+
+ // Pause for demonstration
+ usleep(500000); // 500ms
+
+ // Get sorted neighbors in reverse order for stack
+ $neighbors = $this->getSortedNeighbors($vertex);
+ $neighbors = array_reverse($neighbors);
+
+ // Push all unvisited neighbors onto the stack
+ foreach ($neighbors as $neighbor) {
+ if (!isset($visited[$neighbor])) {
+ $stack[] = $neighbor;
+ }
+ }
+ }
+ }
+
+ return $result;
+ }
+
+ /**
+ * Prints a visualization of the graph structure
+ */
+ public function visualizeGraph() {
+ echo "\nGraph Structure:\n";
+ echo "------------------------------\n";
+
+ // Sort vertices for consistent output
+ $vertices = array_keys($this->adjacencyList);
+ sort($vertices);
+
+ foreach ($vertices as $vertex) {
+ $neighbors = $this->getSortedNeighbors($vertex);
+ echo "$vertex -> [" . implode(", ", $neighbors) . "]\n";
+ }
+
+ echo "------------------------------\n";
+ }
+}
+
+/**
+ * Creates a sample graph for demonstration
+ *
+ * @return Graph A sample graph
+ */
+function createSampleGraph() {
+ $g = new Graph();
+
+ // Add edges to build this graph:
+ // A
+ // / \
+ // B C
+ // / \ \
+ // D E---F
+
+ $edges = [
+ ["A", "B"], ["A", "C"],
+ ["B", "D"], ["B", "E"],
+ ["C", "F"], ["E", "F"]
+ ];
+
+ foreach ($edges as $edge) {
+ $g->addEdge($edge[0], $edge[1]);
+ }
+
+ return $g;
+}
+
+// Main execution
+$g = createSampleGraph();
+$g->visualizeGraph();
+
+// Demonstrate BFS
+echo "\n=== BFS Traversal ===\n";
+$bfsResult = $g->bfs("A");
+echo "BFS Result: [" . implode(", ", $bfsResult) . "]\n";
+
+// Demonstrate recursive DFS
+echo "\n=== DFS Traversal (Recursive) ===\n";
+$dfsRecResult = $g->dfsRecursive("A");
+echo "DFS Recursive Result: [" . implode(", ", $dfsRecResult) . "]\n";
+
+// Demonstrate iterative DFS
+echo "\n=== DFS Traversal (Iterative) ===\n";
+$dfsIterResult = $g->dfsIterative("A");
+echo "DFS Iterative Result: [" . implode(", ", $dfsIterResult) . "]\n";
+?>
\ No newline at end of file
diff --git a/snippets/algorithms/graph-traversal/graph_traversal.py b/snippets/algorithms/graph-traversal/graph_traversal.py
new file mode 100644
index 0000000..364ec40
--- /dev/null
+++ b/snippets/algorithms/graph-traversal/graph_traversal.py
@@ -0,0 +1,198 @@
+#!/usr/bin/env python3
+"""
+Graph Traversal Algorithms Implementation
+
+This module provides implementations of BFS and DFS for graph traversal,
+along with a visualization function to display the traversal order.
+
+Example usage:
+ python graph_traversal_example.py
+"""
+
+from collections import deque
+import time
+
+
+class Graph:
+ """A simple graph representation using adjacency lists."""
+
+ def __init__(self):
+ """Initialize an empty graph."""
+ self.graph = {}
+
+ def add_vertex(self, vertex):
+ """Add a vertex to the graph if it doesn't exist."""
+ if vertex not in self.graph:
+ self.graph[vertex] = []
+
+ def add_edge(self, v1, v2):
+ """Add an edge between v1 and v2."""
+ if v1 not in self.graph:
+ self.add_vertex(v1)
+ if v2 not in self.graph:
+ self.add_vertex(v2)
+
+ self.graph[v1].append(v2)
+ self.graph[v2].append(v1) # For undirected graph
+
+ def bfs(self, start):
+ """
+ Perform Breadth-First Search starting from the given vertex.
+
+ Args:
+ start: The starting vertex for BFS
+
+ Returns:
+ A list containing vertices in the order they were visited
+ """
+ if start not in self.graph:
+ return []
+
+ visited = set([start])
+ queue = deque([start])
+ result = []
+
+ print(f"Starting BFS traversal from vertex {start}")
+
+ while queue:
+ vertex = queue.popleft()
+ result.append(vertex)
+
+ print(f"Visiting: {vertex}")
+ print(f"Queue: {list(queue)}")
+ print(f"Visited so far: {result}")
+ print("-" * 30)
+ time.sleep(0.5) # Slow down for demonstration
+
+ for neighbor in sorted(self.graph[vertex]): # Sort for consistent order
+ if neighbor not in visited:
+ visited.add(neighbor)
+ queue.append(neighbor)
+
+ return result
+
+ def dfs_recursive(self, start):
+ """
+ Perform Depth-First Search recursively starting from the given vertex.
+
+ Args:
+ start: The starting vertex for DFS
+
+ Returns:
+ A list containing vertices in the order they were visited
+ """
+ if start not in self.graph:
+ return []
+
+ visited = set()
+ result = []
+
+ print(f"Starting recursive DFS traversal from vertex {start}")
+
+ def dfs_helper(vertex):
+ visited.add(vertex)
+ result.append(vertex)
+
+ print(f"Visiting: {vertex}")
+ print(f"Visited so far: {result}")
+ print("-" * 30)
+ time.sleep(0.5) # Slow down for demonstration
+
+ for neighbor in sorted(self.graph[vertex]): # Sort for consistent order
+ if neighbor not in visited:
+ dfs_helper(neighbor)
+
+ dfs_helper(start)
+ return result
+
+ def dfs_iterative(self, start):
+ """
+ Perform Depth-First Search iteratively starting from the given vertex.
+
+ Args:
+ start: The starting vertex for DFS
+
+ Returns:
+ A list containing vertices in the order they were visited
+ """
+ if start not in self.graph:
+ return []
+
+ visited = set()
+ stack = [start]
+ result = []
+
+ print(f"Starting iterative DFS traversal from vertex {start}")
+
+ while stack:
+ vertex = stack.pop()
+
+ if vertex not in visited:
+ visited.add(vertex)
+ result.append(vertex)
+
+ print(f"Visiting: {vertex}")
+ print(f"Stack: {stack}")
+ print(f"Visited so far: {result}")
+ print("-" * 30)
+ time.sleep(0.5) # Slow down for demonstration
+
+ # Add neighbors in reverse sorted order to simulate recursive DFS
+ for neighbor in sorted(self.graph[vertex], reverse=True):
+ if neighbor not in visited:
+ stack.append(neighbor)
+
+ return result
+
+ def visualize_graph(self):
+ """Print a simple visualization of the graph structure."""
+ print("\nGraph Structure:")
+ print("-" * 30)
+ for vertex, neighbors in sorted(self.graph.items()):
+ print(f"{vertex} -> {sorted(neighbors)}")
+ print("-" * 30)
+
+
+def create_sample_graph():
+ """Create a sample graph for demonstration."""
+ g = Graph()
+
+ # Add edges to build this graph:
+ # A
+ # / \
+ # B C
+ # / \ \
+ # D E---F
+
+ edges = [
+ ('A', 'B'), ('A', 'C'),
+ ('B', 'D'), ('B', 'E'),
+ ('C', 'F'), ('E', 'F')
+ ]
+
+ for v1, v2 in edges:
+ g.add_edge(v1, v2)
+
+ return g
+
+
+def main():
+ """Main function to demonstrate graph traversal algorithms."""
+ g = create_sample_graph()
+ g.visualize_graph()
+
+ print("\n=== BFS Traversal ===")
+ bfs_result = g.bfs('A')
+ print(f"BFS Result: {bfs_result}")
+
+ print("\n=== DFS Traversal (Recursive) ===")
+ dfs_rec_result = g.dfs_recursive('A')
+ print(f"DFS Recursive Result: {dfs_rec_result}")
+
+ print("\n=== DFS Traversal (Iterative) ===")
+ dfs_iter_result = g.dfs_iterative('A')
+ print(f"DFS Iterative Result: {dfs_iter_result}")
+
+
+if __name__ == "__main__":
+ main()
\ No newline at end of file
diff --git a/snippets/algorithms/graph-traversal/graph_traversal.rb b/snippets/algorithms/graph-traversal/graph_traversal.rb
new file mode 100644
index 0000000..f5ba55f
--- /dev/null
+++ b/snippets/algorithms/graph-traversal/graph_traversal.rb
@@ -0,0 +1,208 @@
+#!/usr/bin/env ruby
+
+# Graph Traversal Algorithms in Ruby
+#
+# This script demonstrates BFS and DFS traversal algorithms on a graph.
+#
+# Run: ruby graph_traversal.rb
+
+class Graph
+ # Initialize an empty graph
+ def initialize
+ @adjacency_list = {}
+ end
+
+ # Add a vertex to the graph
+ def add_vertex(vertex)
+ @adjacency_list[vertex] = [] unless @adjacency_list.key?(vertex)
+ end
+
+ # Add an edge between two vertices
+ def add_edge(v1, v2)
+ # Ensure both vertices exist
+ add_vertex(v1)
+ add_vertex(v2)
+
+ # Add the edge (undirected graph)
+ @adjacency_list[v1] << v2
+ @adjacency_list[v2] << v1
+ end
+
+ # Get sorted neighbors for consistent output
+ def get_sorted_neighbors(vertex)
+ @adjacency_list[vertex].sort
+ end
+
+ # Breadth-First Search traversal
+ def bfs(start)
+ return [] unless @adjacency_list.key?(start)
+
+ visited = { start => true }
+ queue = [start]
+ result = []
+
+ puts "Starting BFS traversal from vertex #{start}"
+
+ until queue.empty?
+ # Dequeue the first vertex
+ vertex = queue.shift
+ result << vertex
+
+ puts "Visiting: #{vertex}"
+ puts "Queue: #{queue.inspect}"
+ puts "Visited so far: #{result.inspect}"
+ puts "------------------------------"
+
+ # Pause for demonstration
+ sleep(0.5) # 500ms
+
+ # Get sorted neighbors for consistent order
+ neighbors = get_sorted_neighbors(vertex)
+
+ # Enqueue all unvisited neighbors
+ neighbors.each do |neighbor|
+ unless visited[neighbor]
+ visited[neighbor] = true
+ queue << neighbor
+ end
+ end
+ end
+
+ result
+ end
+
+ # Depth-First Search traversal (recursive)
+ def dfs_recursive(start)
+ return [] unless @adjacency_list.key?(start)
+
+ visited = {}
+ result = []
+
+ puts "Starting recursive DFS traversal from vertex #{start}"
+
+ dfs_helper(start, visited, result)
+
+ result
+ end
+
+ # Helper method for recursive DFS
+ def dfs_helper(vertex, visited, result)
+ # Mark as visited and add to result
+ visited[vertex] = true
+ result << vertex
+
+ puts "Visiting: #{vertex}"
+ puts "Visited so far: #{result.inspect}"
+ puts "------------------------------"
+
+ # Pause for demonstration
+ sleep(0.5) # 500ms
+
+ # Get sorted neighbors for consistent order
+ neighbors = get_sorted_neighbors(vertex)
+
+ # Recursively visit all unvisited neighbors
+ neighbors.each do |neighbor|
+ dfs_helper(neighbor, visited, result) unless visited[neighbor]
+ end
+ end
+
+ # Depth-First Search traversal (iterative)
+ def dfs_iterative(start)
+ return [] unless @adjacency_list.key?(start)
+
+ visited = {}
+ stack = [start]
+ result = []
+
+ puts "Starting iterative DFS traversal from vertex #{start}"
+
+ until stack.empty?
+ # Pop the top vertex
+ vertex = stack.pop
+
+ # If not visited, process it
+ unless visited[vertex]
+ visited[vertex] = true
+ result << vertex
+
+ puts "Visiting: #{vertex}"
+ puts "Stack: #{stack.inspect}"
+ puts "Visited so far: #{result.inspect}"
+ puts "------------------------------"
+
+ # Pause for demonstration
+ sleep(0.5) # 500ms
+
+ # Get sorted neighbors in reverse order for stack
+ neighbors = get_sorted_neighbors(vertex).reverse
+
+ # Push all unvisited neighbors onto the stack
+ neighbors.each do |neighbor|
+ stack << neighbor unless visited[neighbor]
+ end
+ end
+ end
+
+ result
+ end
+
+ # Print the graph structure
+ def visualize_graph
+ puts "\nGraph Structure:"
+ puts "------------------------------"
+
+ # Sort vertices for consistent output
+ vertices = @adjacency_list.keys.sort
+
+ vertices.each do |vertex|
+ neighbors = get_sorted_neighbors(vertex)
+ puts "#{vertex} -> #{neighbors.inspect}"
+ end
+
+ puts "------------------------------"
+ end
+end
+
+# Create a sample graph for demonstration
+def create_sample_graph
+ g = Graph.new
+
+ # Add edges to build this graph:
+ # A
+ # / \
+ # B C
+ # / \ \
+ # D E---F
+
+ edges = [
+ ["A", "B"], ["A", "C"],
+ ["B", "D"], ["B", "E"],
+ ["C", "F"], ["E", "F"]
+ ]
+
+ edges.each do |v1, v2|
+ g.add_edge(v1, v2)
+ end
+
+ g
+end
+
+# Main execution
+g = create_sample_graph
+g.visualize_graph
+
+# Demonstrate BFS
+puts "\n=== BFS Traversal ==="
+bfs_result = g.bfs("A")
+puts "BFS Result: #{bfs_result.inspect}"
+
+# Demonstrate recursive DFS
+puts "\n=== DFS Traversal (Recursive) ==="
+dfs_rec_result = g.dfs_recursive("A")
+puts "DFS Recursive Result: #{dfs_rec_result.inspect}"
+
+# Demonstrate iterative DFS
+puts "\n=== DFS Traversal (Iterative) ==="
+dfs_iter_result = g.dfs_iterative("A")
+puts "DFS Iterative Result: #{dfs_iter_result.inspect}"
\ No newline at end of file
diff --git a/snippets/algorithms/graph-traversal/graph_traversal.rs b/snippets/algorithms/graph-traversal/graph_traversal.rs
new file mode 100644
index 0000000..d031df9
--- /dev/null
+++ b/snippets/algorithms/graph-traversal/graph_traversal.rs
@@ -0,0 +1,242 @@
+use std::collections::{HashMap, HashSet, VecDeque};
+use std::thread;
+use std::time::Duration;
+
+/// Graph Traversal Algorithms in Rust
+///
+/// This program demonstrates BFS and DFS traversal algorithms on a graph.
+///
+/// Compile: rustc graph_traversal.rs
+/// Run: ./graph_traversal
+
+/// A graph using adjacency list representation
+struct Graph {
+ // Adjacency list representation
+ adjacency_list: HashMap>,
+}
+
+impl Graph {
+ /// Creates a new empty graph
+ fn new() -> Self {
+ Graph {
+ adjacency_list: HashMap::new(),
+ }
+ }
+
+ /// Adds a vertex to the graph
+ fn add_vertex(&mut self, vertex: &str) {
+ self.adjacency_list.entry(vertex.to_string()).or_insert(Vec::new());
+ }
+
+ /// Adds an edge between two vertices
+ fn add_edge(&mut self, v1: &str, v2: &str) {
+ // Ensure both vertices exist
+ self.add_vertex(v1);
+ self.add_vertex(v2);
+
+ // Add the edge (undirected graph)
+ self.adjacency_list.get_mut(v1).unwrap().push(v2.to_string());
+ self.adjacency_list.get_mut(v2).unwrap().push(v1.to_string());
+ }
+
+ /// Helper method to get sorted neighbors for consistent output
+ fn get_sorted_neighbors(&self, vertex: &str) -> Vec {
+ let mut neighbors = self.adjacency_list[vertex].clone();
+ neighbors.sort();
+ neighbors
+ }
+
+ /// Performs a breadth-first search traversal starting from the given vertex
+ fn bfs(&self, start: &str) -> Vec {
+ if !self.adjacency_list.contains_key(start) {
+ return Vec::new();
+ }
+
+ let mut visited = HashSet::new();
+ let mut queue = VecDeque::new();
+ let mut result = Vec::new();
+
+ // Initialize with starting vertex
+ visited.insert(start.to_string());
+ queue.push_back(start.to_string());
+
+ println!("Starting BFS traversal from vertex {}", start);
+
+ while !queue.is_empty() {
+ // Dequeue the first vertex
+ let vertex = queue.pop_front().unwrap();
+ result.push(vertex.clone());
+
+ println!("Visiting: {}", vertex);
+ println!("Queue: {:?}", queue);
+ println!("Visited so far: {:?}", result);
+ println!("------------------------------");
+
+ // Pause for demonstration
+ thread::sleep(Duration::from_millis(500));
+
+ // Get sorted neighbors for consistent order
+ let neighbors = self.get_sorted_neighbors(&vertex);
+
+ // Enqueue all unvisited neighbors
+ for neighbor in neighbors {
+ if !visited.contains(&neighbor) {
+ visited.insert(neighbor.clone());
+ queue.push_back(neighbor);
+ }
+ }
+ }
+
+ result
+ }
+
+ /// Performs a recursive depth-first search traversal starting from the given vertex
+ fn dfs_recursive(&self, start: &str) -> Vec {
+ if !self.adjacency_list.contains_key(start) {
+ return Vec::new();
+ }
+
+ let mut visited = HashSet::new();
+ let mut result = Vec::new();
+
+ println!("Starting recursive DFS traversal from vertex {}", start);
+
+ self.dfs_helper(start, &mut visited, &mut result);
+
+ result
+ }
+
+ /// Helper method for recursive DFS
+ fn dfs_helper(&self, vertex: &str, visited: &mut HashSet, result: &mut Vec) {
+ // Mark as visited and add to result
+ visited.insert(vertex.to_string());
+ result.push(vertex.to_string());
+
+ println!("Visiting: {}", vertex);
+ println!("Visited so far: {:?}", result);
+ println!("------------------------------");
+
+ // Pause for demonstration
+ thread::sleep(Duration::from_millis(500));
+
+ // Get sorted neighbors for consistent order
+ let neighbors = self.get_sorted_neighbors(vertex);
+
+ // Recursively visit all unvisited neighbors
+ for neighbor in neighbors {
+ if !visited.contains(&neighbor) {
+ self.dfs_helper(&neighbor, visited, result);
+ }
+ }
+ }
+
+ /// Performs an iterative depth-first search traversal starting from the given vertex
+ fn dfs_iterative(&self, start: &str) -> Vec {
+ if !self.adjacency_list.contains_key(start) {
+ return Vec::new();
+ }
+
+ let mut visited = HashSet::new();
+ let mut stack = Vec::new();
+ let mut result = Vec::new();
+
+ // Initialize with starting vertex
+ stack.push(start.to_string());
+
+ println!("Starting iterative DFS traversal from vertex {}", start);
+
+ while !stack.is_empty() {
+ // Pop the top vertex
+ let vertex = stack.pop().unwrap();
+
+ // If not visited, process it
+ if !visited.contains(&vertex) {
+ visited.insert(vertex.clone());
+ result.push(vertex.clone());
+
+ println!("Visiting: {}", vertex);
+ println!("Stack: {:?}", stack);
+ println!("Visited so far: {:?}", result);
+ println!("------------------------------");
+
+ // Pause for demonstration
+ thread::sleep(Duration::from_millis(500));
+
+ // Get sorted neighbors in reverse order for stack
+ let mut neighbors = self.get_sorted_neighbors(&vertex);
+ neighbors.reverse();
+
+ // Push all unvisited neighbors onto the stack
+ for neighbor in neighbors {
+ if !visited.contains(&neighbor) {
+ stack.push(neighbor);
+ }
+ }
+ }
+ }
+
+ result
+ }
+
+ /// Prints a visualization of the graph structure
+ fn visualize_graph(&self) {
+ println!("\nGraph Structure:");
+ println!("------------------------------");
+
+ // Sort vertices for consistent output
+ let mut vertices: Vec = self.adjacency_list.keys().cloned().collect();
+ vertices.sort();
+
+ for vertex in vertices {
+ let neighbors = self.get_sorted_neighbors(&vertex);
+ println!("{} -> {:?}", vertex, neighbors);
+ }
+
+ println!("------------------------------");
+ }
+}
+
+/// Creates a sample graph for demonstration
+fn create_sample_graph() -> Graph {
+ let mut g = Graph::new();
+
+ // Add edges to build this graph:
+ // A
+ // / \
+ // B C
+ // / \ \
+ // D E---F
+
+ let edges = [
+ ("A", "B"), ("A", "C"),
+ ("B", "D"), ("B", "E"),
+ ("C", "F"), ("E", "F")
+ ];
+
+ for (v1, v2) in edges.iter() {
+ g.add_edge(v1, v2);
+ }
+
+ g
+}
+
+fn main() {
+ // Create a sample graph
+ let g = create_sample_graph();
+ g.visualize_graph();
+
+ // Demonstrate BFS
+ println!("\n=== BFS Traversal ===");
+ let bfs_result = g.bfs("A");
+ println!("BFS Result: {:?}", bfs_result);
+
+ // Demonstrate recursive DFS
+ println!("\n=== DFS Traversal (Recursive) ===");
+ let dfs_rec_result = g.dfs_recursive("A");
+ println!("DFS Recursive Result: {:?}", dfs_rec_result);
+
+ // Demonstrate iterative DFS
+ println!("\n=== DFS Traversal (Iterative) ===");
+ let dfs_iter_result = g.dfs_iterative("A");
+ println!("DFS Iterative Result: {:?}", dfs_iter_result);
+}
\ No newline at end of file
diff --git a/snippets/algorithms/init.txt b/snippets/algorithms/init.txt
new file mode 100644
index 0000000..e69de29
diff --git a/snippets/databases/.env.example b/snippets/databases/.env.example
new file mode 100644
index 0000000..46b59e9
--- /dev/null
+++ b/snippets/databases/.env.example
@@ -0,0 +1,32 @@
+# Database configuration example file
+# Copy this file to .env and fill in your actual values
+
+# SQLite Configuration
+SQLITE_DB_PATH=:memory:
+
+# PostgreSQL Configuration
+PG_HOST=localhost
+PG_DATABASE=mydb
+PG_USER=postgres
+PG_PASSWORD=your_secure_password
+
+# MySQL Configuration
+MYSQL_HOST=localhost
+MYSQL_DATABASE=mydb
+MYSQL_USER=root
+MYSQL_PASSWORD=your_secure_password
+
+# SQL Server Configuration
+SQLSERVER_CONNECTION_STRING=Server=localhost;Database=TestDB;User Id=sa;Password=your_secure_password;
+
+# Other database connection strings
+POSTGRES_CONNECTION_STRING=Host=localhost;Database=testdb;Username=postgres;Password=your_secure_password;
+MYSQL_CONNECTION_STRING=Server=localhost;Database=testdb;Uid=root;Pwd=your_secure_password;
+DAPPER_CONNECTION_STRING=Data Source=:memory:
+
+# SQLAlchemy URL for Python ORM
+# Format examples:
+# SQLite: sqlite:///path/to/database.db
+# PostgreSQL: postgresql://user:password@localhost/dbname
+# MySQL: mysql://user:password@localhost/dbname
+SQLALCHEMY_DATABASE_URL=sqlite:///:memory:
\ No newline at end of file
diff --git a/snippets/databases/README.md b/snippets/databases/README.md
new file mode 100644
index 0000000..fb0aeed
--- /dev/null
+++ b/snippets/databases/README.md
@@ -0,0 +1,186 @@
+# Database Code Examples
+
+This directory contains code examples for working with various relational databases in different programming languages.
+
+## Contents
+
+- `sql_examples.py` - Python examples for SQLite, PostgreSQL, MySQL, and SQLAlchemy ORM
+- `relational_db_examples.cs` - C# examples for SQLite, SQL Server, MySQL, PostgreSQL, and Dapper ORM
+
+## Setup Instructions
+
+### Environment Variables
+
+For security reasons, all database connection credentials are loaded from environment variables. Follow these steps to set up your environment:
+
+1. Copy the example environment file to create your own `.env` file:
+ ```bash
+ cp envv.example .env
+ ```
+
+2. Edit the `.env` file with your actual database credentials:
+ ```
+ # Example for PostgreSQL
+ PG_HOST=localhost
+ PG_DATABASE=yourdb
+ PG_USER=yourusername
+ PG_PASSWORD=yourpassword
+ ```
+
+3. Make sure your `.env` file is included in `.gitignore` to prevent committing sensitive information.
+
+### Python Setup
+
+To run the Python examples:
+
+1. Install required dependencies:
+ ```bash
+ pip install python-dotenv
+
+ # For SQLite (built into Python)
+ # No additional installation needed
+
+ # For PostgreSQL
+ pip install psycopg2-binary
+
+ # For MySQL
+ pip install mysql-connector-python
+
+ # For SQLAlchemy ORM
+ pip install sqlalchemy
+ ```
+
+2. Run the examples:
+ ```bash
+ python sql_examples.py
+ ```
+
+### C# Setup
+
+To run the C# examples:
+
+1. Install required NuGet packages:
+ ```bash
+ # For SQLite
+ dotnet add package Microsoft.Data.Sqlite
+
+ # For SQL Server
+ dotnet add package Microsoft.Data.SqlClient
+
+ # For MySQL
+ dotnet add package MySql.Data
+
+ # For PostgreSQL
+ dotnet add package Npgsql
+
+ # For Dapper ORM
+ dotnet add package Dapper
+ ```
+
+2. Build and run the examples:
+ ```bash
+ dotnet build
+ dotnet run
+ ```
+
+## Usage Examples
+
+### Python SQLite Example
+
+```python
+import sqlite3
+from dotenv import load_dotenv
+import os
+
+# Load environment variables
+load_dotenv()
+
+# Get database path from environment variable
+db_path = os.environ.get("SQLITE_DB_PATH", ":memory:")
+
+# Connect to SQLite database
+conn = sqlite3.connect(db_path)
+cursor = conn.cursor()
+
+# Create a table
+cursor.execute('''
+CREATE TABLE IF NOT EXISTS users (
+ id INTEGER PRIMARY KEY,
+ name TEXT NOT NULL,
+ email TEXT UNIQUE NOT NULL
+)
+''')
+
+# Insert data
+cursor.execute('INSERT INTO users (name, email) VALUES (?, ?)',
+ ('John Doe', 'john@example.com'))
+conn.commit()
+
+# Query data
+cursor.execute('SELECT * FROM users')
+print(cursor.fetchall())
+
+# Close connection
+conn.close()
+```
+
+### C# SQLite Example
+
+```csharp
+using System;
+using Microsoft.Data.Sqlite;
+
+// Get connection string from environment variable
+string connectionString = Environment.GetEnvironmentVariable("SQLITE_CONNECTION_STRING")
+ ?? "Data Source=:memory:";
+
+using (var connection = new SqliteConnection(connectionString))
+{
+ connection.Open();
+
+ // Create a table
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ CREATE TABLE IF NOT EXISTS users (
+ id INTEGER PRIMARY KEY,
+ name TEXT NOT NULL,
+ email TEXT NOT NULL UNIQUE
+ )";
+ command.ExecuteNonQuery();
+ }
+
+ // Insert data
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ INSERT INTO users (name, email)
+ VALUES (@name, @email)";
+ command.Parameters.AddWithValue("@name", "Jane Smith");
+ command.Parameters.AddWithValue("@email", "jane@example.com");
+ command.ExecuteNonQuery();
+ }
+
+ // Query data
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = "SELECT * FROM users";
+ using (var reader = command.ExecuteReader())
+ {
+ while (reader.Read())
+ {
+ Console.WriteLine($"ID: {reader.GetInt32(0)}, Name: {reader.GetString(1)}, Email: {reader.GetString(2)}");
+ }
+ }
+ }
+}
+```
+
+## Security Best Practices
+
+1. Never hardcode database credentials in your source code
+2. Always use parameterized queries to prevent SQL injection
+3. Store connection strings and credentials in environment variables or a secure configuration system
+4. Use the principle of least privilege for database users
+5. Encrypt sensitive data before storing it in the database
+6. Regularly update database drivers and libraries to patch security vulnerabilities
\ No newline at end of file
diff --git a/snippets/databases/README_vi.md b/snippets/databases/README_vi.md
new file mode 100644
index 0000000..0ea5b09
--- /dev/null
+++ b/snippets/databases/README_vi.md
@@ -0,0 +1,186 @@
+# Ví Dụ Mã Nguồn Cơ Sở Dữ Liệu
+
+Thư mục này chứa các ví dụ mã nguồn để làm việc với nhiều cơ sở dữ liệu quan hệ khác nhau trong các ngôn ngữ lập trình khác nhau.
+
+## Nội Dung
+
+- `sql_examples.py` - Ví dụ Python cho SQLite, PostgreSQL, MySQL, và SQLAlchemy ORM
+- `relational_db_examples.cs` - Ví dụ C# cho SQLite, SQL Server, MySQL, PostgreSQL, và Dapper ORM
+
+## Hướng Dẫn Cài Đặt
+
+### Biến Môi Trường
+
+Vì lý do bảo mật, tất cả thông tin đăng nhập cơ sở dữ liệu được tải từ biến môi trường. Làm theo các bước sau để thiết lập môi trường của bạn:
+
+1. Sao chép tệp môi trường mẫu để tạo tệp `.env` của riêng bạn:
+ ```bash
+ cp envv.example .env
+ ```
+
+2. Chỉnh sửa tệp `.env` với thông tin đăng nhập cơ sở dữ liệu thực tế của bạn:
+ ```
+ # Ví dụ cho PostgreSQL
+ PG_HOST=localhost
+ PG_DATABASE=yourdb
+ PG_USER=yourusername
+ PG_PASSWORD=yourpassword
+ ```
+
+3. Đảm bảo tệp `.env` của bạn được bao gồm trong `.gitignore` để tránh commit thông tin nhạy cảm.
+
+### Cài Đặt Python
+
+Để chạy các ví dụ Python:
+
+1. Cài đặt các gói phụ thuộc cần thiết:
+ ```bash
+ pip install python-dotenv
+
+ # Cho SQLite (đã tích hợp sẵn trong Python)
+ # Không cần cài đặt thêm
+
+ # Cho PostgreSQL
+ pip install psycopg2-binary
+
+ # Cho MySQL
+ pip install mysql-connector-python
+
+ # Cho SQLAlchemy ORM
+ pip install sqlalchemy
+ ```
+
+2. Chạy các ví dụ:
+ ```bash
+ python sql_examples.py
+ ```
+
+### Cài Đặt C#
+
+Để chạy các ví dụ C#:
+
+1. Cài đặt các gói NuGet cần thiết:
+ ```bash
+ # Cho SQLite
+ dotnet add package Microsoft.Data.Sqlite
+
+ # Cho SQL Server
+ dotnet add package Microsoft.Data.SqlClient
+
+ # Cho MySQL
+ dotnet add package MySql.Data
+
+ # Cho PostgreSQL
+ dotnet add package Npgsql
+
+ # Cho Dapper ORM
+ dotnet add package Dapper
+ ```
+
+2. Biên dịch và chạy các ví dụ:
+ ```bash
+ dotnet build
+ dotnet run
+ ```
+
+## Ví Dụ Sử Dụng
+
+### Python SQLite Example
+
+```python
+import sqlite3
+from dotenv import load_dotenv
+import os
+
+# Load environment variables
+load_dotenv()
+
+# Get database path from environment variable
+db_path = os.environ.get("SQLITE_DB_PATH", ":memory:")
+
+# Connect to SQLite database
+conn = sqlite3.connect(db_path)
+cursor = conn.cursor()
+
+# Create a table
+cursor.execute('''
+CREATE TABLE IF NOT EXISTS users (
+ id INTEGER PRIMARY KEY,
+ name TEXT NOT NULL,
+ email TEXT UNIQUE NOT NULL
+)
+''')
+
+# Insert data
+cursor.execute('INSERT INTO users (name, email) VALUES (?, ?)',
+ ('John Doe', 'john@example.com'))
+conn.commit()
+
+# Query data
+cursor.execute('SELECT * FROM users')
+print(cursor.fetchall())
+
+# Close connection
+conn.close()
+```
+
+### C# SQLite Example
+
+```csharp
+using System;
+using Microsoft.Data.Sqlite;
+
+// Get connection string from environment variable
+string connectionString = Environment.GetEnvironmentVariable("SQLITE_CONNECTION_STRING")
+ ?? "Data Source=:memory:";
+
+using (var connection = new SqliteConnection(connectionString))
+{
+ connection.Open();
+
+ // Create a table
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ CREATE TABLE IF NOT EXISTS users (
+ id INTEGER PRIMARY KEY,
+ name TEXT NOT NULL,
+ email TEXT NOT NULL UNIQUE
+ )";
+ command.ExecuteNonQuery();
+ }
+
+ // Insert data
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ INSERT INTO users (name, email)
+ VALUES (@name, @email)";
+ command.Parameters.AddWithValue("@name", "Jane Smith");
+ command.Parameters.AddWithValue("@email", "jane@example.com");
+ command.ExecuteNonQuery();
+ }
+
+ // Query data
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = "SELECT * FROM users";
+ using (var reader = command.ExecuteReader())
+ {
+ while (reader.Read())
+ {
+ Console.WriteLine($"ID: {reader.GetInt32(0)}, Name: {reader.GetString(1)}, Email: {reader.GetString(2)}");
+ }
+ }
+ }
+}
+```
+
+## Các Phương Pháp Tốt Nhất về Bảo Mật
+
+1. Không bao giờ mã hóa cứng thông tin đăng nhập cơ sở dữ liệu trong mã nguồn của bạn
+2. Luôn sử dụng truy vấn có tham số để ngăn chặn SQL injection
+3. Lưu trữ chuỗi kết nối và thông tin đăng nhập trong biến môi trường hoặc hệ thống cấu hình bảo mật
+4. Áp dụng nguyên tắc đặc quyền tối thiểu cho người dùng cơ sở dữ liệu
+5. Mã hóa dữ liệu nhạy cảm trước khi lưu trữ trong cơ sở dữ liệu
+6. Thường xuyên cập nhật trình điều khiển và thư viện cơ sở dữ liệu để vá các lỗ hổng bảo mật
\ No newline at end of file
diff --git a/snippets/databases/relational_db_examples.cs b/snippets/databases/relational_db_examples.cs
new file mode 100644
index 0000000..062a3e6
--- /dev/null
+++ b/snippets/databases/relational_db_examples.cs
@@ -0,0 +1,829 @@
+using System;
+using System.Data;
+using System.Collections.Generic;
+using System.Threading.Tasks;
+// Requires NuGet packages:
+// Microsoft.Data.SqlClient
+// Microsoft.Data.Sqlite
+// MySql.Data
+// Npgsql
+// Dapper
+// Microsoft.Extensions.Configuration.EnvironmentVariables (for .NET environment variables)
+
+namespace RelationalDatabaseExamples
+{
+ ///
+ /// Examples of working with relational databases in C#
+ ///
+ class Program
+ {
+ // Configuration for environment variables
+ private static readonly EnvironmentVariableManager _env = new EnvironmentVariableManager();
+
+ static async Task Main(string[] args)
+ {
+ Console.WriteLine("C# Relational Database Examples");
+ Console.WriteLine("===============================");
+
+ try
+ {
+ // SQLite example (works without additional setup)
+ await SQLiteExample();
+
+ // The following examples require database servers to be running
+ // Uncomment them if you have the necessary databases set up
+
+ // await SqlServerExample();
+ // await MySqlExample();
+ // await PostgreSqlExample();
+ // await DapperExample();
+
+ Console.WriteLine("\nAll examples completed successfully.");
+ }
+ catch (Exception ex)
+ {
+ Console.WriteLine($"Error: {ex.Message}");
+ }
+ }
+
+ ///
+ /// Example using SQLite
+ ///
+ static async Task SQLiteExample()
+ {
+ Console.WriteLine("\n=== SQLite Example ===");
+
+ // Make sure you have the Microsoft.Data.Sqlite NuGet package installed
+ var connectionString = _env.GetValue("SQLITE_CONNECTION_STRING", "Data Source=:memory:");
+
+ using (var connection = new Microsoft.Data.Sqlite.SqliteConnection(connectionString))
+ {
+ await connection.OpenAsync();
+ Console.WriteLine("Connected to SQLite database");
+
+ // Create a table
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ CREATE TABLE Employees (
+ Id INTEGER PRIMARY KEY,
+ Name TEXT NOT NULL,
+ Department TEXT NOT NULL,
+ Salary REAL,
+ HireDate TEXT
+ )";
+ await command.ExecuteNonQueryAsync();
+ Console.WriteLine("Created Employees table");
+ }
+
+ // Insert data using parameters
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ INSERT INTO Employees (Name, Department, Salary, HireDate)
+ VALUES (@name, @department, @salary, @hireDate)";
+
+ command.Parameters.AddWithValue("@name", "John Smith");
+ command.Parameters.AddWithValue("@department", "Engineering");
+ command.Parameters.AddWithValue("@salary", 85000.00);
+ command.Parameters.AddWithValue("@hireDate", DateTime.Now.ToString("yyyy-MM-dd"));
+
+ await command.ExecuteNonQueryAsync();
+ Console.WriteLine("Inserted employee: John Smith");
+
+ // Insert another employee
+ command.Parameters.Clear();
+ command.Parameters.AddWithValue("@name", "Jane Doe");
+ command.Parameters.AddWithValue("@department", "Marketing");
+ command.Parameters.AddWithValue("@salary", 75000.00);
+ command.Parameters.AddWithValue("@hireDate", DateTime.Now.AddDays(-90).ToString("yyyy-MM-dd"));
+
+ await command.ExecuteNonQueryAsync();
+ Console.WriteLine("Inserted employee: Jane Doe");
+
+ // One more employee
+ command.Parameters.Clear();
+ command.Parameters.AddWithValue("@name", "Bob Johnson");
+ command.Parameters.AddWithValue("@department", "Engineering");
+ command.Parameters.AddWithValue("@salary", 82000.00);
+ command.Parameters.AddWithValue("@hireDate", DateTime.Now.AddDays(-180).ToString("yyyy-MM-dd"));
+
+ await command.ExecuteNonQueryAsync();
+ Console.WriteLine("Inserted employee: Bob Johnson");
+ }
+
+ // Query all employees
+ Console.WriteLine("\nAll employees:");
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = "SELECT Id, Name, Department, Salary FROM Employees";
+
+ using (var reader = await command.ExecuteReaderAsync())
+ {
+ while (await reader.ReadAsync())
+ {
+ Console.WriteLine($"ID: {reader.GetInt32(0)}, Name: {reader.GetString(1)}, " +
+ $"Department: {reader.GetString(2)}, Salary: ${reader.GetDouble(3):N2}");
+ }
+ }
+ }
+
+ // Filtered query with parameters
+ Console.WriteLine("\nEngineering department employees:");
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = "SELECT Name, Salary FROM Employees WHERE Department = @department";
+ command.Parameters.AddWithValue("@department", "Engineering");
+
+ using (var reader = await command.ExecuteReaderAsync())
+ {
+ while (await reader.ReadAsync())
+ {
+ Console.WriteLine($"{reader.GetString(0)}: ${reader.GetDouble(1):N2}");
+ }
+ }
+ }
+
+ // Aggregate query
+ Console.WriteLine("\nDepartment statistics:");
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ SELECT Department,
+ COUNT(*) as EmployeeCount,
+ AVG(Salary) as AvgSalary,
+ SUM(Salary) as TotalSalary
+ FROM Employees
+ GROUP BY Department";
+
+ using (var reader = await command.ExecuteReaderAsync())
+ {
+ while (await reader.ReadAsync())
+ {
+ Console.WriteLine($"{reader.GetString(0)}: " +
+ $"{reader.GetInt32(1)} employees, " +
+ $"Avg: ${reader.GetDouble(2):N2}, " +
+ $"Total: ${reader.GetDouble(3):N2}");
+ }
+ }
+ }
+
+ // Transaction example
+ await using (var transaction = connection.BeginTransaction())
+ {
+ try
+ {
+ // Update salary in a transaction
+ using (var command = connection.CreateCommand())
+ {
+ command.Transaction = transaction;
+ command.CommandText = "UPDATE Employees SET Salary = Salary * 1.1 WHERE Department = @department";
+ command.Parameters.AddWithValue("@department", "Engineering");
+
+ var rowsAffected = await command.ExecuteNonQueryAsync();
+ Console.WriteLine($"\nGave 10% raise to {rowsAffected} engineering employees");
+ }
+
+ // Verify the changes
+ using (var command = connection.CreateCommand())
+ {
+ command.Transaction = transaction;
+ command.CommandText = "SELECT Name, Salary FROM Employees WHERE Department = @department";
+ command.Parameters.AddWithValue("@department", "Engineering");
+
+ Console.WriteLine("Updated engineering salaries:");
+ using (var reader = await command.ExecuteReaderAsync())
+ {
+ while (await reader.ReadAsync())
+ {
+ Console.WriteLine($"{reader.GetString(0)}: ${reader.GetDouble(1):N2}");
+ }
+ }
+ }
+
+ // Commit the transaction
+ await transaction.CommitAsync();
+ Console.WriteLine("Transaction committed");
+ }
+ catch (Exception ex)
+ {
+ await transaction.RollbackAsync();
+ Console.WriteLine($"Transaction rolled back: {ex.Message}");
+ }
+ }
+ }
+ }
+
+ ///
+ /// Example using SQL Server
+ ///
+ static async Task SqlServerExample()
+ {
+ Console.WriteLine("\n=== SQL Server Example ===");
+ Console.WriteLine("To run this example, you need SQL Server and the Microsoft.Data.SqlClient NuGet package.");
+
+ // Connection string for SQL Server from environment variables
+ var connectionString = _env.GetValue("SQLSERVER_CONNECTION_STRING",
+ "Server=localhost;Database=TestDB;Trusted_Connection=True;");
+
+ Console.WriteLine($"Using connection info from environment: {GetSanitizedConnectionString(connectionString)}");
+
+ using (var connection = new Microsoft.Data.SqlClient.SqlConnection(connectionString))
+ {
+ await connection.OpenAsync();
+ Console.WriteLine("Connected to SQL Server");
+
+ // Create a table with SQL Server specific features
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ IF NOT EXISTS (SELECT * FROM sys.tables WHERE name = 'Products')
+ BEGIN
+ CREATE TABLE Products (
+ Id INT IDENTITY(1,1) PRIMARY KEY,
+ Name NVARCHAR(100) NOT NULL,
+ Description NVARCHAR(MAX),
+ Price DECIMAL(10,2) NOT NULL,
+ Category NVARCHAR(50),
+ CreatedAt DATETIME2 DEFAULT GETDATE(),
+ UpdatedAt DATETIME2,
+ IsActive BIT DEFAULT 1
+ );
+
+ CREATE INDEX IX_Products_Category ON Products(Category);
+ END";
+
+ await command.ExecuteNonQueryAsync();
+ Console.WriteLine("Created Products table");
+ }
+
+ // Insert with output parameter to get the identity value
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ INSERT INTO Products (Name, Description, Price, Category)
+ OUTPUT INSERTED.Id
+ VALUES (@name, @description, @price, @category)";
+
+ command.Parameters.AddWithValue("@name", "Laptop");
+ command.Parameters.AddWithValue("@description", "High-performance laptop");
+ command.Parameters.AddWithValue("@price", 1299.99);
+ command.Parameters.AddWithValue("@category", "Electronics");
+
+ var productId = (int)await command.ExecuteScalarAsync();
+ Console.WriteLine($"Inserted product with ID: {productId}");
+ }
+
+ // SQL Server specific features: CTE, ROW_NUMBER
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ WITH RankedProducts AS (
+ SELECT
+ Name,
+ Price,
+ Category,
+ ROW_NUMBER() OVER (PARTITION BY Category ORDER BY Price DESC) AS PriceRank
+ FROM
+ Products
+ )
+ SELECT Name, Price, Category, PriceRank
+ FROM RankedProducts
+ WHERE PriceRank <= 3";
+
+ using (var reader = await command.ExecuteReaderAsync())
+ {
+ Console.WriteLine("\nTop 3 most expensive products per category:");
+ while (await reader.ReadAsync())
+ {
+ Console.WriteLine($"{reader.GetString(0)} - ${reader.GetDecimal(1):N2} - " +
+ $"{reader.GetString(2)} (Rank: {reader.GetInt64(3)})");
+ }
+ }
+ }
+
+ // Using stored procedure
+ using (var command = connection.CreateCommand())
+ {
+ // First create the stored procedure
+ command.CommandText = @"
+ IF NOT EXISTS (SELECT * FROM sys.procedures WHERE name = 'GetProductsByCategory')
+ BEGIN
+ EXEC('
+ CREATE PROCEDURE GetProductsByCategory
+ @CategoryName NVARCHAR(50),
+ @MinPrice DECIMAL(10,2) = 0
+ AS
+ BEGIN
+ SELECT Id, Name, Price
+ FROM Products
+ WHERE Category = @CategoryName
+ AND Price >= @MinPrice
+ ORDER BY Price DESC;
+ END
+ ')
+ END";
+
+ await command.ExecuteNonQueryAsync();
+ Console.WriteLine("Created stored procedure");
+
+ // Use the stored procedure
+ command.CommandText = "GetProductsByCategory";
+ command.CommandType = CommandType.StoredProcedure;
+
+ command.Parameters.Clear();
+ command.Parameters.AddWithValue("@CategoryName", "Electronics");
+ command.Parameters.AddWithValue("@MinPrice", 500);
+
+ using (var reader = await command.ExecuteReaderAsync())
+ {
+ Console.WriteLine("\nElectronics products over $500:");
+ while (await reader.ReadAsync())
+ {
+ Console.WriteLine($"ID: {reader.GetInt32(0)}, Name: {reader.GetString(1)}, " +
+ $"Price: ${reader.GetDecimal(2):N2}");
+ }
+ }
+ }
+ }
+ }
+
+ ///
+ /// Example using MySQL
+ ///
+ static async Task MySqlExample()
+ {
+ Console.WriteLine("\n=== MySQL Example ===");
+ Console.WriteLine("To run this example, you need MySQL and the MySql.Data NuGet package.");
+
+ // Connection string for MySQL from environment variables
+ var connectionString = _env.GetValue("MYSQL_CONNECTION_STRING",
+ "Server=localhost;Database=testdb;Uid=root;Pwd=password;");
+
+ Console.WriteLine($"Using connection info from environment: {GetSanitizedConnectionString(connectionString)}");
+
+ using (var connection = new MySql.Data.MySqlClient.MySqlConnection(connectionString))
+ {
+ await connection.OpenAsync();
+ Console.WriteLine("Connected to MySQL");
+
+ // Create a table with MySQL specific features
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ CREATE TABLE IF NOT EXISTS Orders (
+ id INT AUTO_INCREMENT PRIMARY KEY,
+ customer_name VARCHAR(100) NOT NULL,
+ total DECIMAL(10,2) NOT NULL,
+ status ENUM('pending', 'shipped', 'delivered') NOT NULL,
+ created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
+ updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
+ INDEX idx_status (status),
+ INDEX idx_created_at (created_at)
+ ) ENGINE=InnoDB";
+
+ await command.ExecuteNonQueryAsync();
+ Console.WriteLine("Created Orders table");
+ }
+
+ // Insert with MySQL-specific AUTO_INCREMENT handling
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ INSERT INTO Orders (customer_name, total, status)
+ VALUES (@customerName, @total, @status)";
+
+ command.Parameters.AddWithValue("@customerName", "John Doe");
+ command.Parameters.AddWithValue("@total", 123.45);
+ command.Parameters.AddWithValue("@status", "pending");
+
+ await command.ExecuteNonQueryAsync();
+ Console.WriteLine($"Inserted order, ID: {command.LastInsertedId}");
+ }
+
+ // MySQL specific functions
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ SELECT
+ id,
+ customer_name,
+ total,
+ status,
+ DATE_FORMAT(created_at, '%Y-%m-%d %H:%i:%s') AS formatted_date,
+ DATEDIFF(NOW(), created_at) AS days_since_creation
+ FROM
+ Orders
+ WHERE
+ created_at > DATE_SUB(NOW(), INTERVAL 7 DAY)";
+
+ using (var reader = await command.ExecuteReaderAsync())
+ {
+ Console.WriteLine("\nRecent orders:");
+ while (await reader.ReadAsync())
+ {
+ Console.WriteLine($"ID: {reader.GetInt32(0)}, " +
+ $"Customer: {reader.GetString(1)}, " +
+ $"Total: ${reader.GetDecimal(2):N2}, " +
+ $"Status: {reader.GetString(3)}, " +
+ $"Created: {reader.GetString(4)} " +
+ $"({reader.GetInt32(5)} days ago)");
+ }
+ }
+ }
+ }
+ }
+
+ ///
+ /// Example using PostgreSQL
+ ///
+ static async Task PostgreSqlExample()
+ {
+ Console.WriteLine("\n=== PostgreSQL Example ===");
+ Console.WriteLine("To run this example, you need PostgreSQL and the Npgsql NuGet package.");
+
+ // Connection string for PostgreSQL from environment variables
+ var connectionString = _env.GetValue("POSTGRES_CONNECTION_STRING",
+ "Host=localhost;Database=testdb;Username=postgres;Password=password");
+
+ Console.WriteLine($"Using connection info from environment: {GetSanitizedConnectionString(connectionString)}");
+
+ using (var connection = new Npgsql.NpgsqlConnection(connectionString))
+ {
+ await connection.OpenAsync();
+ Console.WriteLine("Connected to PostgreSQL");
+
+ // Create a table with PostgreSQL-specific features
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ CREATE TABLE IF NOT EXISTS products (
+ id SERIAL PRIMARY KEY,
+ name VARCHAR(100) NOT NULL,
+ description TEXT,
+ price DECIMAL(10,2) NOT NULL,
+ created_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP,
+ tags TEXT[],
+ metadata JSONB
+ )";
+
+ await command.ExecuteNonQueryAsync();
+ Console.WriteLine("Created products table");
+ }
+
+ // Insert with PostgreSQL-specific data types
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ INSERT INTO products (name, description, price, tags, metadata)
+ VALUES (@name, @description, @price, @tags, @metadata)
+ RETURNING id";
+
+ command.Parameters.AddWithValue("@name", "Laptop");
+ command.Parameters.AddWithValue("@description", "High-performance laptop");
+ command.Parameters.AddWithValue("@price", 999.99);
+ command.Parameters.AddWithValue("@tags", new string[] { "electronics", "computers" });
+ command.Parameters.AddWithValue("@metadata", "{""brand"": ""TechBrand"", ""warranty"": ""2 years"", ""specs"": {""cpu"": ""i7"", ""ram"": ""16GB""}}");
+
+ var productId = (int)await command.ExecuteScalarAsync();
+ Console.WriteLine($"Inserted product with ID: {productId}");
+ }
+
+ // PostgreSQL-specific features: JSONB, arrays
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = @"
+ SELECT
+ name,
+ price,
+ metadata->>'brand' AS brand,
+ metadata->'specs'->>'cpu' AS cpu,
+ array_length(tags, 1) AS tag_count,
+ extract(year from created_at) AS year
+ FROM
+ products
+ WHERE
+ 'electronics' = ANY(tags)";
+
+ using (var reader = await command.ExecuteReaderAsync())
+ {
+ Console.WriteLine("\nElectronics products:");
+ while (await reader.ReadAsync())
+ {
+ Console.WriteLine($"{reader.GetString(0)} - ${reader.GetDecimal(1):N2} - " +
+ $"Brand: {reader.GetString(2)}, CPU: {reader.GetString(3)}, " +
+ $"Tag count: {reader.GetInt32(4)}, Year: {reader.GetDouble(5)}");
+ }
+ }
+ }
+ }
+ }
+
+ ///
+ /// Example using Dapper micro-ORM
+ ///
+ static async Task DapperExample()
+ {
+ Console.WriteLine("\n=== Dapper Example ===");
+ Console.WriteLine("To run this example, you need the Dapper NuGet package and a database connection.");
+
+ // Connection string from environment variables
+ var connectionString = _env.GetValue("DAPPER_CONNECTION_STRING", "Data Source=:memory:");
+
+ using (var connection = new Microsoft.Data.Sqlite.SqliteConnection(connectionString))
+ {
+ await connection.OpenAsync();
+ Console.WriteLine("Connected to SQLite for Dapper example");
+
+ // Set up database
+ await connection.ExecuteAsync(@"
+ CREATE TABLE Customers (
+ Id INTEGER PRIMARY KEY,
+ Name TEXT NOT NULL,
+ Email TEXT NOT NULL
+ );
+
+ CREATE TABLE Orders (
+ Id INTEGER PRIMARY KEY,
+ CustomerId INTEGER NOT NULL,
+ Amount REAL NOT NULL,
+ OrderDate TEXT NOT NULL,
+ FOREIGN KEY (CustomerId) REFERENCES Customers (Id)
+ );
+
+ CREATE TABLE OrderItems (
+ Id INTEGER PRIMARY KEY,
+ OrderId INTEGER NOT NULL,
+ ProductName TEXT NOT NULL,
+ Quantity INTEGER NOT NULL,
+ UnitPrice REAL NOT NULL,
+ FOREIGN KEY (OrderId) REFERENCES Orders (Id)
+ );
+ ");
+
+ // Insert customers
+ var customerIds = await connection.ExecuteAsync(@"
+ INSERT INTO Customers (Name, Email) VALUES
+ (@Name, @Email)",
+ new[] {
+ new { Name = "Alice Smith", Email = "alice@example.com" },
+ new { Name = "Bob Jones", Email = "bob@example.com" }
+ });
+
+ Console.WriteLine($"Inserted {customerIds} customers");
+
+ // Insert orders
+ var orderDate = DateTime.Now;
+ var order1Id = await connection.QuerySingleAsync(@"
+ INSERT INTO Orders (CustomerId, Amount, OrderDate)
+ VALUES (@CustomerId, @Amount, @OrderDate)
+ RETURNING Id",
+ new { CustomerId = 1, Amount = 125.50, OrderDate = orderDate.ToString("yyyy-MM-dd") });
+
+ // Insert order items
+ await connection.ExecuteAsync(@"
+ INSERT INTO OrderItems (OrderId, ProductName, Quantity, UnitPrice)
+ VALUES (@OrderId, @ProductName, @Quantity, @UnitPrice)",
+ new[] {
+ new { OrderId = order1Id, ProductName = "Keyboard", Quantity = 1, UnitPrice = 75.50 },
+ new { OrderId = order1Id, ProductName = "Mouse", Quantity = 1, UnitPrice = 50.00 }
+ });
+
+ // Query with Dapper
+ var customers = await connection.QueryAsync("SELECT * FROM Customers");
+
+ Console.WriteLine("\nAll customers:");
+ foreach (var customer in customers)
+ {
+ Console.WriteLine($"ID: {customer.Id}, Name: {customer.Name}, Email: {customer.Email}");
+ }
+
+ // Query with join and multi-mapping
+ Console.WriteLine("\nOrders with customer info:");
+ var orders = await connection.QueryAsync(
+ @"SELECT o.Id, o.Amount, o.OrderDate, c.Id, c.Name, c.Email
+ FROM Orders o
+ JOIN Customers c ON o.CustomerId = c.Id",
+ (order, customer) => {
+ order.Customer = customer;
+ return order;
+ },
+ splitOn: "Id"
+ );
+
+ foreach (var order in orders)
+ {
+ Console.WriteLine($"Order #{order.Id} - ${order.Amount:N2} on {order.OrderDate} " +
+ $"by {order.Customer.Name} ({order.Customer.Email})");
+ }
+
+ // Query order details with complex mapping
+ Console.WriteLine("\nOrder details:");
+ var orderWithItems = await connection.QueryAsync(
+ @"SELECT o.Id, o.Amount, o.OrderDate, i.Id, i.ProductName, i.Quantity, i.UnitPrice
+ FROM Orders o
+ JOIN OrderItems i ON o.Id = i.OrderId
+ WHERE o.Id = @OrderId",
+ (order, item) => {
+ if (order.Items == null)
+ order.Items = new List();
+ order.Items.Add(item);
+ return order;
+ },
+ new { OrderId = order1Id },
+ splitOn: "Id"
+ );
+
+ var orderDetail = orderWithItems.GroupBy(o => o.Id).Select(g => {
+ var order = g.First();
+ order.Items = g.Select(o => o.Items.Single()).ToList();
+ return order;
+ }).First();
+
+ Console.WriteLine($"Order #{orderDetail.Id} - ${orderDetail.Amount:N2} on {orderDetail.OrderDate}");
+ foreach (var item in orderDetail.Items)
+ {
+ Console.WriteLine($" {item.ProductName}: {item.Quantity} x ${item.UnitPrice:N2} = ${item.Quantity * item.UnitPrice:N2}");
+ }
+
+ // Execute scalar
+ var totalSales = await connection.ExecuteScalarAsync(
+ "SELECT SUM(Amount) FROM Orders");
+
+ Console.WriteLine($"\nTotal sales: ${totalSales:N2}");
+ }
+ }
+
+ ///
+ /// Sanitizes a connection string by hiding the password
+ ///
+ private static string GetSanitizedConnectionString(string connectionString)
+ {
+ // Simple sanitization to hide password/credentials
+ if (string.IsNullOrEmpty(connectionString))
+ return connectionString;
+
+ // Handle different formats for different database providers
+ return connectionString
+ .Replace(GetPasswordPart(connectionString, "Password="), "Password=*****")
+ .Replace(GetPasswordPart(connectionString, "Pwd="), "Pwd=*****")
+ .Replace(GetPasswordPart(connectionString, "password="), "password=*****");
+ }
+
+ private static string GetPasswordPart(string connectionString, string passwordPrefix)
+ {
+ int pwdIndex = connectionString.IndexOf(passwordPrefix, StringComparison.OrdinalIgnoreCase);
+ if (pwdIndex < 0)
+ return string.Empty;
+
+ int startIndex = pwdIndex + passwordPrefix.Length;
+ int endIndex = connectionString.IndexOf(';', startIndex);
+ if (endIndex < 0)
+ endIndex = connectionString.Length;
+
+ return connectionString.Substring(pwdIndex, endIndex - pwdIndex);
+ }
+
+ // Model classes for Dapper example
+ public class Customer
+ {
+ public int Id { get; set; }
+ public string Name { get; set; }
+ public string Email { get; set; }
+ public List Orders { get; set; }
+ }
+
+ public class Order
+ {
+ public int Id { get; set; }
+ public int CustomerId { get; set; }
+ public double Amount { get; set; }
+ public string OrderDate { get; set; }
+ public Customer Customer { get; set; }
+ public List Items { get; set; }
+ }
+
+ public class OrderItem
+ {
+ public int Id { get; set; }
+ public int OrderId { get; set; }
+ public string ProductName { get; set; }
+ public int Quantity { get; set; }
+ public double UnitPrice { get; set; }
+ }
+ }
+
+ ///
+ /// Helper class to manage environment variables with fallback values
+ ///
+ public class EnvironmentVariableManager
+ {
+ ///
+ /// Gets a value from environment variables with a fallback default
+ ///
+ public string GetValue(string key, string defaultValue)
+ {
+ var value = Environment.GetEnvironmentVariable(key);
+ return string.IsNullOrWhiteSpace(value) ? defaultValue : value;
+ }
+ }
+}
+
+// Extensions method for Dapper (to simulate Dapper behavior)
+public static class DapperExtensions
+{
+ public static Task ExecuteAsync(this IDbConnection connection, string sql, object param = null)
+ {
+ // Simplified for the example
+ using (var command = connection.CreateCommand())
+ {
+ command.CommandText = sql;
+ if (param is IEnumerable